


This blog is originally posted to the Crawlbase blog.
Alibaba, founded in 1999 by former English teacher Jack Ma, has grown to become a global leader in e-commerce. With its comprehensive platform, Alibaba enables suppliers to showcase their products to a vast international audience while providing buyers with efficient access to a wide range of goods and suppliers worldwide.
In this blog, we will explore how to scrape Alibaba’s vast database using JavaScript as our programming language of choice. To navigate around potential blocks and CAPTCHAs, we will utilize the Crawlbase API, ensuring an effective and uninterrupted scraping process. Let’s dive into the details of scraping Alibaba for valuable data and insights.
Table of Contents
II. Two Methods of Scraping Alibaba
III. What can you extract from Alibaba?
VI. Scrape using Crawling API and Cheerio
VIII. Frequently Asked Questions
I. Why Scrape Alibaba?
Alibaba.com hosts an extensive array of products across more than 40 major categories, encompassing consumer electronics, machinery, apparel, and more. Scraping allows access to this vast repository of products, enabling businesses to gather valuable insights into market trends and product availability.
With buyers spanning across 190+ countries and regions, Alibaba facilitates a significant volume of communication between buyers and suppliers daily. Scraping this interaction data provides valuable insights into market demand, supplier responsiveness, and emerging trends.

Scraping Alibaba’s Search Engine Results Pages (SERP) offers a range of advantages for businesses:
Sourcing: By scraping product listings and supplier information, businesses can efficiently identify potential suppliers for their sourcing needs.
Price Monitoring: Scraping allows businesses to track pricing trends for specific products, enabling them to make informed pricing decisions.
Market Research: Scraping data from Alibaba SERP provides valuable market insights, including consumer preferences, product popularity, and emerging trends.
Competitor Analysis: Analyzing competitor product listings, pricing strategies, and customer reviews through scraping can inform businesses’ competitive strategies.
Product Improvement: Scraping allows businesses to gather feedback from customer reviews and product descriptions, aiding in product development and enhancement efforts.
II. Two Methods of Scraping Alibaba
In this project, we will cover two distinct methods for scraping Alibaba and extracting relevant data for analysis:
1. Using Puppeteer for Scraping:
We will demonstrate how to build a scraper using Puppeteer, a Node.js library that provides a high-level API for controlling headless Chrome or Chromium instances.
You will learn how to navigate through Alibaba’s website, interact with elements on the page, and extract relevant data such as product information, pricing, and supplier details.
The scraped data will be saved in a structured format that can be further processed and analyzed for insights.
2. Utilizing Crawling API and Cheerio for Scraping:
We will showcase an alternative approach to scraping Alibaba using the Crawling API in conjunction with Cheerio, a fast, flexible, and lean implementation of jQuery for the server.
This method will illustrate the advantages of using a dedicated Crawling API for web scraping tasks, including handling blocks, CAPTCHAs, and managing requests efficiently.
You will understand how to set up and utilize the Crawling API to fetch data from Alibaba’s website and parse it using Cheerio to extract relevant information.
A comparison between the Puppeteer-based approach and the Crawling API approach will be provided to highlight the differences and advantages of each method, emphasizing the superior performance and reliability of using the Crawling API for web scraping tasks.
By the end of this blog, you will have a deep understanding of how to scrape Alibaba effectively using both Puppeteer and Crawling API with Cheerio. This will allow you to select the most suitable approach based on your specific requirements and preferences.
III. What can you extract from Alibaba?
Before diving into the coding process, it’s crucial to familiarize ourselves with the structure of the HTML page of Alibaba’s Search Engine Results Page (SERP). By examining the HTML markup, we can identify the key elements necessary for extracting the following details programmatically. For the sake of this blog, we will use this Alibaba URL as an example.
