How to Bypass CAPTCHAs in Web Scraping 2024

This blog is originally posted to the crawlbase blog.
Bypassing CAPTCHAs in Web Scraping
CAPTCHAs can be a major roadblock, frustrating even the most experienced developers and marketers. In this article, we’ll show you how to bypass CAPTCHAs and get the data you need without the hassle.
For web scrapers, CAPTCHAs pose a significant challenge especially with the advancement in CAPTCHAs and ethical considerations. They can slow down the scraping process, disrupt the automated workflow, and even block access to the desired data altogether. As a result, developers and marketers often find themselves spending valuable time and resources trying to overcome these obstacles.
CAPTCHAs can be time-consuming and hinder your scraping efforts. So, if you want to learn how to unblock websites and beat these pesky security measures to streamline your web scraping process, these are the ways you can use to bypass CAPTCHAs easily:
CAPTCHA Solver
Smart Proxy
OCR
Machine Learning Algorithms
Headless Browsers
Avoid Hidden Traps
Mimic Human behavior
Save cookies
Hide Automation Indicators
Building delays and timeouts
Later on in this article, we’ll explore all the different ways to get around captchas. But first, let’s take a friendly look at what captchas are and the common types you might encounter.
What are CAPTCHAs?
Defined as “Completely Automated Public Turing test to tell Computers and Humans Apart”, CAPTCHAs are security mechanisms designed to distinguish between human website visitors and automated bots. They serve as a gatekeeper to protect websites from malicious activities by verifying the user’s identity. CAPTCHAs typically involve presenting users with challenge tests that are easy for humans to solve but difficult for machines. These tests often consist of distorted characters, images, or puzzles that require human-like cognitive abilities to solve.

The primary goal of CAPTCHAs is to prevent malicious activities such as spamming, data scraping, and brute-force attacks. By introducing tests that only humans can solve, websites can ensure that the information they provide is accessed and utilized by genuine users, while simultaneously discouraging automated bots. By requiring users to successfully complete these challenges, websites can ensure that the entity accessing their content is indeed a human and not an automated script.
