How to Scrape Airbnb Price Data with Python

This blog is originally posted to crawlbase blog.
When planning a trip or checking property prices, scraping Airbnb data becomes crucial for securing the best accommodation deals. It’s essential to find the perfect place at the right price, especially when information plays a key role in our decisions. Airbnb is a popular platform for both travelers and researchers, providing a wide range of properties. If you want to collect important pricing data from Airbnb, you’re in the right spot. This guide will show you how to scrape Airbnb prices using Python and the Crawlbase Crawling API.
If you want to head right into steps of how to scrape Airbnb data, Click here.
Table of Contents
Installing Python and necessary libraries
Selecting the right Integrated Development Environment (IDE)
Obtaining API credentials for the Crawlbase Crawling API
Exploring the components of Airbnb property pages
Identifying key elements for scraping pricing information
Overview of Crawlbase Crawling API
Advantages and capabilities of using Crawlbase for Airbnb scraping
How to utilize the Crawlbase Python library
Initiating HTTP requests to Airbnb property pages
Analyzing HTML structure to locate pricing data
Extracting and handling price information effectively
Saving scraped price data in a structured format (e.g., CSV)
Storing data in a SQLite database for further analysis
Why Scraping Airbnb Price Data Matters
Understanding how much Airbnb charges is important. Whether you’re planning a trip, doing research, or thinking about investing, having the right pricing details gives you an advantage. You can collect this useful information and make smart decisions by scraping data.

Informed Decision-Making: Accurate pricing information allows travelers to plan and budget effectively, making informed decisions about their accommodation choices.
Market Research: For researchers and analysts, scraping Airbnb price data provides valuable insights into market trends, helping them understand price variations and competitive landscapes.
Investment Opportunities: Individuals exploring property investments can benefit from scraped pricing data to identify lucrative opportunities and potential returns on investment.
Competitive Analysis: Businesses in the hospitality industry can use scraped data to perform competitive analysis, enabling them to adjust their pricing strategies based on market trends.
Customized Offerings: Property owners and hosts can optimize their pricing strategies by analyzing scraped data and tailoring their offerings to meet the demands of their target audience.
Enhanced Planning: Travel agencies and travel planners can use scraped data to offer clients better-planned trips, consider accommodation costs, and ensure budget-friendly options.
User Experience Improvement: Platforms like Airbnb can leverage scraped data to enhance the user experience by providing accurate and real-time pricing information.
Data-Driven Insights: For data enthusiasts, scraping Airbnb price data opens up possibilities for data-driven insights, leading to a deeper understanding of the vacation rental market.
Benefits of Using Python and Crawlbase Crawling API
Understanding why Python and the Crawlbase Crawling API are useful for scraping Airbnb prices is essential for a smooth and effective data extraction process. Python is great for a few reasons:
Easy to Learn and Use: Python is simple and easy to understand, making it suitable for both beginners and experienced developers.
Lots of Helpful Libraries: Python has many libraries like BeautifulSoup and Requests, making web scraping tasks more manageable with less code.
Community Help: The big Python community has lots of tutorials and forums, so if you face problems, there’s plenty of support.
Works Everywhere: Python works on different operating systems without changes, making it flexible.
When you add the Crawlbase Crawling API to Python, you get even more advantages:
Handles Big Tasks: The API helps with big datasets and extensive scraping tasks, making it easy to scale up operations.
Safe IP Rotation: The API can rotate IP addresses, adding security and privacy. IP rotation helps bypass limits and avoid bans, ensuring uninterrupted data extraction.
Beats Anti-Scraping Measures: The API is designed to tackle anti-scraping measures on websites, making data extraction reliable and smooth.
Better Data Quality: Using the API improves the accuracy and quality of scraped data, giving users reliable and up-to-date information.
In short, combining Python with the Crawlbase Crawling API gives you a powerful solution for scraping Airbnb prices. Now, let’s responsibly and effectively start this journey to scrape Airbnb price data!
Setting Up Your Environment
We must prepare our environment before building an airbnb data scraper with Python. This includes installing the necessary tools, selecting the right Integrated Development Environment (IDE), and obtaining the essential API credentials.