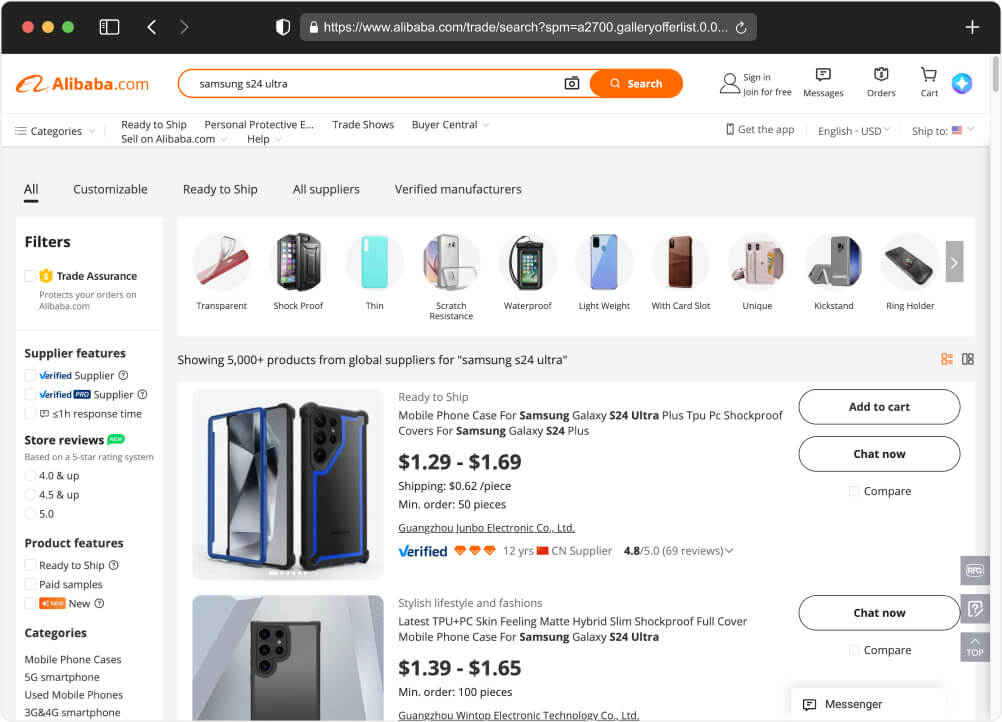
To locate the data we want to scrape in the HTML code, we’ll need to inspect the elements on the page using your web browser’s developer tools. Here’s a general guide on where you might find each piece of information:
Titles: Typically, the titles of products are contained within
<h3>,<h4>, or similar heading tags within the product listings.Price: Prices are often found within specific
<div>,<span>, or<p>elements with a class or ID that indicates they contain price information.
i. URL: The URLs of the product listings are usually contained within<a>(anchor) tags, commonly in the href attribute.Product Images: Images are typically located within
<img>tags, and the src attribute of these tags holds the URL of the image.Store Name: Store names can be found within specific elements such as
<div>,<span>, or<a>tags, often with a class or ID indicating they contain store information.Store Link: Similar to the product URLs, store links are usually contained within
<a>tags, typically in the href attribute.Minimum Item: Information about minimum order quantities may vary in its location within the HTML code. Look for specific elements or text that indicate minimum order requirements.
Number of Results: This information is often displayed at the top or bottom of the search results page and may be within a
<div>or other container with a unique identifier.
Once you identify the relevant HTML elements containing the data you need, you’ll need to write code that selects these elements based on their structure, class names, IDs, or other attributes, and then retrieves the text or attribute values from those elements. We’ll show you how it’s done on the next part of this blog.
IV. Scraping using Puppeteer
In this section, we will guide you on how to use Puppeteer for scraping Alibaba’s SERP. First, we need to set up a Node.js project and install the Puppeteer package. Follow the steps below:
- Create a new directory for your project:
mkdir alibaba-serp-scraper |
This command will create an empty folder named alibaba-serp-scraper.
- Navigate into the newly created directory:
cd alibaba-serp-scraper && npm i puppeteer |
By using this command we will navigate in the directory and install the puppeteer package including its dependencies into your project..
- Create a new JavaScript file named index.js where we’ll write the scraper’s code:
touch index.js |
This command creates an empty index.js file in the project directory where you can write your Puppeteer scraper code.
Now that we have set up our project and installed Puppeteer, we can proceed to write the scraper code in the index.js file to extract data from Alibaba’s SERP.
Study the code below and copy it into your index.js file:
// Import required modules |
Execute the above code by using a simple command:
node index.js |
This should provide you with the JSON data in an easily readable structure.
{ |
V. Why Use Crawlbase
When scraping websites, you may encounter bot detection measures, leading to your scraper being blocked eventually. To mitigate this risk, it’s essential to hide your real IP address. While using a pool of proxies may get the job done, building and managing such a system on your own can be time-consuming and costly. This is where the Crawling API comes into play.
Crawlbase’s Crawling API is built on top of millions of Datacenter and Residential IPs, providing you with a diverse range of IP addresses to use for each request. This rotation of IP addresses helps avoid detection and enhances the scraping process. Additionally, the API is integrated with AI technology, enabling it to mimic basic human interaction with the target website effectively.
By utilizing the Crawling API, you can enhance your scraping capabilities, unblock websites, minimize the risk of blocks and CAPTCHAs, and ensure a smoother and more reliable scraping experience.