Types of CAPTCHAs
There are various types of CAPTCHAs that websites utilize to protect their data. Some common types include:
Text-based CAPTCHAs
These CAPTCHAs present users with distorted or obfuscated characters that need to be entered correctly. They often include additional challenges like warped letters or overlapping characters.

Image-based CAPTCHAs
These CAPTCHAs require users to identify specific objects or patterns within an image. They may involve selecting images with specific objects, selecting portions of an image, or solving puzzles related to image content.
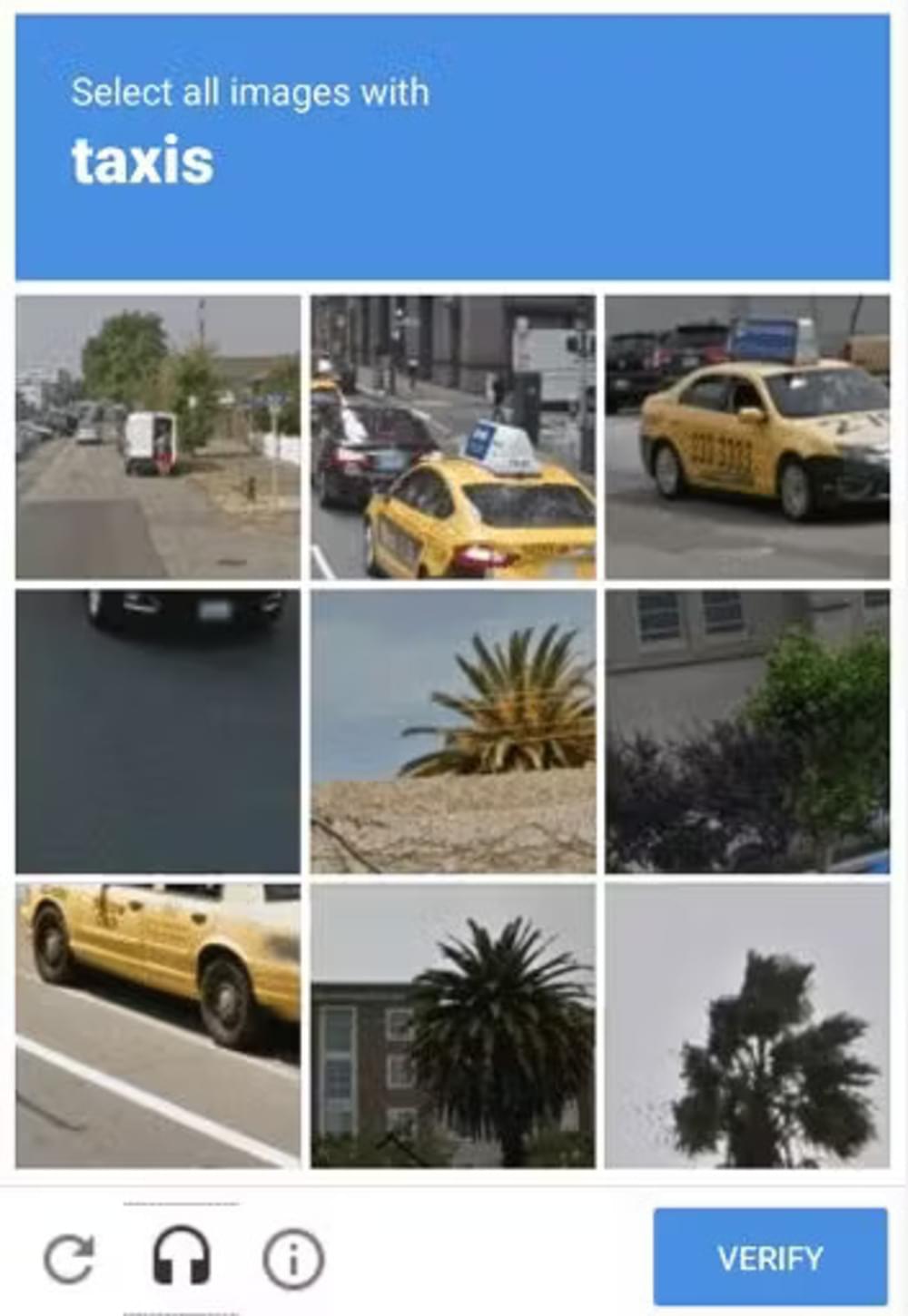
Checkbox CAPTCHAs
These CAPTCHAs require users to check a box to confirm their human status. While they are less obtrusive, they still provide a level of security by differentiating between human and automated interaction.
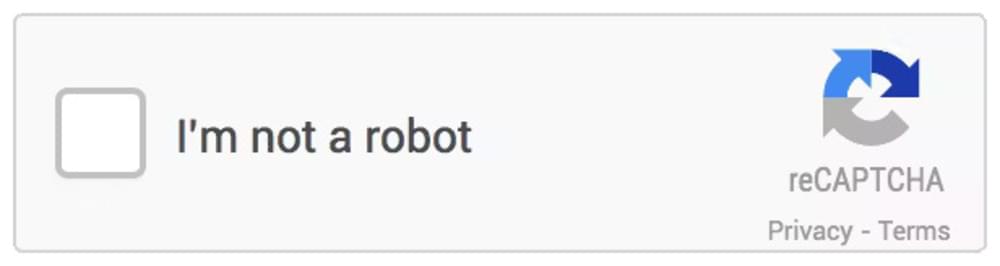
Invisible CAPTCHAs
This type of CAPTCHA works behind the scenes to detect bot behavior without requiring any action from the user. By analyzing the user’s behavior on the website, such as mouse movements and click patterns, the Invisible CAPTCHA can determine if the user is a human or a bot.

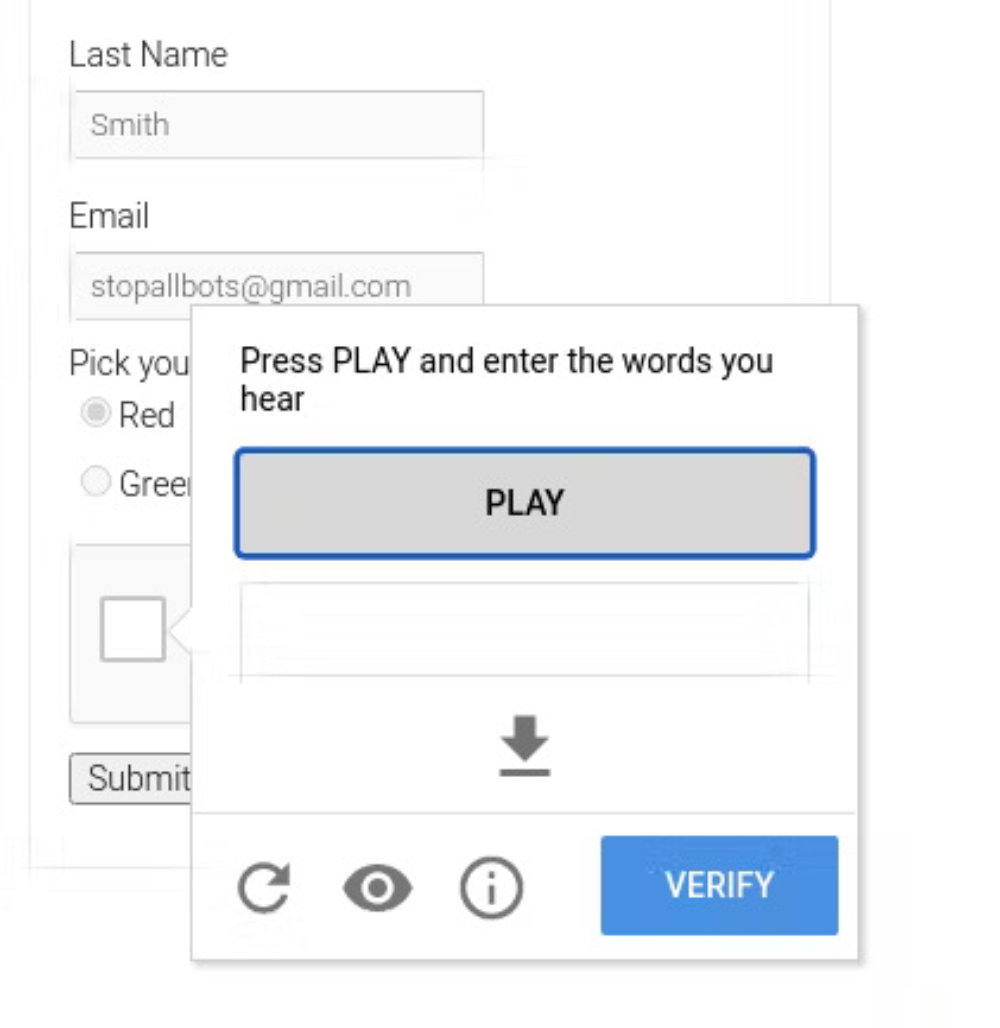
Audio CAPTCHAs
These types of CAPTCHAs are designed to assist users with visual impairments or those who have difficulty solving text or image-based CAPTCHAs. Users are required to listen to an audio recording and enter the characters or words they hear. However, audio CAPTCHAs can sometimes be challenging for users with hearing impairments or in noisy environments.
How to Avoid CAPTCHAs in Web Scraping
While CAPTCHAs can be frustrating for web scrapers, there are ways you can bypass them:
1. CAPTCHA Solver
CAPTCHA solvers are automated tools designed to bypass CAPTCHA challenges by analyzing and deciphering the distorted text, images, or puzzles presented in the CAPTCHA tests. This is the most common way to bypass CAPTCHAs in web scraping.
CAPTCHA solving service like Crawlbase Crawling API has in-built no-code function that easily bypasses captchas while web scraping. Crawlbase’s CAPTCHA solver integrates seamlessly into existing workflows, offering easy integration via APIs or browser extensions. Users can incorporate Crawlbase’s solution into their automation scripts or applications, enabling efficient handling of CAPTCHA obstacles during large-scale data extraction or automated browsing operations.

