How to Scrape TripAdvisor using Smart Proxy.

This blog is originally posted to the crawlbase blog.
TripAdvisor, being one of the largest travel websites with a vast amount of user-generated content, provides a wealth of data that can be valuable for market research, competitive analysis, and other purposes.
Founded in the year 2000, TripAdvisor has revolutionized the way people plan their trips by providing a platform where travelers can share their experiences and insights. People can not only read reviews and ratings but also view photos uploaded by other users to get a real sense of what to expect. What started as a humble website has now grown into a global community of millions of users who contribute to the vast database of travel-related content.
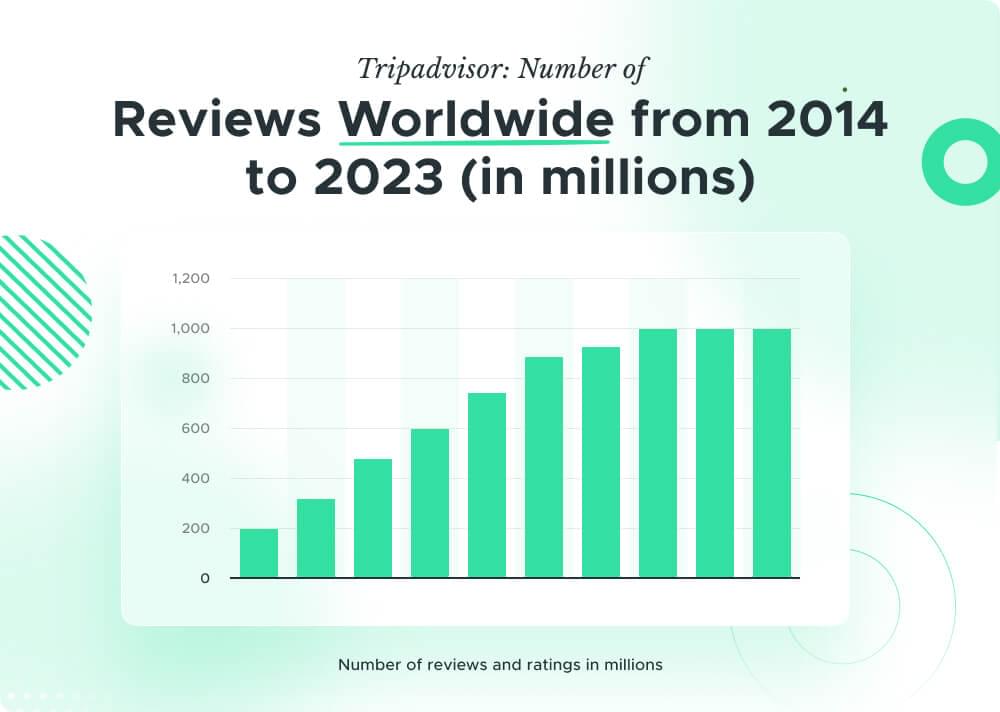
TripAdvisor.com attracts millions of visitors monthly, cementing its position as one of the most visited travel platforms globally. With an extensive database of nearly 1000 million reviews and opinions, the platform offers a vast pool of information for travelers and diners seeking insights into destinations and establishments. The sheer volume of data underscores TripAdvisor’s status as a go-to resource for making informed decisions.
In this article, we will explore the benefits of scraping TripAdvisor and how you can accomplish it using Python programming language and Smart Proxies.
Table Of Contents
Installing Python and Libraries
Choosing an IDE
Sending Requests with Crawlbase Smart Proxy
Using Crawling API Parameters with Smart Proxy
Handling JavaScript-Intensive Pages
Scraping Name
Scraping Rating
Scraping Reviews Count
Scraping Location
Scraping Data from all Search Results
Handling Pagination
Saving Scraped Data into an Excel file
1. Why Scrape TripAdvisor?
There are multiple reasons why scraping data from TripAdvisor can be advantageous. Firstly, TripAdvisor offers a massive amount of information about hotels, restaurants, attractions, and more. By scraping this data, you can gain insights into customer reviews, ratings, and other relevant details that can help you make more informed decisions for your business or personal needs.