Installing Python and necessary libraries
Python is the programming language of choice for web scraping due to its versatility and wealth of libraries. If you don’t already have Python installed on your system, you can download it from the official website at python.org. Once Python is up and running, the next step is to ensure you have the required libraries for our web scraping project. We’ll primarily use three main libraries:
- Crawlbase Python Library: This library is the heart of our web scraping process. It allows us to make HTTP requests to Airbnb’s property pages using the Crawlbase Crawling API. To install it, you can use the “pip” command with:
pip install crawlbase |
- Beautiful Soup 4: Beautiful Soup is a Python library that simplifies the parsing of HTML content from web pages. It’s an indispensable tool for extracting data. Install it with:
pip install beautifulsoup4 |
- Pandas: Pandas is a powerful data manipulation and analysis library in Python. We’ll use it to store and manage the scraped price data efficiently. You can install Pandas with:
pip install pandas |
Having these libraries in place sets us up for a smooth web scraping experience.
Selecting the right Integrated Development Environment (IDE)
While you can write Python code in a simple text editor, an Integrated Development Environment (IDE) can significantly enhance your development experience. It provides features like code highlighting, auto-completion, and debugging tools, making your coding more efficient. Here are a few popular Python IDEs to consider:
PyCharm: PyCharm is a robust IDE with a free Community Edition. It offers features like code analysis, a visual debugger, and support for web development.
Visual Studio Code (VS Code): VS Code is a free, open-source code editor developed by Microsoft. Its extensive extension library makes it versatile for various programming tasks, including web scraping.
Jupyter Notebook: Jupyter Notebook is excellent for interactive coding and data exploration and is commonly used in data science projects.
Spyder: Spyder is an IDE designed for scientific and data-related tasks, providing features like a variable explorer and an interactive console.
Obtaining API credentials for the Crawlbase Crawling API
To make our web scraping project successful, we’ll leverage the power of the Crawlbase Crawling API. This API is designed to handle complex web scraping scenarios like Airbnb prices efficiently. It simplifies accessing web content while bypassing common challenges such as JavaScript rendering, CAPTCHAs, and anti-scraping measures.
Here’s how to get started with the Crawlbase Crawling API:
Visit the Crawlbase Website: Open your web browser and navigate to the Crawlbase signup page to begin the registration process.
Provide Your Details: You’ll be asked to provide your email address and create a password for your Crawlbase account. Fill in the required information.
Verification: After submitting your details, you may need to verify your email address. Check your inbox for a verification email from Crawlbase and follow the provided instructions.
Login: Once your account is verified, return to the Crawlbase website and log in using your newly created credentials.
Access Your API Token: You’ll need an API token to use the Crawlbase Crawling API. You can find your API tokens on your Crawlbase dashboard.
Note: Crawlbase offers two types of tokens, one for static websites and another for dynamic or JavaScript-driven websites. Since we’re scraping Airbnb, which relies on JavaScript for dynamic content loading, we’ll opt for the JavaScript Token. Crawlbase generously offers an initial allowance of 1,000 free requests for the Crawling API, making it an excellent choice for our web scraping project.
Now that we’ve set up our environment, we’re ready to dive deeper into understanding Airbnb’s website structure and effectively use the Crawlbase Crawling API for our web scraping endeavor.
Understanding Airbnb’s Website Structure
To get Airbnb’s pricing details, knowing how their website works is important. In this part, we look into the main components of Airbnb’s website, especially property pages, and the essential things to focus on when scraping pricing info.
Exploring the Components of Airbnb Property Pages
To understand how Airbnb’s website is built, we need to break down these property pages and see the parts that create the user experience.
Clear Pictures
Airbnb likes to make things look good with clear and detailed pictures on property pages. These pictures give a complete view of the place, helping hosts and guests trust each other.
Property Info in Detail
Alongside the incredible pictures, there are detailed descriptions of the property. This part is important for travelers who want to know everything about the place, like what’s in it, what it offers, and what makes it unique.
Reviews from Guests
Being honest and letting users share their thoughts are big parts of Airbnb’s success. Property pages show reviews and ratings from guests, so people can decide based on the experiences of others who stayed there.
Booking Info and When You Can Stay
Making it easy to book is a big deal for Airbnb. The booking part of property pages tells you when the place is available, how much it costs, and how to book it, making it simple for users to reserve their stay.
Identifying Key Elements for Scraping Pricing Information
For those who love data and researchers trying to find useful info in Airbnb’s extensive database, scraping pricing details is super important. Knowing which things to focus on for accurate and complete data collection is critical.
Listing Price
The main thing is the listing price itself. This shows how much it costs to book a place and depends on things like where it is, what it offers, and how much people want it.
Seasonal Changes
Airbnb changes prices based on seasons and how many people want to book. Scraping tools need to recognize these changes to give a detailed view of prices throughout the year.
Extra Costs and Discounts
Apart from the main price, other costs and discounts affect the total stay cost. Getting these details needs careful scraping, considering how hosts set different fees.
