How to Scrape Airbnb Property listings Using Rust

This blog is originally posted to crawlbase blog.
In the world of online property listings, scraping Airbnb property listings using Rust is an essential skill for those looking to tap into this popular platform, offering a wide range of places to stay. Whether you’re planning a trip or interested in understanding the property market, scraping Airbnb listings can provide valuable insights. This guide’ll explore how to scrape Airbnb listings using Rust, a powerful programming language. To make our scraping journey smoother, we’ll use the Crawlbase Crawling API, a tool we’ve successfully employed in the past.
In the upcoming sections, we’ll walk you through setting up Rust on your computer, introduce you to the Crawlbase API, and guide you on scraping Airbnb property listings step by step. From navigating Airbnb’s search pages to saving your scraped data, we’ve got it covered. Join us on this adventure as we combine Rust’s strength with Crawlbase’s data extraction to uncover the information hidden in Airbnb’s vast collection of property listings. Let’s get started!
Table Of Contents
Why Scrape Airbnb Property Listings?
Benefits of using the Crawlbase Crawling API with Rust
Installing Rust Programming Language
Creating a New Rust Project
Selecting the right Integrated Development Environment (IDE)
Obtaining API credentials for the Crawlbase Crawling API
Exploring the components of Airbnb search page
Identifying key Elements for scraping
Overview of the Crawlbase Crawling API
Advantages and capabilities of leveraging the Crawling API
Crawlbase Crawling API with Rust
Crawling Airbnb Search Page HTML
Inspecting HTML to Get CSS Selectors
Retrieving property listing data from HTML
Storing scraped data in a CSV File
Storing scraped data in a SQLite Database
Scraping Airbnb Listings with the Crawlbase Crawling API in Rust
Venturing into the realm of scraping Airbnb listings using Rust and the Crawlbase API presents a multitude of opportunities for data enthusiasts and researchers. This endeavor allows for a detailed exploration into the inner workings of Airbnb’s data, providing a pathway to uncover valuable insights. Now, let’s examine scraping Airbnb listings and discover the benefits of using the Crawlbase Crawling API with Rust.
Why Scrape Airbnb Property Listings?
The necessity to scrape Airbnb arises due to several factors, each contributing to a more thorough comprehension of the platform’s real estate dynamics:
Data Abundance: Airbnb hosts a multitude of property listings, making scraping essential for extracting a wide range of data comprehensively.
Granular Insights: For users seeking specific details or conducting in-depth market analysis, scraping provides a systematic approach to extract targeted information, enhancing insights into property attributes and market dynamics.
Market Research: Scraping Airbnb listings facilitates nuanced exploration of the real estate market, aiding in identifying trends, price fluctuations, and popular amenities in different locations.
Customized Queries: With scraping, users can tailor queries to extract precise information, whether it’s about property types, amenities, or pricing strategies. This customization ensures the extraction of relevant and focused data according to specific research needs.
Benefits of Using the Crawlbase Crawling API with Rust
Performance Excellence: Rust’s reputation for performance, safety, and low-level control aligns perfectly with the demands of web scraping.
Efficiency Amplified: Rust’s capacity to handle low-level system details complements the intricacies of web scraping, resulting in an efficient and reliable process.
Seamless Integration: The combination of Rust with the Crawling API simplifies complex scraping scenarios, enabling the extraction of dynamic web content with ease.
Smooth Navigation: Crawlbase’s ability to handle dynamic web content ensures a seamless scraping experience, particularly vital for navigating Airbnb’s diverse and dynamic pages.
Avoiding Detection: Crawlbase’s rotating IP addresses and anti-crawling measures enhance the reliability of the scraping process, reducing the risk of being blocked or facing CAPTCHA challenges.
As we progress, we’ll guide you through the setup of your Rust environment and illustrate how to leverage the features of the Crawlbase API for optimal scraping results.
Setting Up Your Environment
Preparing your environment is a crucial step before delving into the intricacies of scraping Airbnb property listings using Rust and the Crawlbase Crawling API. This comprehensive setup involves installing the necessary tools, selecting an appropriate Integrated Development Environment (IDE), and obtaining essential API credentials. Let’s break down each component to ensure a smooth and efficient development process.