Scraping TripAdvisor can also be useful for conducting market research. By analyzing trends in user reviews and ratings, you can identify popular travel destinations, understand customer preferences, and tailor your business strategy accordingly. Additionally, scraping TripAdvisor can assist in competitive analysis by providing a comprehensive overview of your competitors’ performance and customer feedback.
Moreover, scraping TripAdvisor can be a valuable tool for monitoring your own business’s online reputation. By tracking reviews and ratings over time, you can gauge customer satisfaction levels, address any negative feedback promptly, and capitalize on positive reviews to enhance your brand image. This data can also be used to measure the effectiveness of your marketing campaigns and customer service initiatives, allowing you to make data-driven decisions to improve customer experience.
Furthermore, scraping TripAdvisor can uncover hidden insights that may not be readily apparent. By delving into the nuances of user-generated content, you can discover emerging trends, customer sentiments, and areas for improvement that can give you a competitive edge in the market. This detailed analysis can provide valuable intelligence for strategic planning and decision-making within your organization.
2. Key Data Available on TripAdvisor

TripAdvisor provides a wealth of information that goes beyond just hotel details. In addition to hotel names, addresses, ratings, reviews, photos, amenities, and pricing, the platform also offers valuable insights into the world of travel. TripAdvisor also offers data on restaurants, attractions, and flights, allowing you to gather insights about popular dining spots, must-visit tourist attractions, and flight options. From user-generated content like travel guides, forums, and travel blogs to real-time updates on travel restrictions and safety measures, TripAdvisor is a one-stop hub for all things travel-related.
3. Challenges in Scraping TripAdvisor
While scraping TripAdvisor can be highly beneficial, there are various challenges associated with the process.
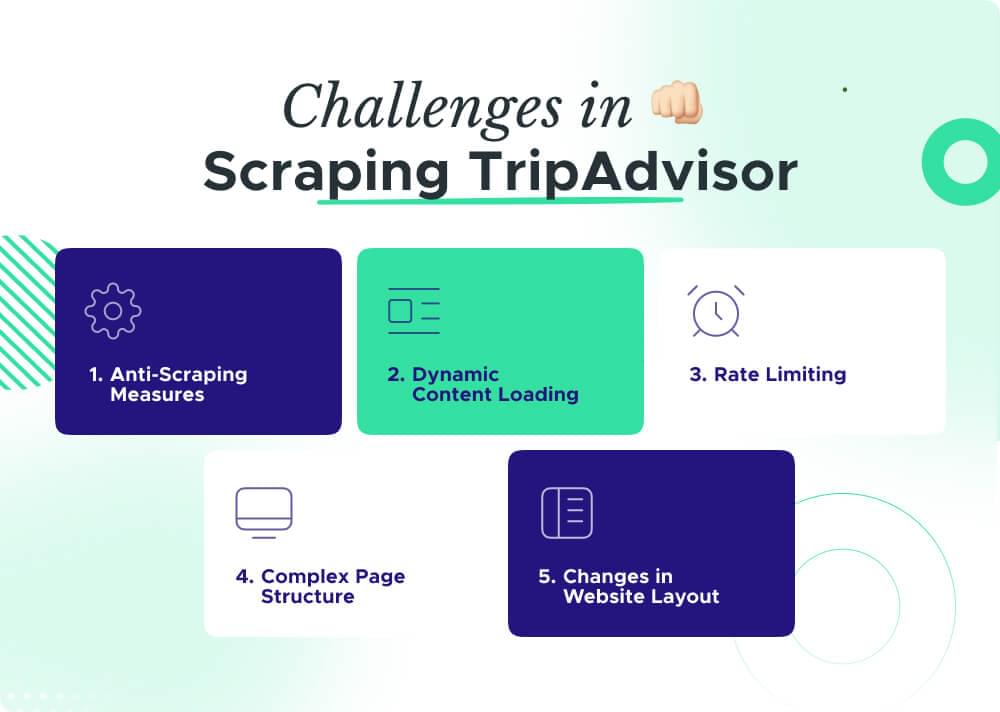
Anti-Scraping Measures
TripAdvisor employs protective measures to prevent automated scraping, making it tricky for traditional methods. Smart Proxies like Crawlbase help bypass these defenses, ensuring smooth data extraction.