Minimum Stay Rules
Some hosts say you must stay a minimum number of days, affecting prices. Scraping tools should be set up to get this info, showing the host’s booking preferences.
In conclusion, Getting around Airbnb’s website means digging into property pages and smartly scraping prices. By understanding these things, data enthusiasts can uncover the details of Airbnb’s offerings, learning valuable things about accommodation prices and trends.
Introduction to Crawlbase Crawling API
Embarking on the journey of scraping Airbnb price data brings us to a crucial ally— the Crawlbase Crawling API. In this section, we’ll provide an overview of this indispensable tool, outlining its advantages and capabilities in the realm of Airbnb scraping. Additionally, we’ll guide you through harnessing the power of the Crawlbase Python library for a seamless scraping experience.
Overview of Crawlbase Crawling API
The Crawlbase Crawling API stands as a versatile solution tailored for navigating the complexities of web scraping, particularly in scenarios like Airbnb, where dynamic content demands adept handling. This API serves as a game-changer, simplifying access to web content, rendering JavaScript, and presenting HTML content ready for parsing.
Advantages and Capabilities of Airbnb Scraping
Utilizing the Crawlbase Crawling API for scraping Airbnb brings forth several advantages:
JavaScript Rendering: Many websites, including Airbnb, heavily rely on JavaScript for dynamic content loading. The Crawlbase API adeptly handles these elements, ensuring comprehensive access to Airbnb’s dynamically rendered pages.
Simplified Requests: The API abstracts away the intricacies of managing HTTP requests, cookies, and sessions. This allows you to concentrate on refining your scraping logic, while the API handles the technical nuances seamlessly.
Well-Structured Data: The data obtained through the API is typically well-structured, streamlining the parsing and extraction process. This ensures you can efficiently retrieve the pricing information you seek from Airbnb.
Scalability: The Crawlbase Crawling API supports scalable scraping by efficiently managing multiple requests concurrently. This scalability is particularly advantageous when dealing with the diverse and extensive pricing information on Airbnb.
How to Utilize the Crawlbase Python Library
The Crawlbase Python library acts as a lightweight and dependency-free conduit to harness the capabilities of Crawlbase APIs. Here’s a step-by-step guide on how to leverage the Crawlbase Python library for your Airbnb scraping endeavors:
- Import the Library:
To initiate using the Crawlbase Crawling API from the Python library, start by importing the essential Crawling API class. This foundational step opens doors to accessing various Crawlbase APIs.
from crawlbase import CrawlingAPI |
- Initialization:
Once armed with your Crawlbase API token, the next crucial step is to initialize the CrawlingAPI class. This connection facilitates the utilization of the extensive capabilities of Crawlbase.
api = CrawlingAPI({ 'token': 'YOUR_CRAWLBASE_TOKEN' }) |
- Sending Requests:
With the CrawlingAPI class in place and your Crawlbase API token securely configured, you’re prepared to dispatch requests to Airbnb’s target pages. Here’s an example of crafting a GET request tailored for scraping Airbnb pricing information.
response = api.get('https://www.airbnb.com/property-page-url') |
Now that you know about the Crawlbase Crawling API and how to use the Crawlbase Python library, you’re ready for a successful Airbnb scraping adventure. In the next parts, we’ll go deeper into scraping Airbnb prices. We’ll cover everything, from starting HTTP requests to getting and storing pricing data for analysis.
Web Scraping Airbnb Prices
Now that we’ve laid the groundwork with an understanding of Airbnb’s website structure and introduced the powerful Crawlbase Crawling API let’s delve into the practical aspects of scraping Airbnb prices. This section will guide you through the essential steps, providing code examples at each juncture.
Initiating HTTP requests to Airbnb property pages
We’ll initiate HTTP requests to the Airbnb property pages using the Crawlbase Crawling API to begin the scraping process. Here’s a simple example using the Crawlbase Python library:
from crawlbase import CrawlingAPI |
By sending an HTTP request to a Airbnb property page, we retrieve the raw HTML content of that specific page. It’s worth noting that we incorporate the page_wait and ajax_wait parameters. These parameters play a crucial role in ensuring that we receive the HTML content only after it has been fully loaded. You can read about Crawling API parameters here. This HTML will be the source of the price data we’re after.
Output HTML:

Analyzing HTML structure to locate pricing data
With the HTML content obtained from the property page, the next step is to analyze its structure and pinpoint the location of pricing data. Use developer tools in your browser to inspect the HTML and identify the specific HTML elements containing price information.