Installing Rust Programming Language
Installing Rust and configuring dependencies are crucial steps to set up your environment for scraping Airbnb property listings using Rust and the Crawlbase Crawling API. Follow the detailed instructions below for both Windows and Ubuntu operating systems.
Installing Rust on Windows:
Visit the official Rust website: https://www.rust-lang.org/tools/install.
Click on the “Download Rust” button.
Run the downloaded executable file.
Follow the on-screen instructions for installation, ensuring that you select the option to add Rust to the system PATH during the installation process.
Installing Rust on Ubuntu:
Open a terminal window.
Run the following command to download and run the Rust installer:
curl --proto '=https' --tlsv1.3 https://sh.rustup.rs -sSf | sh |
- Follow the on-screen instructions to complete the Rust installation. Ensure that you select the option to add Rust to the system PATH.
Creating a New Rust Project
Before we delve into web scraping with Rust, let’s establish a new Rust project to maintain organized code. Follow these steps to create a project directory and a simple “Hello, world!” Rust program using Cargo, Rust’s package manager.
Creating a Project Directory
Begin by creating a directory to store your Rust code. For better organization, we recommend creating a projects directory in your home directory.
For Linux, macOS, and Power-Shell on Windows:
$ mkdir ~/projects |
For Windows CMD:
> mkdir "%USERPROFILE%\projects" |
Project Structure
When you use cargo new, Cargo initializes a new Rust project for you. It creates a Cargo.toml file, which is the configuration file for your project, and a src directory containing the main.rs file where your Rust code resides.
my_airbnb_scraper |
Writing and Running a Rust Program
Open the main.rs file in the src directory and replace its content with the following code:
// Filename: main.rs |
Save the file and return to your terminal window in the ~/projects/my_airbnb_scraper directory. Use the following command to compile and run the file:
For Linux, macOS or Windows CMD:
cargo run |
Regardless of your operating system, you should see the output “Hello, world!” printed to the terminal. Congratulations! You’ve just written and executed your first Rust program, marking your entry into the world of Rust programming. Welcome!
Install Required Dependencies:
Open a command prompt or terminal window in your project directory.
Use the following commands to add the required Rust libraries (crates) for web scraping:
cargo add reqwest |
reqwest: A popular HTTP client library for Rust that simplifies making HTTP requests. It is commonly used for web scraping and interacting with web APIs.
scraper: A Rust crate for HTML and XML parsing that provides a convenient way to navigate and manipulate structured documents using selectors, similar to jQuery in JavaScript.
urlencoding: A Rust crate for URL encoding and decoding. It facilitates the manipulation of URL components, ensuring proper formatting for use in HTTP requests or other contexts where URLs need to be encoded.
csv: This Rust crate is used for reading and writing CSV (Comma-Separated Values) files. It provides functionality for parsing CSV data into structured records and converting structured records back into CSV format. The
csvcrate is essential when you want to store or retrieve tabular data, making it particularly useful for saving scraped information.serde: A versatile serialization and deserialization framework for Rust. The
serdecrate allows you to seamlessly convert Rust data structures into various formats, such as JSON or binary, and vice versa. Its inclusion is important when you need to persistently store or transmit data in a serialized format, a common requirement in web scraping scenarios.rusqlite: The
rusqlitecrate is a Rust library for interacting with SQLite databases. It provides a convenient and safe interface to perform SQL operations, allowing Rust programs to connect to SQLite databases, execute queries, and manage transactions efficiently.
Cargo.toml file preview:
[package] |
These steps ensure that you have Rust installed on your system along with the required crates for effective web scraping.
Selecting the right Integrated Development Environment (IDE)
Selecting the right Integrated Development Environment (IDE) is a crucial decision that can significantly impact your development experience while working with Rust for web scraping. Here are some popular IDEs that you can consider:
Visual Studio Code (VS Code):
Website: https://code.visualstudio.com/
Description: VS Code is a free, open-source code editor developed by Microsoft. It offers a wide range of extensions, making it versatile for various programming tasks, including web scraping in Rust.
Features:
IntelliSense for code completion.
Built-in Git support.
Extensions for Rust programming.
IntelliJ IDEA with Rust Plugin:
Website: https://www.jetbrains.com/idea/
Description: IntelliJ IDEA is a powerful IDE with a Rust plugin that provides excellent support for Rust development. While IntelliJ IDEA is not free, it offers a free Community Edition with basic features.