Dynamic Content Loading
TripAdvisor often loads its content dynamically using JavaScript, making it challenging to capture all the information. Employing a Smart Proxy with JavaScript rendering capabilities is essential for a complete and accurate scrape.
Rate Limiting
To avoid server overload, TripAdvisor may implement rate limiting, restricting the number of requests. Smart Proxies can help manage this by providing a pool of IP addresses, preventing your scraping activities from being blocked.
Complex Page Structure
The structure of TripAdvisor pages can be intricate, leading to difficulties in locating and extracting specific data points. Crafting precise scraping scripts and using Smart Proxies aids in navigating these complexities.
Changes in Website Layout
TripAdvisor periodically updates its website layout, potentially breaking existing scraping scripts. Regular monitoring and adaptation of your scripts, along with the agility of Smart Proxies, ensure uninterrupted data retrieval.
To overcome these challenges, we can use use proxies equipped with features like JavaScript rendering and IP rotation. Adjusting scraping strategies, employing rate-limiting tactics, and keeping an eye on any updates to the website will help make your scraping on TripAdvisor work well for a long time.
4. Proxies for Scraping TripAdvisor
A key aspect of successful and efficient scraping is using proxies, especially when dealing with large-scale scraping projects like TripAdvisor. Proxies act as intermediaries between your scraping tool and the target website, masking your IP address and providing you the ability to make multiple requests without arousing suspicion.
Smart proxies, in particular, offer advanced features that enhance the scraping experience. These proxies can rotate IP addresses, distribute requests across different IP locations, and provide a higher level of anonymity. By rotating IP addresses, you can avoid IP bans and access blocked websites, ensuring uninterrupted scraping operations.
When selecting proxies for scraping TripAdvisor, it’s essential to consider factors such as speed, location diversity, and up-time. One of the best proxy providers available in the market today is Crawlbase. Crawlbase Smart Proxy consist of massive pool of data-center and residential proxies worldwide are optimized for maximum efficiency with fast multi-threaded operations.
5. Environment Setup
Before we dive into scraping Realtor.com, let’s set up our project to make sure we have everything we need. We’ll keep it simple by using the requests, beautifulsoup4 and pandas libraries for scraping.
Installing Python and Libraries
Python Installation:
If Python isn’t on your system yet, head over to python.org, grab the latest version, and follow the installation steps.
While installing, don’t forget to tick the “Add Python to PATH” box for hassle-free Python command line access.
Libraries Installation:
Open your command prompt or terminal.
Type the following commands to install the necessary libraries:
pip install requests |
- This will install requests for handling web requests, beautifulsoup4 for parsing HTML and pandas is for organizing and manipulating data.
Choosing an IDE
With Python and the necessary libraries successfully installed, let’s enhance our coding journey by selecting an Integrated Development Environment (IDE). An IDE is a software application that offers a complete set of tools to streamline the coding process.
Popular IDEs:
There are various IDEs available, and some popular ones for Python are:
Visual Studio Code: Visual Studio Code is lightweight and user-friendly, great for beginners.
PyCharm: PyCharm is feature-rich and widely used in professional settings.
Jupyter Notebooks: Jupyter Notebooks are excellent for interactive and exploratory coding.
Installation:
Download and install your chosen IDE from the provided links.
Follow the installation instructions for your operating system.
Now that our project is set up, we’re ready to start scraping TripAdvisor. In the next section, we’ll learn about Crawlbase Smart Proxy before using it for scraping TripAdvisor.
6. Crawlbase Smart Proxy
Scraping TripAdvisor demands a smart approach, and Crawlbase Smart Proxy is your key ally in overcoming obstacles and enhancing your scraping capabilities. Let’s explore the key functionalities that make it an invaluable asset in the world of web scraping.
