How to Scrape Google News using Smart Proxy.

This blog is originally posted to the crawlbase blog.
Google News, a dynamic aggregator, compiles articles globally for a comprehensive view. It’s a hub for real-time updates with curated news, personalized feeds, and trending topics. This personalized news aggregator highlights relevant stories based on user interests. An essential feature is “Full Coverage,” presenting diverse perspectives. As the 6th most popular news site in the US, Google News attracts over 370 million monthly visitors, making it a globally influential platform for scraping insights, tracking trends, and extracting valuable data efficiently.
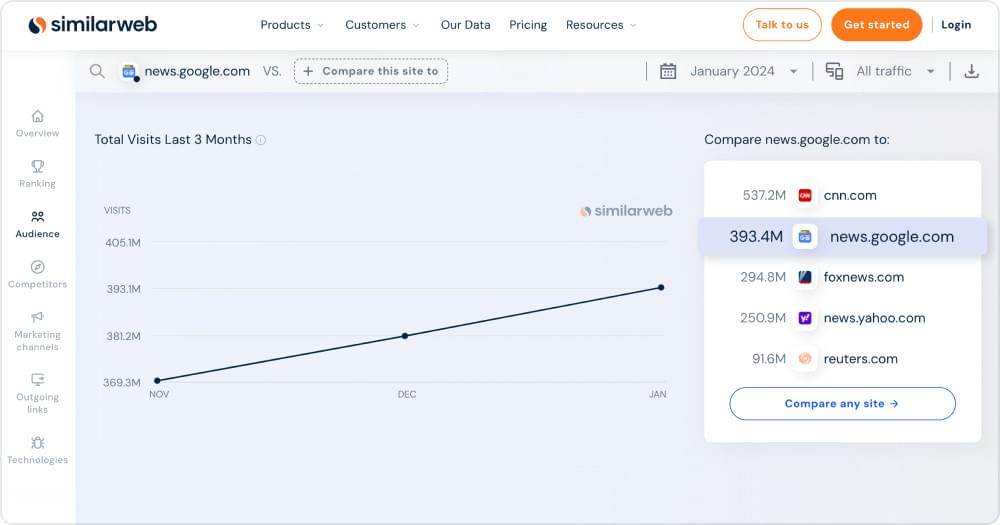
In this blog, we’ll learn how to scrape Google News using Crawlbase’s Smart Proxy. By using JavaScript and the Smart Proxy, we collect datasets like article titles, URLs, publication dates, summaries, author info and much more. Smart Proxy offers features like IP rotation, a pool of proxies including data center and residential, ensuring efficient scraping while maintaining anonymity. With Smart Proxy, scraping Google News becomes easier, letting us get valuable info while keeping things anonymous.
To start scraping Google News data immediately, click here.
Table of Contents
[What Data Can You get from Google News Scraping?](#What-Data-Can-You-get-from-Google-News-Scraping)
Node.js Installed on Your Computer
Basics of JavaScript
Crawlbase API Token
Scraping Google News - HTML Data
Step 1: Make a New Project Folder
Step 2: Go to Project Folder
Step 3: Create JavaScript File
Step 4: Add Crawlbase Package
Step 5: Install Axios
Step 6: Install Fs
Step 7: Write JavaScript Code
Scraping Google News Using Cheerio and Fs - JSON Data
Step 1: Install Cheerio
Step 2: Import required libraries
Step 3: Scrape Articles headlines
Step 4: Scrape Article Publisher
Step 5: Scrape Article Time
Step 6: Scrape Article Authors
Step 7: Complete Code
Why Scrape Google News?