Features:
Smart code completion.
Advanced navigation and refactoring.
Built-in terminal.
Eclipse with RustDT Plugin:
Website: https://www.eclipse.org/
Description: Eclipse is a widely-used IDE, and the RustDT plugin enhances its capabilities for Rust development. It is an open-source option suitable for developers familiar with Eclipse.
Features:
Rust project management.
Syntax highlighting and code completion.
Integrated debugger.
Rust Analyzer (Standalone):
Website: https://rust-analyzer.github.io/
Description: Rust Analyzer is not a traditional IDE but a language server that works with various code editors. It provides features like code completion, find references, and more.
Features:
Lightweight and fast.
Works with editors like VS Code, Sublime Text, and others.
Try out a couple of options to see which one aligns best with your preferences and development needs. Each IDE mentioned here has its strengths, so pick the one that suits your Rust web scraping project.
Obtaining API credentials for the Crawlbase Crawling API
To make our web scraping project successful, we’ll leverage the power of the Crawlbase Crawling API. This API is designed to handle complex web scraping scenarios like Airbnb prices efficiently. It simplifies accessing web content while bypassing common challenges such as JavaScript rendering, CAPTCHAs, and anti-scraping measures.
Here’s how to get started with the Crawlbase Crawling API:
Visit the Crawlbase Website: Open your web browser and navigate to the Crawlbase signup page to begin the registration process.
Provide Your Details: You’ll be asked to provide your email address and create a password for your Crawlbase account. Fill in the required information.
Verification: After submitting your details, you may need to verify your email address. Check your inbox for a verification email from Crawlbase and follow the provided instructions.
Login: Once your account is verified, return to the Crawlbase website and log in using your newly created credentials.
Access Your API Token: You’ll need an API token to use the Crawlbase Crawling API. You can find your API tokens on your Crawlbase dashboard.
Note: Crawlbase offers two types of tokens, one for static websites and another for dynamic or JavaScript-driven websites. Since we’re scraping Airbnb, which relies on JavaScript for dynamic content loading, we’ll opt for the JavaScript Token. Crawlbase generously offers an initial allowance of 1,000 free requests for the Crawling API, making it an excellent choice for our web scraping project.
Now that we’ve set up our environment, we’re ready to dive deeper into understanding Airbnb’s website structure and effectively use the Crawlbase Crawling API for our web scraping endeavor.
Understanding Airbnb’s Website Structure