Sending Requests with Crawlbase Smart Proxy
Executing requests through Crawlbase Smart Proxy is a breeze. You need an Below is a simple Python script showcasing how to make a GET request using this intelligent proxy.
import requests |
This script configures the Smart Proxy URL, defines the target URL, and utilizes the requests library to execute the GET request. It’s a fundamental step in harnessing the power of Crawlbase Smart Proxy.
Using Crawling API Parameters with Smart Proxy
Crawlbase Smart Proxy allows you to fine-tune your scraping requests using Crawling API parameters. This level of customization enhances your ability to extract specific data efficiently. Let’s see how you can integrate these parameters:
import requests |
In the example above, we use the country parameter with the value ‘US’ to geolocate our request for the United States.
Handling JavaScript-Intensive Pages
TripAdvisor, like many modern websites, heavily relies on JavaScript for content loading. Crawlbase Smart Proxy offers support for JavaScript-enabled headless browsers, ensuring that your scraper can access dynamically generated content. Activate this feature by using javascript parameter like below:
import requests |
By incorporating Crawlbase Smart Proxy with JavaScript rendering enabled, your scraper gains the ability to capture meaningful data from TripAdvisor, even on JavaScript-intensive pages.
In the next sections, we’ll delve into using these features in practical scenarios, scraping TripAdvisor SERP data effectively.
7. Scraping TripAdvisor SERP Data
Scraping valuable information from TripAdvisor Search Engine Results Pages (SERP) requires precision. Let’s break down how to scrape crucial details like Name, Rating, Reviews, and Location from all search results using Crawlbase Smart Proxy with JavaScript rendering enabled.
In our example, let’s focus on scraping data related to search query “London”.
Import Libraries
To begin our TripAdvisor scraping adventure, let’s import the necessary libraries. We’ll need requests for making HTTP requests and BeautifulSoup for parsing the HTML.
import requests |
These libraries will help us make requests, handle JSON responses, and parse HTML content with ease.
Fetching TripAdvisor Page HTML
First, let’s retrieve the HTML content of a TripAdvisor page using Crawlbase Smart Proxy with JavaScript rendering enabled. We will also utilize the page_wait parameter with a value of 5000 to introduce a 5-second delay before capturing HTML. This additional wait ensures that all JavaScript rendering is completed.
# Set up Smart Proxy URL with your access token |
Scraping TripAdvisor Search Listing
To obtain the search results, we initially need to identify the CSS selector that allows us to target all the search results. Subsequently, we can iterate through them in a loop to extract various details.
Simply use your web browser’s developer tools to explore and locate the CSS selector. Go to the webpage, right-click, and choose the Inspect option.
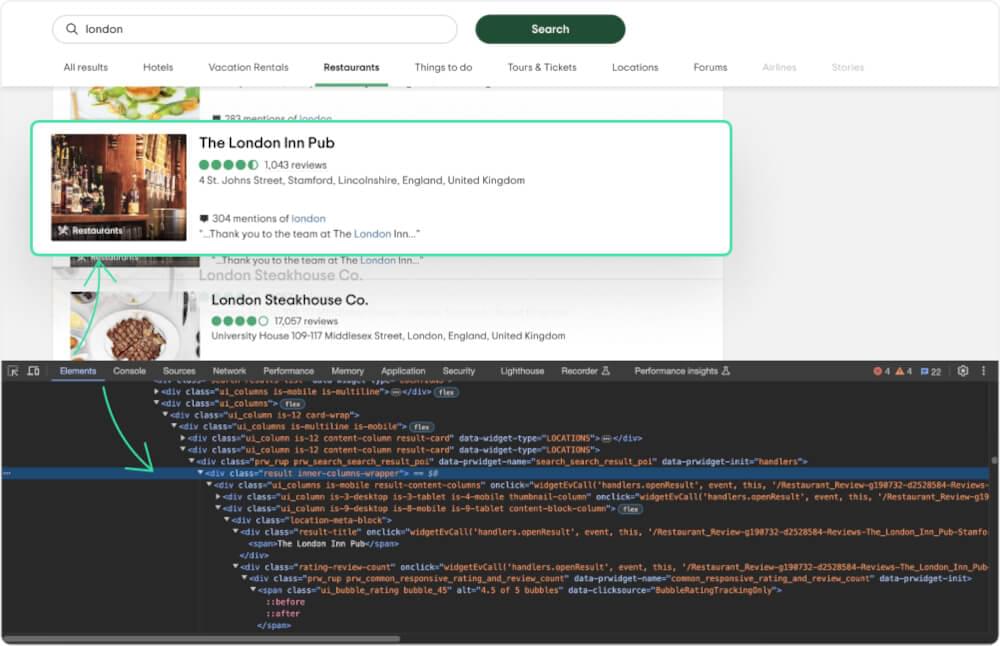
Every result is in a div with a class result. To only get search results list, we can use div with class search-results-list and data-widget-type as LOCATIONS. We’ll use BeautifulSoup to parse the HTML and locate the relevant elements using found selectors.