Scraping Google News is really useful for both people and businesses. It gives a lot of helpful information and chances for different needs. Google News is a lively platform for getting quick updates on many different subjects. Google News collects information from lots of sources, giving users a full look at what’s happening now. Here are several reasons why scraping Google News is advantageous:
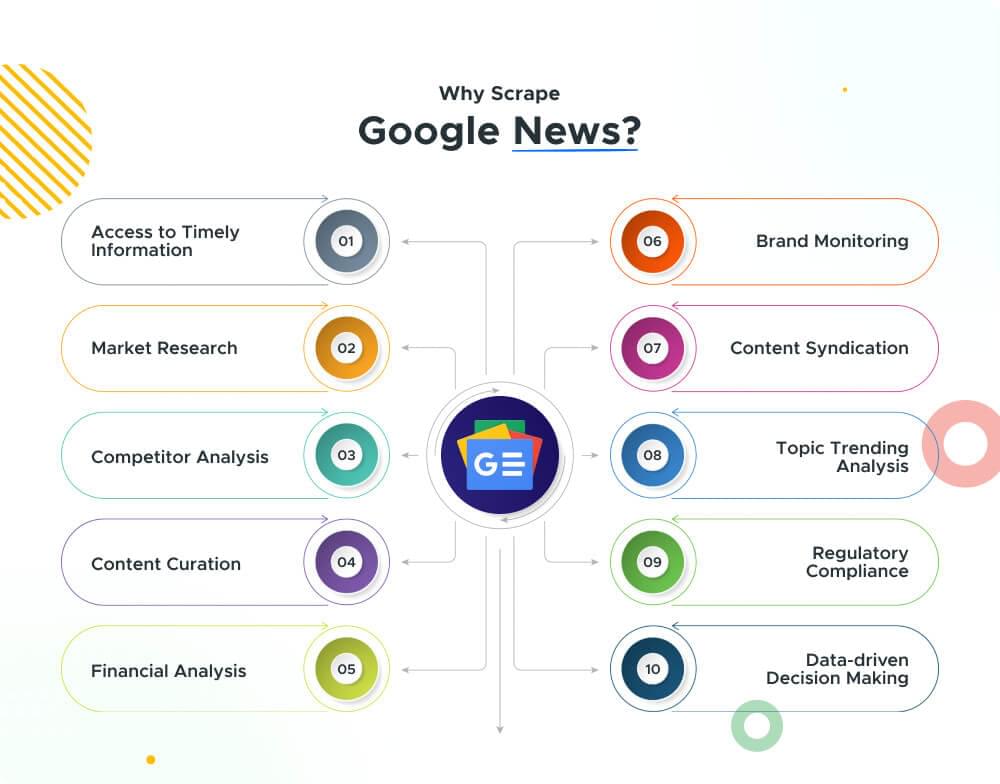
Access to Timely Information: Google News aggregates news articles from thousands of sources worldwide, ensuring access to a diverse range of current events, updates, and developments across different industries and regions.
Market Research: Scraping Google News enables businesses to gather intelligence on market trends, consumer preferences, competitor activities, and industry news. This information can inform strategic decision-making, product development, and marketing strategies.
Competitor Analysis: By monitoring news coverage related to competitors, businesses can gain insights into their strategies, product launches, partnerships, and public perception. This competitive intelligence helps organizations stay ahead in the market and identify areas for improvement.
Content Curation: Media outlets, bloggers, and content creators can use scraped news articles to curate relevant and engaging content for their audiences. This can enhance website traffic, engagement, and brand credibility by providing valuable insights and perspectives.
Financial Analysis: Scraping financial news from Google News allows investors, analysts, and financial institutions to stay informed about market trends, company performance, mergers and acquisitions, regulatory changes, and economic indicators. This information supports investment decisions, risk management, and portfolio optimization.
Brand Monitoring: Businesses can monitor news mentions and media coverage related to their brand, products, and key executives. This helps in reputation management, crisis communication, and understanding public sentiment towards the brand.
Content Syndication: Publishers and media organizations can use scraped news content to syndicate articles across their platforms, expand their content offerings, and attract a broader audience. This can increase website traffic, ad revenue, and brand visibility.
Topic Trending Analysis: Scraping Google News allows researchers, journalists, and marketers to analyze trending topics, keywords, and themes across different industries and regions. This insights can inform content creation, SEO strategies, and marketing campaigns.
Regulatory Compliance: Certain industries, such as finance and healthcare, require organizations to stay informed about regulatory changes, policy updates, and legal developments. Scraping news from reliable sources like Google News helps ensure compliance with industry regulations.