2. Smart Proxy
By using rotating IP addresses and changing the user-agent of your scraping bot, you can simulate different users accessing the website. This can help you avoid triggering CAPTCHAs that are triggered by suspicious or repeated requests from the same IP address.
Proxy rotation involves using a pool of proxies and switching between them periodically. This makes it difficult for websites to track and block your scraping activities. Similarly, Rotating user-agent strings help mimic diverse browsing behavior by presenting different browser and device information with each request, making it harder for websites to detect and block automated traffic. This can help you evade CAPTCHAs that are specifically designed to target certain user-agents.
Utilizing smart proxies helps bypass CAPTCHAs by IP rotation, enables users to appear as if they are accessing the website from various locations, thereby reducing the likelihood of detection and blocking. Check out our list of best proxy servers and best rotating proxies.
3. OCR (Optical Character Recognition)
OCR technology is used to recognize and interpret text from images, enabling automated systems to read and process CAPTCHAs that are image-based.
One commonly used method to bypass captchas is by utilizing Optical Character Recognition (OCR) tools. OCR technology enables machines to recognize and interpret text from images, making it possible to extract text from captcha images. By leveraging machine learning algorithms, OCR tools can analyze the distorted characters in captchas and generate the correct solutions.
To implement OCR-based captcha bypass methods, you can use libraries like Tesseract, which is a popular open-source OCR engine. Tesseract supports various programming languages, making it accessible for developers across different platforms. By integrating Tesseract into your web scraping script, you can extract the characters from captcha images and automate the solving process.
However, it’s important to note that OCR-based methods may not be effective for captchas with more complex distortions or additional layers of security. In such cases, alternative approaches may be required.