# Parse HTML using BeautifulSoup |
Scraping TripAdvisor Name
Let’s focus on extracting the names of the places listed in the search results.
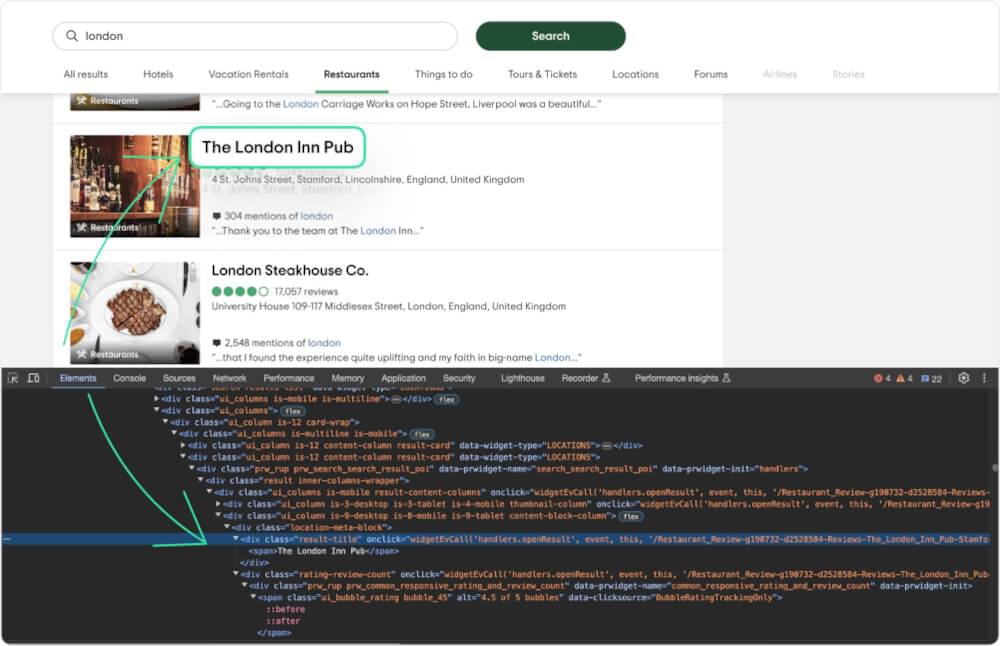
When you inspect a name, you’ll see it’s enclosed in <span> within the <div> having the class result-title.
# Selecting name element |
Scraping TripAdvisor Ratings
Next, let’s grab the ratings of these places.