Data-driven Decision Making: By scraping and analyzing news articles, businesses can make data-driven decisions based on real-time information, market trends, and emerging opportunities or threats.
What Data Can You get from Google News Scraping?
Before you start scraping Google News page, it’s essential to check how the information is arranged in the HTML structure. This is important for creating a Google news scraper that can get the data we want in a quick and accurate way. Let’s start by looking at the Google News Page and figuring out how its HTML is organized. Our aim is to find the important parts that have the data we want to scrape from Google News Page.
We want to scrape following kinds of datasets from the Google News Page:

Article Titles and Headlines: Scraping Google News allows you to collect the titles and headlines of articles displayed on the platform. These titles provide a snapshot of the latest news topics and trending stories across various categories and topics.
Article URLs: Extracting URLs of news articles enables you to access the full content of the articles directly from the source publication. This allows for further analysis, content aggregation, or archiving of news articles for reference purposes.
Publication Dates: Scraped data often includes the publication dates of news articles, which can provide valuable insights into the temporal distribution of news coverage. Analyzing publication dates allows for trend tracking and understanding the timeline of events.
Article Summaries: Some news articles displayed on Google News include summaries or snippets that provide a brief overview of the article’s content. Scraping these summaries can offer concise descriptions of news topics and help in understanding the main points of an article without accessing the full content.
Author Information: Scraping author names or bylines from news articles allows you to analyze the contributors to various news sources. Understanding the authors behind the articles can provide insights into their writing styles, areas of expertise, and affiliations.
Article Content: While scraping article content directly from Google News may be restricted by copyright or terms of service, some scraping methods may allow for extracting the full text of news articles from the source publications. Analyzing article content provides in-depth insights into news stories, opinions, and analyses.
Metadata and Tags: Google News often includes metadata and tags associated with articles, such as categories, topics, and keywords. Scraping these metadata elements allows for organizing and categorizing scraped data based on various criteria, facilitating further analysis and interpretation.
Prerequisites
Now that we understand what type of data we scrape from the target page, let’s get ready for coding by setting up our development environment. Here’s what you need:
- Node.js Installed on Your Computer:
Node.js is like a tool that helps run JavaScript code outside of a web browser.
Installing it lets you run JavaScript applications and tools directly on your computer.
It gives you access to a bunch of useful packages and libraries through npm (Node Package Manager) to make your coding work easier.
- Basics of JavaScript:
JavaScript is a programming language often used in web development.
Learning the basics involves understanding things like how the code is written, different types of data, variables, how to do things repeatedly (loops), and making decisions (conditionals).
Knowing JavaScript well allows you to change what’s on a web page, talk to users, and do various tasks in web applications.
- Crawlbase API Token:
Begin by signing up for a free Crawlbase account to get your Smart Proxy token. Next, go to the Crawlbase Smart Proxy Dashboard and find your free access token in the ‘Connection details’ section.
Crawlbase API Token is a unique identifier granting access to Crawlbase’s web crawling and scraping APIs.
Necessary for authenticating and authorizing requests when using Crawlbase’s Crawling API for scraping tasks.
Acts as a proxy username, simplifying integration into your application.
Must be included in proxy calls, making requests to
http://smartproxy.crawlbase.comand port8012.Essential for secure communication between your application, Smart Proxy, and Crawling API.
Scraping Google News - HTML Data
Now that we’ve set up our coding environment, let’s start writing the JavaScript code to crawl the Google News Page. We’ll use Crawlbase’s Smart Proxy to quickly get the HTML content of the target page.
Step 1: Make a New Project Folder:
Open your terminal and type mkdir google-news-scraper to create a fresh project folder.
mkdir google-news-scraper
Step 2: Go to Project Folder:
Enter cd google-news-scraper to go into the new folder, making it easier to manage your project files.
cd google-news-scraper
Step 3: Create JavaScript File:
Type touch scraper.js to make a new file called scraper.js (you can choose another name if you want).
touch scraper.js
Step 4: Add Crawlbase Package:
Type npm install crawlbase to install the Crawlbase tool for your project. This tool helps you connect to the Crawlbase Crawling API, making it simpler to collect info from Google News.