Unlocking the secrets of Airbnb’s website architecture is akin to wielding a map before embarking on a journey. In this section, we’ll unravel the intricate components of Airbnb’s search page, shedding light on the key elements that form the bedrock of an effective scraping strategy.
Exploring the Components of Airbnb Search Page
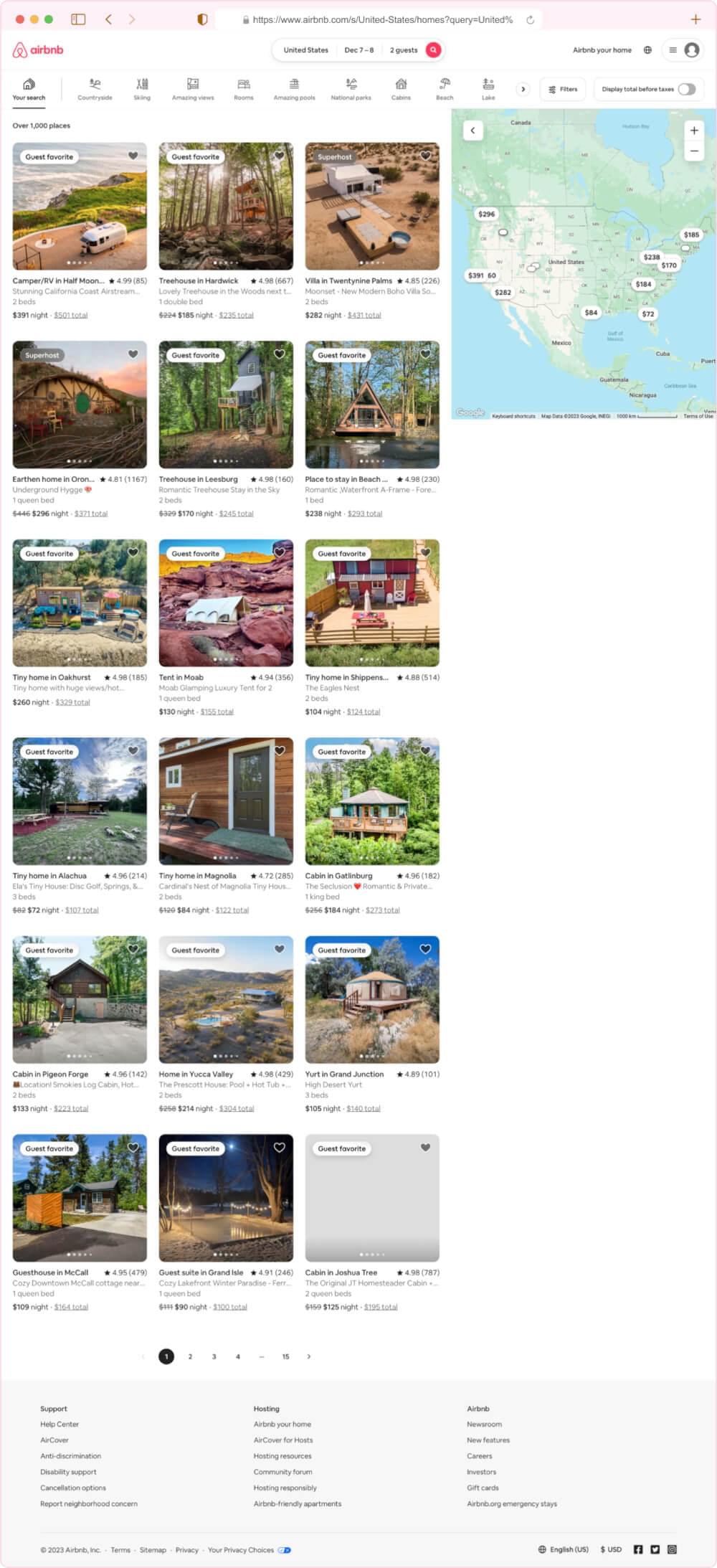
- Search Bar:
The search bar is the digital compass for users navigating Airbnb’s vast offerings. It’s not just a visual element; it’s an interactive gateway. By inspecting the HTML behind this bar, we gain insights into how Airbnb structures search queries programmatically.
- Search Results:
As users hit “Search,” the page unveils a tapestry of property results. Each listing resides within a specific HTML structure. Grasping the nuances of these container elements is pivotal for isolating and extracting individual property details systematically.
- Filters:
Airbnb empowers users with filters, allowing fine-tuning of results. The HTML elements corresponding to these filters must be identified. Recognizing these markers enables precise scraping based on criteria such as price range, property type, and amenities.
- Pagination:
When the treasure trove of results spans multiple pages, pagination enters the scene. Understanding how Airbnb implements pagination in the HTML structure is akin to deciphering the turning points of our map. It paves the way for systematic exploration through various result pages.
Identifying Key Elements for Scraping
In the quest for Airbnb property data, pinpointing the right HTML elements is the compass leading to success:
- Property Listings Container:
Within the vast expanse of the HTML landscape, finding the container that cradles individual property listings is the starting point. This container becomes the focal point for iteration, a treasure chest waiting to be opened for details.
- Listing Details:
Each listing container conceals gems of information – property name, price, location, and amenities. To unveil these details, precision is paramount. Crafting CSS selectors with surgical precision ensures the extraction of relevant details regardless of presentation variations.
- Pagination Controls:
For adventures across multiple pages, understanding the HTML controls governing pagination is crucial. Identifying links to the next and previous pages equips the scraper for seamless traversal through Airbnb’s expansive property listings.
Now that we have a detailed map of Airbnb’s website, the next step is to use Rust and the Crawlbase Crawling API to explore and gather information from this digital space.
Introduction to Crawlbase Crawling API
Embarking on the journey of scraping Airbnb price data brings us to a crucial ally— the Crawlbase Crawling API. In this section, we’ll provide an overview of this indispensable tool, outlining its advantages and capabilities in the realm of Airbnb scraping. Additionally, we’ll guide you through harnessing the power of the Crawlbase Python library for a seamless scraping experience.