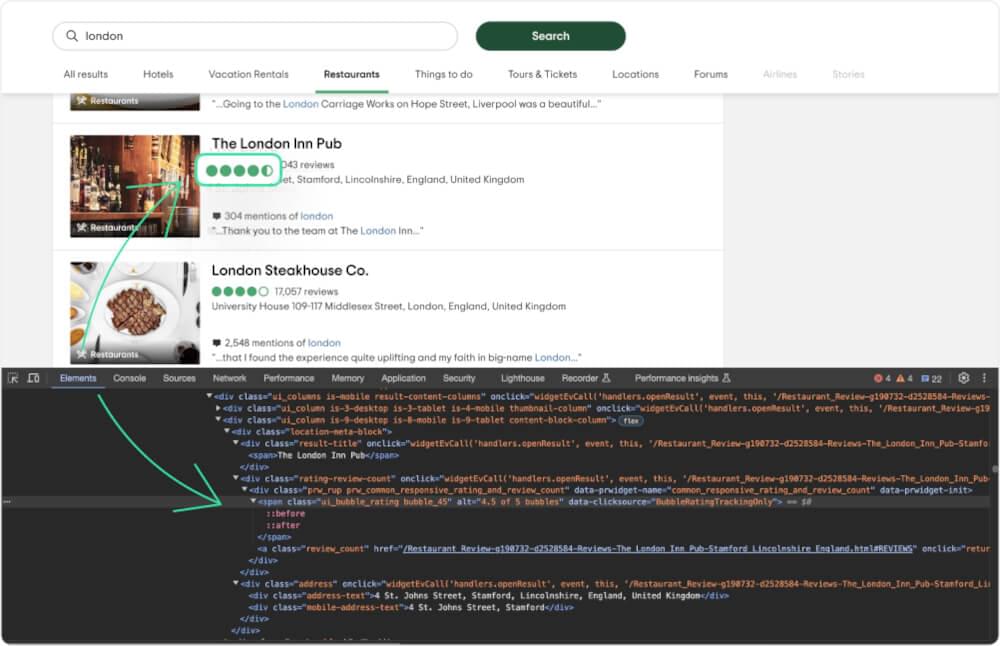
The <span> part possesses a class called ui_bubble_rating, and the rating can be found in the alt attribute. We can fetch the rating as below.
# Selecting rating element |
Scraping TripAdvisor Reviews Count
Now, let’s scrape the number of reviews each place has received.
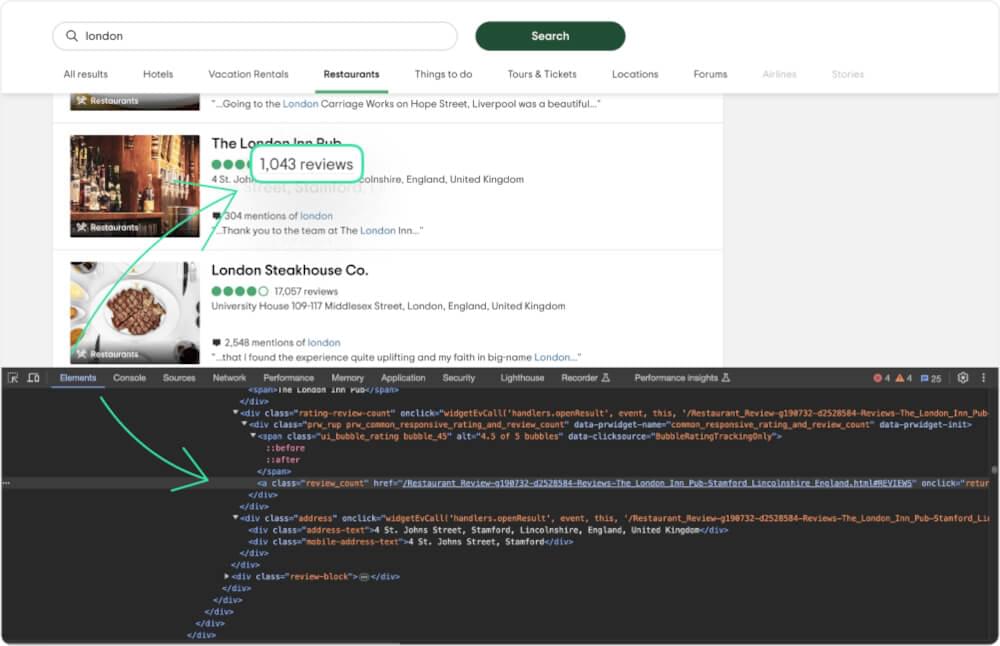
You can get reviews count from the <a> tag with the class review_count.
# Selecting reviews element |
Scraping TripAdvisor Location
Finally, let’s get the location details.