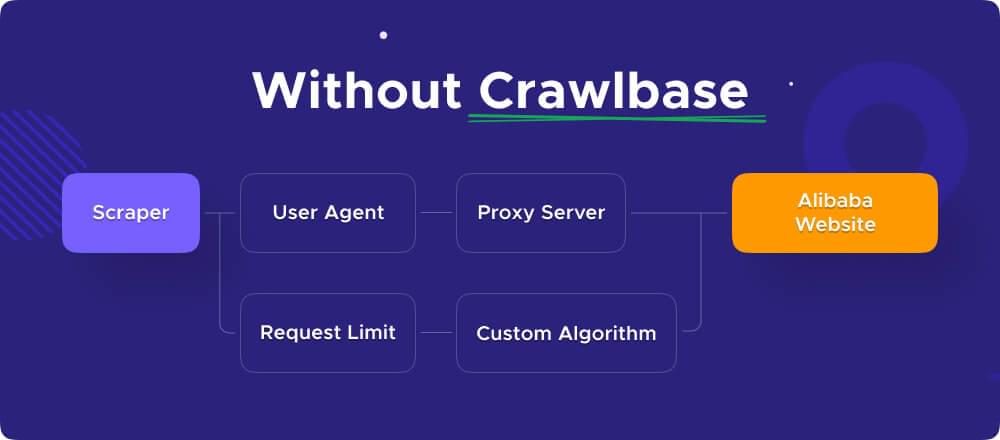
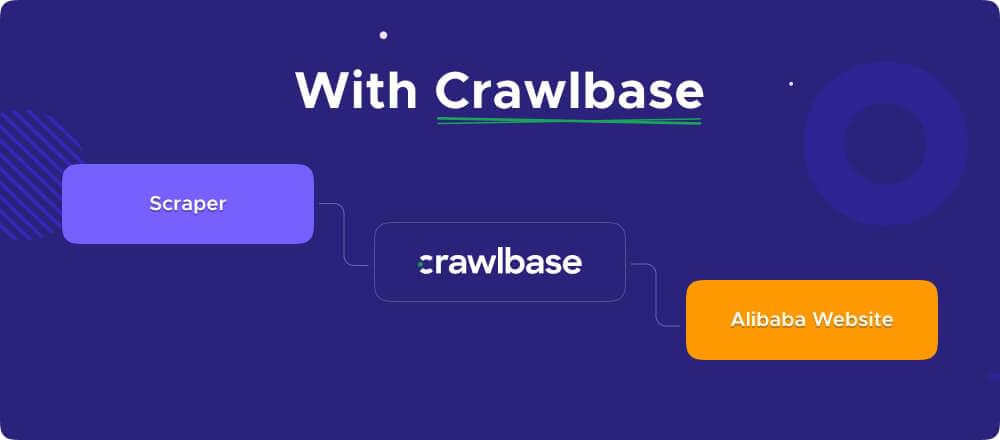
VI. Scrape using Crawling API and Cheerio
To utilize the Crawling API with the code we’re creating, the initial step is to sign up and obtain the API key. Follow these steps:
Sign Up for Crawlbase API: Start by signing up for the Crawlbase API. Navigate to their website and follow the registration process to create an account.
Obtain API Credentials: After registering, obtain your API credentials from your account documentation. These credentials are essential for making requests to the Crawling API service.
API Key and Secret: Your API credentials typically consist of an API key and a secret key. These credentials authenticate your requests to the Crawling API service.
Keep Credentials Secure: Ensure that you keep your API credentials secure, as they are a crucial part of the web scraping process. Avoid sharing them publicly or exposing them in your code.
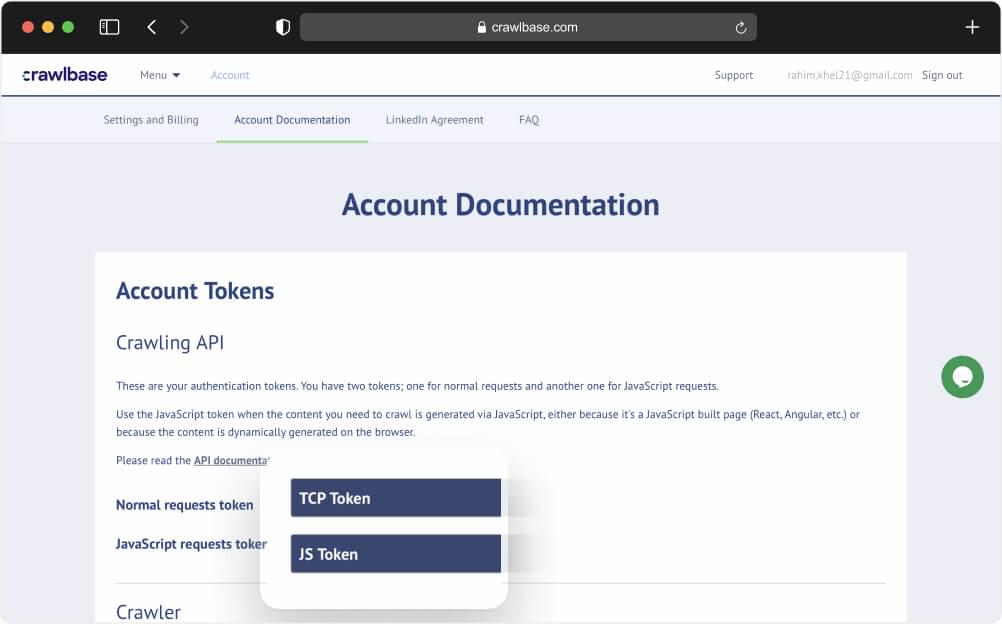
Once you have acquired the API tokens for the Crawling API, you can proceed with setting up the coding
environment using the following commands:
- Create a Directory: This command creates a new directory named
alibaba-serp-scraperwhere we’ll organize our project files.