4. Machine Learning Algorithms:
Machine learning algorithms can be trained to recognize patterns in CAPTCHAs and develop strategies to solve them effectively, enhancing the success rate of automated CAPTCHA bypassing.
Frameworks like TensorFlow and PyTorch provide powerful tools for training machine learning models. These frameworks allow you to build and train custom models using deep learning techniques. By integrating a trained model into your web scraping script, you can automate the process of solving captchas.
While machine learning-based methods can be effective in bypassing captchas, they require a significant amount of training data and computational resources. Additionally, the accuracy of the models may vary depending on the complexity of the captchas they encounter.
Related Read: Web Scraping for Machine Learning
5. Headless Browsers:
Headless browsers operate without a graphical user interface, allowing automated interactions with websites while avoiding detection mechanisms that rely on user interfaces, such as CAPTCHAs.
6. Knowing Hidden Traps:
Understanding and circumventing hidden traps, such as invisible form fields or JavaScript-based challenges, is crucial for successful CAPTCHA bypassing as these traps may trigger additional security measures.
7. Mimic human behavior:
Implementing techniques to simulate human behavior, such as mimicking mouse movements, scroll patterns, and typing speed, can help evade detection by making automated interactions appear more natural.
8. Save Cookies:
Saving and managing cookies enables automated systems to maintain session information, including login credentials and session tokens, which can aid in bypassing CAPTCHAs and accessing restricted content.
9. Hide Automation Indicators:
Concealing automation indicators, such as browser automation tools or scripting languages, helps evade detection by making the automated traffic appear indistinguishable from genuine user interactions.
10. Building delays and timeouts:
Implementing delays and timeouts in web scraping scripts can help reduce the chances of encountering CAPTCHAs. By simulating human browsing behavior, the scraping process can appear less automated to the website.
Final Thoughts
As CAPTCHAs get better, it’s hard to know what’s next for beating them. Websites will probably add tougher security, making it even harder to get past CAPTCHAs. But at the same time, technology like machine learning and AI is getting smarter too, so there might be new ways to beat CAPTCHAs.
But don’t worry! Even though things might get trickier, there’s always a way forward. With the right tricks and know-how, you can still beat CAPTCHAs and get the data you need from the web. Just keep learning and trying new things, and remember to do it all in a fair and responsible way.
FAQ’s
Why is it important to bypass CAPTCHAs in web scraping?
Bypassing CAPTCHAs in web scraping is crucial because it allows you to automate the process of extracting data from websites without being obstructed by these security measures. It saves time and effort, enabling you to efficiently gather the desired information for your projects.
Are there any legal implications associated with bypassing CAPTCHAs in web scraping?
The legality of bypassing CAPTCHAs in web scraping depends on various factors, including the website’s terms of service, the purpose of scraping, and the jurisdiction you operate in. It’s essential to review and comply with the website’s terms of service and relevant laws to avoid potential legal issues.
How do I choose the right CAPTCHA solving service for web scraping?
When selecting a CAPTCHA solving service for web scraping, consider factors such as accuracy, speed, reliability, pricing, and compatibility with your scraping tools or scripts. It’s also advisable to read reviews and testimonials from other users to gauge the service’s effectiveness.
What are some best practices for bypassing CAPTCHAs in web scraping?
Best practices for bypassing CAPTCHAs in web scraping include rotating IP addresses to avoid detection, simulating human-like behavior to mimic genuine user interactions, respecting robots.txt rules, and using CAPTCHA solving services responsibly to minimize disruptions to the target website.
Can I completely automate the process of bypassing CAPTCHAs in web scraping?
Yes you can automate bypassing captchas in web scraping by using Proxy servers or a web scraper that fully automated captcha solving.
What are the Challenges and Limitations of Bypassing CAPTCHAs?
Reliability: CAPTCHA-solving services can vary in their accuracy and reliability. Relying on these services may introduce a level of uncertainty and decrease the overall success rate of web scraping.
Cost: CAPTCHA-solving services often require payment or subscription plans, adding an additional expense to the web scraping process.
Legality and ethics: Bypassing CAPTCHAs may raise legal and ethical concerns. It is important to ensure that any bypassing methods employed are within the boundaries of the law and adhere to ethical standards.
Evolution of CAPTCHA technologies: CAPTCHAs continue to become more sophisticated to combat automated solving techniques. Hence, bypassing them requires staying ahead of these advancements. This can lead to a continuous cycle of innovation and adaptation in the field of web scraping
Additional security measures: some websites implement additional security measures beyond CAPTCHAs to prevent web scraping. These measures may include IP blocking, user-agent detection, and behavior analysis. Successfully bypassing CAPTCHAs in such cases may require a comprehensive approach that addresses all layers of security, adding complexity to the scraping process.