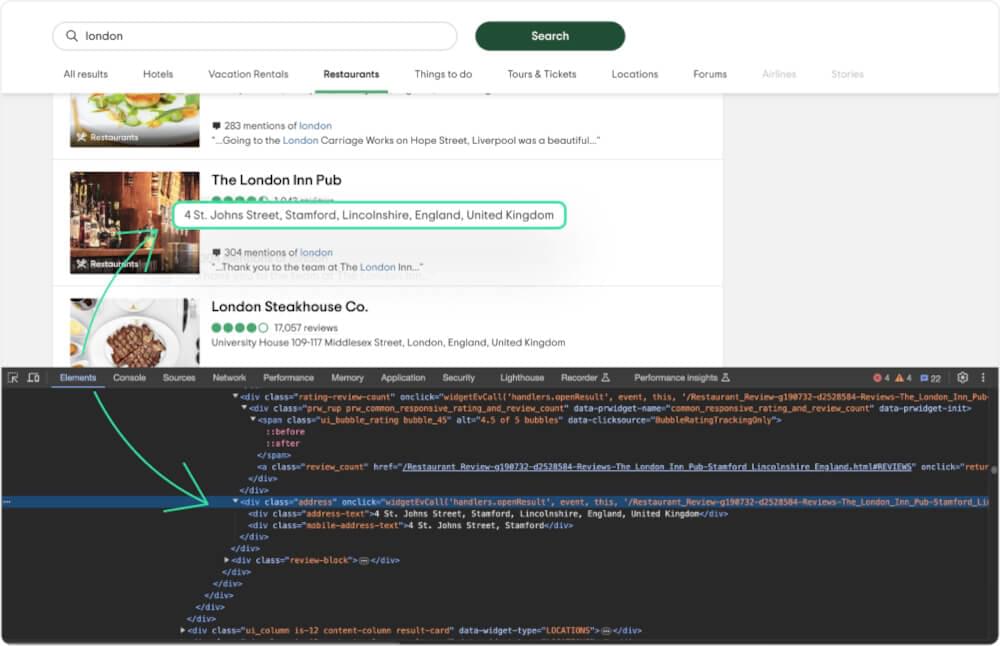
location can be found in a div with class address-text.
# Selecting location element |
Complete Code
Here’s the complete code integrating all the steps. This script also print the results after scraping them on the terminal in json format:
import requests |
Example Output:
[ |
8. Handling Pagination and Saving Data
When scraping TripAdvisor, dealing with pagination is crucial to gather comprehensive data. Additionally, it’s essential to save the scraped data efficiently. Let’s explore how to handle pagination and store the results in an Excel file.
Handling Pagination
TripAdvisor employs the “&o” parameter to manage pagination, ensuring that each page displays a distinct set of results. To scrape multiple pages, we can adjust the parameter value.
import requests |
Saving Scraped Data into an Excel File
Now, let’s save the collected data into an Excel file for easy analysis and sharing.
# Extending the previous script |
This code uses the pandas library to convert the scraped results into a DataFrame and then saves it to an Excel file named tripadvisor_scraped_data.xlsx.