Overview of Crawlbase Crawling API
The Crawlbase Crawling API stands as a versatile solution tailored for navigating the complexities of web scraping, particularly in scenarios like Airbnb, where dynamic content demands adept handling. This API serves as a game-changer, simplifying access to web content, rendering JavaScript, and presenting HTML content ready for parsing.
Advantages and Capabilities of leveraging the Crawling API
Utilizing the Crawlbase Crawling API for scraping Airbnb brings forth several advantages:
JavaScript Rendering: Many websites, including Airbnb, heavily rely on JavaScript for dynamic content loading. The Crawlbase API adeptly handles these elements, ensuring comprehensive access to Airbnb’s dynamically rendered pages.
Simplified Requests: The API abstracts away the intricacies of managing HTTP requests, cookies, and sessions. This allows you to concentrate on refining your scraping logic, while the API handles the technical nuances seamlessly.
Well-Structured Data: The data obtained through the API is typically well-structured, streamlining data parsing and extraction process. This ensures you can efficiently retrieve the pricing information you seek from Airbnb.
Scalability: The Crawlbase Crawling API supports scalable scraping by efficiently managing multiple requests concurrently. This scalability is particularly advantageous when dealing with the diverse and extensive pricing information on Airbnb.
Note: The Crawlbase Crawling API offers a multitude of parameters at your disposal, enabling you to fine-tune your scraping requests. These parameters can be tailored to suit your unique needs, making your web scraping efforts more efficient and precise. You can explore the complete list of available parameters in the API documentation.
Crawlbase Crawling API with Rust
When using Rust for web scraping with the Crawlbase Crawling API, you’ll interact directly with the API by making HTTP requests. Although Crawlbase currently doesn’t provide a dedicated Rust library, integrating it into your Rust application is a straightforward process.
Here’s a step-by-step guide on how to leverage the Crawlbase Crawling API with Rust:
Make HTTP Requests:
Utilize Rust’s HTTP client libraries, such as reqwest or surf, to make HTTP requests to the Crawlbase Crawling API endpoint. Construct the API request URL by replacing “user_token” with your actual Crawlbase API token and “url_to_scrape” with the URL of the Airbnb property page you want to scrape.
// Example using reqwest |
Handle API Responses:
The API response will be in either JSON or HTML format, depending on your selected option. If you choose HTML, the response will contain the HTML content of the requested URL.
// Example continuation |
Error Handling:
Implement proper error handling to address potential issues, such as network errors or unsuccessful API requests.
// Example continuation |
By incorporating these steps into your Rust application, you can effectively use the Crawlbase Crawling API to scrape Airbnb property pages and extract valuable information for your project.
Scraping Airbnb Property Listing
Now that we’ve navigated the intricacies of initiating requests and understanding Airbnb’s HTML structure, let’s dive into the practical process of scraping Airbnb property listings using Rust and the Crawlbase Crawling API.
Crawling Airbnb Search Page HTML
In the realm of Rust, interacting with the Crawlbase Crawling API involves crafting HTTP requests to retrieve HTML content. Below is an example Rust code snippet demonstrating how to initiate a GET request to the Airbnb search page. Copy this code and replace you main.rs file content with it:
// Crawling Airbnb Search Page HTML |
This Rust code utilizes the reqwest crate to perform a GET request to the Airbnb search page through the Crawlbase Crawling API. The crawlbase_api_url variable is a URL constructed with your Crawlbase API token and the encoded Airbnb search page URL with specific search parameters, such as location, check-in and check-out dates, and the number of adults. The code then sends this URL to Crawlbase via the reqwest::blocking::get function, which retrieves the HTML content of the search page. It checks whether the request was successful by examining the status code, and if successful, it prints the extracted HTML content. This code serves as the initial step in web scraping Airbnb property listings, obtaining the raw HTML for further analysis and extraction of property data.