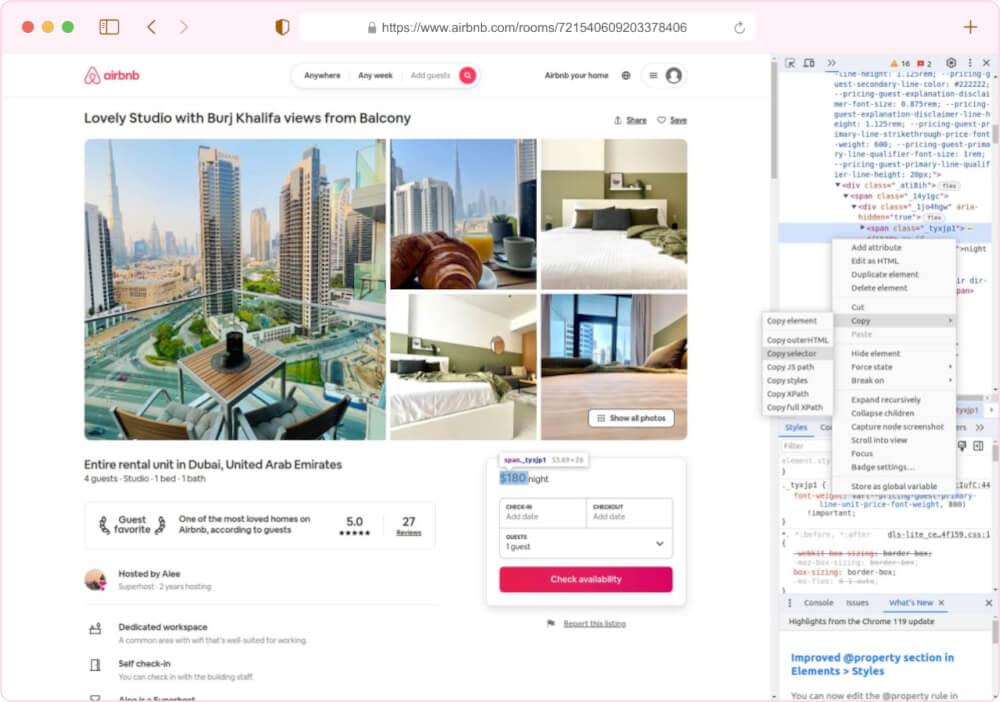
Open the Web Page: Navigate to the Airbnb website and land on a property page that beckons your interest.
Right-Click and Inspect: Employ your right-clicking prowess on an element you wish to extract (e.g., a Buy Box) and select “Inspect” or “Inspect Element” from the context menu. This mystical incantation will conjure the browser’s developer tools.
Locate the HTML Source: Within the confines of the developer tools, the HTML source code of the web page will lay bare its secrets. Hover your cursor over various elements in the HTML panel and witness the corresponding portions of the web page magically illuminate.
Identify CSS Selectors: To liberate data from a particular element, right-click on it within the developer tools and gracefully choose “Copy” > “Copy selector.” This elegant maneuver will transport the CSS selector for that element to your clipboard, ready to be wielded in your web scraping incantations.
Once you have these selectors, you can proceed to structure your data scraper to extract the required information effectively.
Extracting and handling price information effectively
Once the price element is identified, extract and handle the price information as needed. This may involve additional parsing or data manipulation based on the format in which the price is presented.
# Import necessary libraries |
The script extracts various details about the listing, such as the product name, price, discounted price, and rating, by selecting specific elements from the HTML. Finally, it prints or saves the extracted product details in a structured JSON format. In case of any errors during the process, it catches exceptions and prints an error message.
Example Output:
{ |
These code examples show how to start requests, analyze HTML, and extract Airbnb pricing info with Python and Crawlbase Crawling API. Next, we’ll cover storing scraped prices and wrap up with key takeaways.
Storing the Scraped Price Data
After successfully scraping data from Airbnb’s property pages, the next crucial step is storing this valuable information for future analysis and reference. In this section, we will explore two common methods for data storage: saving scraped data in a CSV file and storing it in an SQLite database. These methods allow you to organize and manage your scraped data efficiently.
Saving scraped price data in a structured format (e.g., CSV)
CSV stands out as an extensively employed format designed for safeguarding tabular data. It represents a straightforward and easily understandable method for preserving structured data, rendering it a superb option for archiving your extracted Airbnb property data.