tripadvisor_scraped_data.xlsx Snapshot:
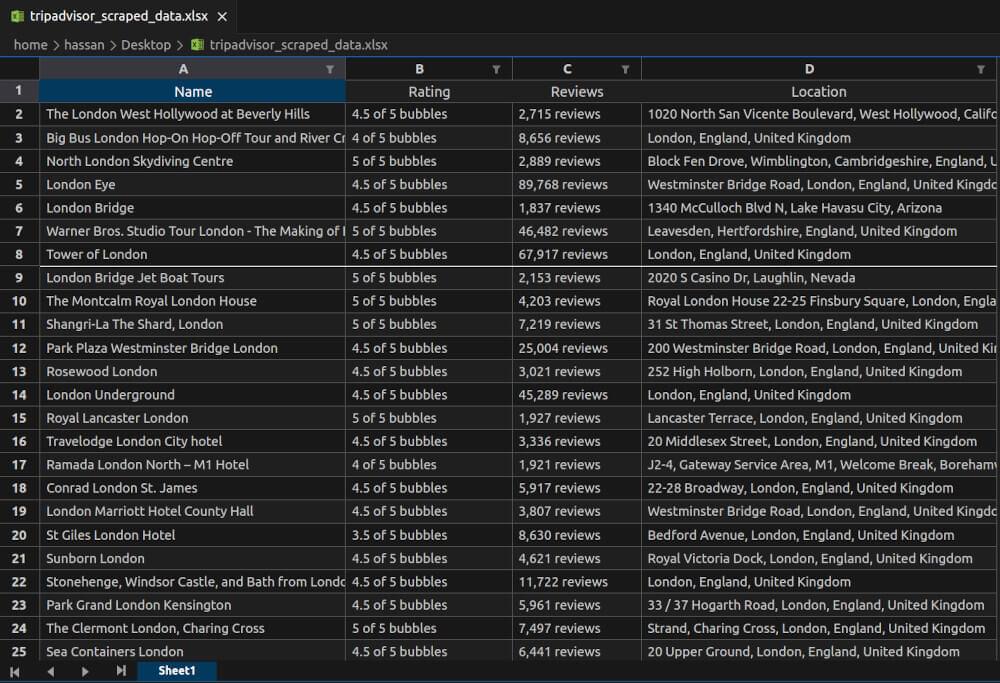
By incorporating these techniques, you can systematically scrape and store TripAdvisor data across multiple pages.
9. Final Thoughts
Scraping TripAdvisor with the assistance of Crawlbase Smart Proxy opens up a world of possibilities for data enthusiasts. Overcoming challenges like anti-scraping measures and dynamic content loading becomes achievable with the right tools. Crawlbase Smart Proxy enables you to seamlessly send IP-rotated requests and navigate through JavaScript-intensive pages.
If you want to read more about using proxies while scraping websites, check out our following guides:
📜 Scraping Instagram with Smart Proxy
📜 Scraping Walmart using Selenium & Smart Proxy
📜 Scraping Amazon ASIN with Smart Proxy
📜 Scraping AliExpress using Smart Proxy
If you ever need help or get stuck, the friendly Crawlbase support team is here to lend a hand. Happy scraping!
10. Frequently Asked Questions (FAQs)
Q. Is it legal to scrape TripAdvisor?
You can freely scrape public data, including TripAdvisor. However, It is crucial to thoroughly review TripAdvisor’s terms, ensuring compliance with their policies and also checking local laws. Additionally, respect the guidelines outlined in the TripAdvisor website’s robots.txt file, as it communicates which sections should not be crawled or scraped. Proceeding with caution and adhering to legal guidelines is essential to navigate this aspect responsibly.
Q. How can I Handle Dynamic Content Loading on TripAdvisor?
Handling dynamic content on TripAdvisor involves leveraging tools like Crawlbase Smart Proxy. Enabling JavaScript rendering with this tool becomes crucial in ensuring that dynamic elements on the page fully load. This functionality is pivotal because TripAdvisor often uses JavaScript to dynamically load content, and without it, essential information might be missed. By employing Crawlbase Smart Proxy, you enhance your scraping capabilities, making your data extraction more comprehensive and accurate.
Q. Is it Possible to Scrape Multiple Pages of TripAdvisor Search Results?
Absolutely! Scraping multiple pages of TripAdvisor search results is entirely feasible. This involves implementing effective pagination strategies within your scraping script. With systematic navigation through different pages, you can capture a more extensive dataset, ensuring that you don’t miss valuable information scattered across various result pages.
Q. Is it necessary to update scraping scripts when TripAdvisor changes its website layout?
Yes, regular updates to scraping scripts are imperative. TripAdvisor, like many websites, may undergo changes in its layout over time. These modifications can impact the functionality of existing scraping scripts. By keeping your scripts up-to-date and remaining vigilant for any alterations, you ensure a more reliable and uninterrupted scraping process. Being proactive and responsive to alterations is key to sustaining optimal scraping results.
Q. Does TripAdvisor allow web scraping?
No, TripAdvisor doesn’t allow web scraping but it is legal to scrape publicly available data like Names, addresses, Reviews. location and more using a dedicated proxies like Crawlbase Smart Proxy.