mkdir alibaba-serp-scraper |
- Navigate to the Directory: Move into the newly created directory to perform further actions.
cd alibaba-serp-scraper |
- Create JavaScript File: This command creates a new JavaScript file named
index.jswhere we’ll write our scraping code.
touch index.js |
- Install Dependencies: This command installs the necessary dependencies, including
crawlbasefor interacting with the Crawling API and cheerio for parsing HTML.
npm install crawlbase cheerio |
Once done, you can now copy the code below and paste it in your index.js file. Make sure to study it first to understand each line.
// import Crawlbase Crawling API package |
Again, you can execute the code by using the command below:
node index.js |
This will provide a response in a readable JSON format structure.
{ |
VII. Conclusion
In conclusion, this blog has provided detailed insights into scraping Alibaba’s Search Result Page using two different approaches: Puppeteer and Crawling API with Cheerio. Both methods offer distinct advantages and considerations.
When using Puppeteer, you have direct control over a headless browser environment, allowing for dynamic interactions with web pages. This approach is suitable for scenarios where precise user interaction or complex JavaScript rendering is required.
On the other hand, utilizing the Crawling API with Cheerio offers a more robust and reliable solution for web scraping tasks. By utilizing a pool of rotating proxies and AI-powered capabilities, the Crawling API effectively avoids bot detection measures, minimizes the risk of blocks and CAPTCHAs, and enhances scraping performance.
For those seeking a more reliable and scalable scraper, integrating the Crawling API should be the preferred choice. It provides the necessary infrastructure and features to ensure uninterrupted scraping operations while maintaining data integrity and compliance.
Moreover, the code provided in this documentation serves as a valuable resource for enhancing your scraping knowledge beyond just Alibaba. You are free to adapt and extend the code to scrape data from various websites, allowing you to extract valuable insights for your projects and business needs.
Whether you opt for Puppeteer or the Crawling API with Cheerio, this article equips you with the tools and knowledge to develop effective scraping solutions and unlock the potential of web data for your endeavors.
If you want to check more blogs like this one, we recommend checking the following links:
How to Scrape Best Buy Product Data
How to Scrape Stackoverflow
How to Scrape Target.com
How to Scrape AliExpress Search Page
Should you have questions or concerns about Crawlbase, feel free to contact the support team.
VIII. Frequently Asked Questions
Q. Can I use other programming languages to integrate the Crawling API and build my scraper?
A. Yes, you have the flexibility to use a variety of programming languages and parsing libraries to integrate the Crawling API and construct your scraper. While Puppeteer and Cheerio were demonstrated in this documentation as examples of how to scrape Alibaba’s Search Result Page, they are not the only tools available for web scraping tasks. Python, for instance, offers popular libraries such as BeautifulSoup, Scrapy, and Requests, which are widely used for scraping and parsing HTML content.
Q. Does Crawlbase have its own scraper?
A. Yes, Crawlbase offers a built-in scraper through its Scraper API. By changing the endpoint of your API requests to https://api.crawlbase.com/scraper, you can receive the parsed response directly from the API. This product is especially useful for users who prefer a simpler approach to web scraping, as it eliminates the need to manually parse the HTML content. However, it’s important to note that the autoparse feature may not be suitable for all websites, as the supported websites are limited.
If you’re interested in seeing the power of the Scraper API in action, we recommend checking out this blog post: Scraping Bing Search Results with Scraper API. The blog demonstrates a comparison between using Puppeteer and utilizing the Scraper API to scrape Bing search results, showcasing the efficiency and effectiveness of the Scraper API in various scraping scenarios.