We’ll incorporate an additional stage to save the gleaned data into a CSV file to enhance our preceding web scraping script. This will be achieved by utilizing the renowned Python library, pandas. Below is a refined iteration of the script:
import pandas as pd |
In this revised script, we’ve incorporated pandas, a robust data manipulation and analysis library. Following extracting and compiling property details, we leverage pandas to construct a DataFrame from this information. Subsequently, the to_csv method is employed to store the DataFrame into a CSV file named “airbnb_properties_data.csv” within the current directory. By specifying index=False, we ensure that the DataFrame’s index is not saved as a distinct column in the CSV file.
By utilizing pandas, you gain the flexibility to work with and analyze your collected data seamlessly. The resulting CSV file is easily accessible in various spreadsheet software and can be imported into other data analysis tools, facilitating additional exploration and visualization.
Storing data in a SQLite database for further analysis
If you favor a method of data storage that is more structured and amenable to queries, SQLite presents itself as a nimble, serverless database engine that stands as an excellent option. Establishing a database table allows you to systematically store your scraped data, enabling streamlined data retrieval and manipulation. The following outlines the adjustments to the script to incorporate SQLite database storage:
import sqlite3 |
Within this revised code, new functions have been introduced to facilitate the creation of an SQLite database and table create_database and the storage of scraped data in the database save_to_database. The create_database function validates the existence of both the database and table, generating them if absent. Subsequently, the save_to_database function inserts the scraped data into the ‘properties’ table.
Upon executing this code, your scraped Airbnb property data will be securely stored in an SQLite database named ‘airbnb_properties.db’. This enables subsequent retrieval and manipulation of the data using SQL queries or seamless programmatic access in your Python projects.
Final Words
This guide has given you the basic know-how and tools to easily get Airbnb prices using Python and the Crawlbase Crawling API. Whether you’re new to this or have some experience, the ideas explained here provide a strong starting point for your efforts.
As you continue your web scraping journey, remember the versatility of these skills extends beyond Airbnb. Explore our additional guides for platforms like Amazon, eBay, Walmart, and AliExpress, broadening your scraping expertise.
Don’t forget to check out our guides on scraping price data for other e-commerce platforms:
📜 How to Scrape Walmart Prices
📜 How to Scrape Amazon Prices
Web scraping presents challenges, and our commitment to your success goes beyond this guide. If you encounter obstacles or seek further guidance, the Crawlbase support team is ready to assist. Your success in web scraping is our priority, and we look forward to supporting you on your scraping journey.
Frequently Asked Questions (FAQs)
Q1: Is web scraping Airbnb prices legal?
Web scraping is a neutral technology, but its legality often depends on the terms of service of the website being scraped. Airbnb, like many other platforms, has policies regarding automated data collection. Before scraping, it’s essential to review Airbnb’s terms of service and robots.txt file, ensuring compliance with their rules.
Q2: Can I use Crawlbase Crawling API for scraping Airbnb without technical expertise?
While Crawlbase Crawling API streamlines the scraping process, some technical expertise is recommended. Basic knowledge of Python and web scraping concepts will enhance your ability to harness the full potential of the API. However, Crawlbase offers comprehensive documentation and support to assist users at every skill level.
Q3: Are there rate limits or restrictions when using Crawlbase Crawling API for Airbnb scraping?
Yes, Crawlbase Crawling API has rate limits to ensure fair usage. The specific limits depend on your subscription plan. It’s crucial to review Crawlbase’s documentation and subscription details to understand the limitations and capabilities of your chosen plan.
Q4: Can I scrape Airbnb data at scale using Crawlbase Crawling API?
Yes, Crawlbase Crawling API supports scalable web scraping, allowing users to handle multiple requests simultaneously. This feature is advantageous when dealing with large datasets or scraping numerous pages on Airbnb. However, users should be mindful of their subscription plan’s rate limits to optimize the scraping process.
Q5: How can I scrape Airbnb prices using BeautifulSoup?
Scraping Airbnb prices using BeautifulSoup involves several steps. First, make HTTP requests to Airbnb property pages using Python’s requests library. Once the HTML content is retrieved, utilize BeautifulSoup for parsing and navigating the HTML structure. Identify the specific elements containing pricing information, adapting the code to Airbnb’s HTML structure. Keep in mind that Airbnb may use JavaScript for dynamic content loading, so consider incorporating the Crawlbase Crawling API to handle such scenarios and prevent potential IP blocks. Regularly check and update your scraping logic in response to any changes in Airbnb’s website structure. Always ensure compliance with Airbnb’s terms of service and scraping policies to maintain ethical scraping practices.