Example Output:
Inspecting HTML to Get CSS Selectors
With the HTML content obtained from the property page, the next step is to analyze its structure and pinpoint the location of pricing data. This task is where web development tools and browser developer tools come to our rescue. Let’s outline how you can inspect the HTML structure and unearth those precious CSS selectors:
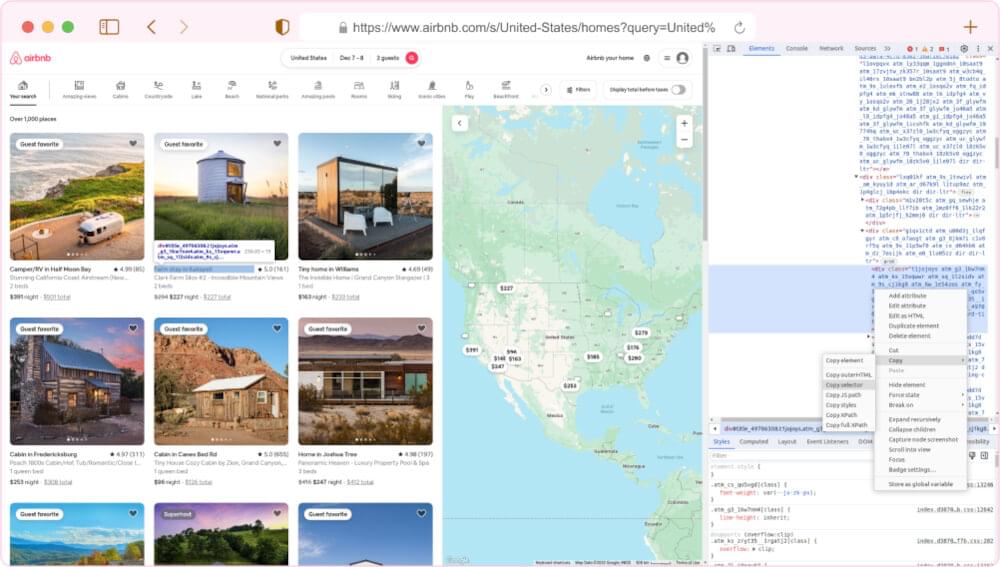
Open the Web Page: Navigate to the Airbnb website and land on a property page that beckons your interest.
Right-Click and Inspect: Employ your right-clicking prowess on an element you wish to extract (e.g., a Buy Box) and select “Inspect” or “Inspect Element” from the context menu. This mystical incantation will conjure the browser’s developer tools.
Locate the HTML Source: Within the confines of the developer tools, the HTML source code of the web page will lay bare its secrets. Hover your cursor over various elements in the HTML panel and witness the corresponding portions of the web page magically illuminate.
Identify CSS Selectors: To liberate data from a particular element, right-click on it within the developer tools and gracefully choose “Copy” > “Copy selector.” This elegant maneuver will transport the CSS selector for that element to your clipboard, ready to be wielded in your web scraping incantations.
Once you have these selectors, you can proceed to structure your data scraper to extract the required information effectively.
Retrieving property listing data from HTML
With the identified CSS selectors, we can now retrieve the property listing data from the HTML. We’ll use Scraper, a popular HTML parsing crate, to traverse the HTML and gather information from the specified elements.
For example, you can extract property titles, prices, ratings, and other relevant details from the HTML content. The data retrieved is then structured and can be stored for further analysis or processing. Let us extend our previous script and scrape this information from HTML.
use reqwest; |
The script begins by encoding the Airbnb search URL with the necessary query parameters. It then constructs a URL for a web scraping API (presumably Crawlbase) and makes a GET request to retrieve the HTML content of the Airbnb search page. After ensuring the request was successful, the script proceeds to extract the HTML content and uses the scraper crate to parse the document. It employs CSS selectors to target specific elements representing property listings. The extracted data, including property titles, ratings, and prices, is stored in a structured format using a custom SearchResult struct. Finally, the script prints or utilizes the scraped data. It’s important to note that responsible web scraping practices, compliance with terms of service, and ethical considerations should be observed when deploying such scripts.
Example Output:
Title: Camper/RV in Half Moon Bay |
Storing Scraped Data
After successfully scraping data from Airbnb’s property pages, the next crucial step is storing this valuable information for future analysis and reference. In this section, we will explore two common methods for data storage: storing scraped data in a CSV file and storing it in an SQLite database. These methods allow you to organize and manage your scraped data efficiently.
Storing scraped data in a CSV File
CSV stands out as an extensively employed format designed for safeguarding tabular data. It represents a straightforward and easily understandable method for preserving structured data, rendering it a superb option for archiving your extracted Airbnb property data.
We’ll incorporate an additional stage to save the gleaned data into a CSV file to enhance our preceding web scraping script. Below is a refined iteration of the script:
use csv::Writer; |
This updated script includes the csv crate for CSV handling. The SearchResult struct now derives the Serialize trait from the serde crate to make it compatible with CSV serialization. The write_to_csv function is added to write the scraped data to a CSV file. Ensure to replace “YOUR_CRAWLBASE_JS_TOKEN” and update the output file path as needed.
Storing scraped data in a SQLite Database
If you favor a method of data storage that is more structured and amenable to queries, SQLite presents itself as a nimble, serverless database engine that stands as an excellent option. Establishing a database table allows you to systematically store your scraped data, enabling streamlined data retrieval and manipulation. The following outlines the adjustments to the script to incorporate SQLite database storage:
use reqwest; |
The store_in_database function in the provided Rust script facilitates the storage of scraped Airbnb property listing data into an SQLite database. It begins by establishing a connection to the SQLite database file named airbnb_data.db. If the listings table does not exist, the function creates it with columns for id, title, rating, and price. Subsequently, the function prepares an SQL statement for inserting data into the listings table. It then iterates over the vector of SearchResult objects, executing the SQL statement for each entry to insert the corresponding property title, rating, and price into the database. The process employs parameterized SQL queries to ensure data integrity and prevent SQL injection. This way, the store_in_database function provides a systematic and secure mechanism for persisting the scraped Airbnb property listing data in an SQLite database, enabling subsequent retrieval and analysis.
Final Words
This guide has given you the basic know-how and tools to easily scrape Airbnb property listing using Rust and the Crawlbase Crawling API. Whether you’re new to this or have some experience, the ideas explained here provide a strong starting point for your efforts.
As you continue your web scraping journey, remember the versatility of these skills extends beyond Airbnb. Explore our additional guides for platforms like Amazon, eBay, Walmart, and AliExpress, broadening your scraping expertise.
Related Guide:
📜 How to Scrape Airbnb Prices
Web scraping presents challenges, and our commitment to your success goes beyond this guide. If you encounter obstacles or seek further guidance, the Crawlbase support team is ready to assist. Your success in web scraping is our priority, and we look forward to supporting you on your scraping journey.
Frequently Asked Questions (FAQs)
Q1: Is web scraping Airbnb prices legal?
Web scraping is a neutral technology, but its legality often depends on the terms of service of the website being scraped. Airbnb, like many other platforms, has policies regarding automated data collection. Before scraping, it’s essential to review Airbnb’s terms of service and robots.txt file, ensuring compliance with their rules.
Q2: Can I use Crawlbase Crawling API with Rust for websites other than Airbnb?
Absolutely! The Crawlbase Crawling API is a versatile tool that extends beyond Airbnb. It provides a robust solution for scraping dynamic and JavaScript-driven content on various websites. As long as you have the appropriate API credentials and understand the structure of the target website, you can employ Rust and Crawlbase for web scraping across different platforms.
Q3: Is Rust a suitable language for web scraping?
Yes, Rust is an excellent choice for web scraping due to its high performance, memory safety features, and strong ecosystem. Its concurrency support allows for efficient handling of multiple requests, and the ownership system ensures secure memory management. Rust’s reliability and speed make it well-suited for building web scrapers that can handle diverse and complex tasks.
Q4: What if I encounter challenges while setting up my Rust environment for web scraping?
If you face challenges during the setup process, the Rust community and documentation are valuable resources. The official Rust documentation provides comprehensive guidance on installation, configuration, and dependencies. Additionally, exploring forums like Stack Overflow or Rust-related communities can connect you with experienced developers who may offer insights and solutions to specific issues.
Q5: How can I handle pagination when scraping Airbnb property listings with Rust?
Handling pagination is a common requirement in web scraping, and our guide addresses this aspect specifically. We’ll explore effective techniques for navigating through multiple pages of Airbnb property listings using Rust and the Crawlbase Crawling API. These methods will help you efficiently retrieve comprehensive data sets without missing any listings.