npm install crawlbase
Step 5: Install Axios:
npm install axios
Step 6: Install Fs:
npm install fs
Step 7: Write JavaScript Code:
Now that you have your API credentials and Crawlbase Node.js library for web scraping installed, let’s start working on the “scraper.js” file. Choose the Google News page you want to get data from. In the “scraper.js” file, we use Crawlbase Smart Proxy, Axios and fs library to scrape data from your chosen Google News page. Remember to replace the placeholder URL in the code with the actual URL of the page you intend to scrape.
const axios = require('axios'), |
Code explanation:
This JavaScript code is a simple example of using the Axios library to make an HTTP GET request to a specified URL, with the twist of utilizing Crawlbase Smart Proxy for enhanced and large-scale web scraping. Let’s break down the code:
- Import Libraries:
axios: A popular library for making HTTP requests.https: Node.js module for handling HTTPS requests.fs: Node.js module for file system operations.
const axios = require('axios'), |
- Set User Token and Target URL:
username: Your user token for authentication.url: The URL of the Google News page you want to scrape.
const username = 'user_token', |
- Create Proxy Agent:
agent: Sets up a proxy agent using Crawlbase Smart Proxy.host: The proxy host from Crawlbase.port: The proxy port, often 8012.auth: Your username for authentication.
const agent = new https.Agent({ |
- Set Axios Configuration:
axiosConfig: Configures Axios to use the created proxy agent.
const axiosConfig = { |
- Make HTTP GET Request:
axios.get: Sends an HTTP GET request to the specified URL using the configured proxy.
axios |
This code fetches the HTML content of a specified URL using Axios and saves the response to a local file named “response.html.” The proxy configuration with Crawlbase Smart Proxy helps in handling the request through a rotating IP address, enhancing web scraping capabilities.
HTML Output:
Scraping Google News Using Cheerio and Fs - JSON Data
Step 1: Install Cheerio:
npm install cheerio
Step 2: Import required libraries:
const fs = require('fs'), |
Step 3: Scrape Google News Articles headlines:
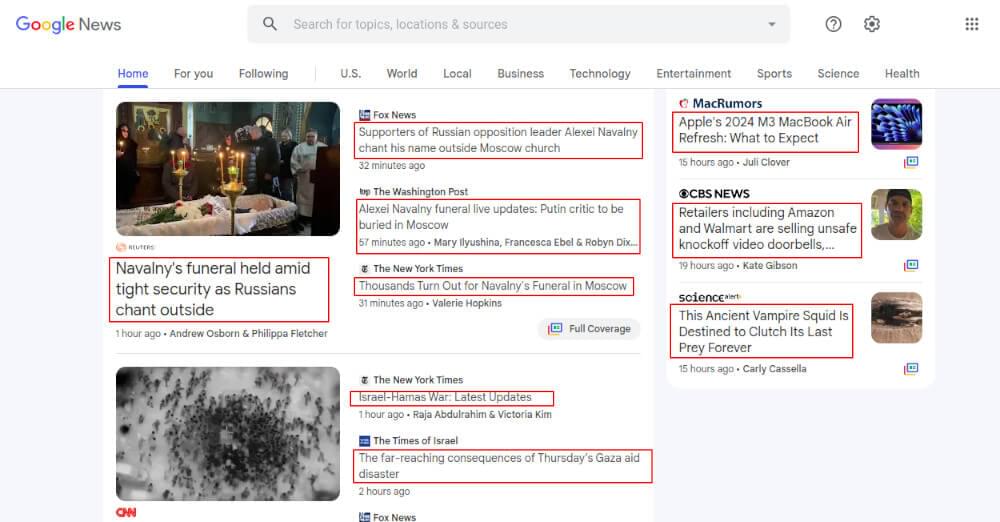
To scrape article headlines, inspect the webpage using browser developer tools to identify the container for each article. Identify the HTML element within the container that represents the article headline. Use Cheerio selectors, such as .find(), to target this element based on its class. Apply the .text() method to extract the textual content and utilize .trim() for clean results.
function scrapeData(articleElement) { |
Step 4: Scrape Google News Article Publisher:
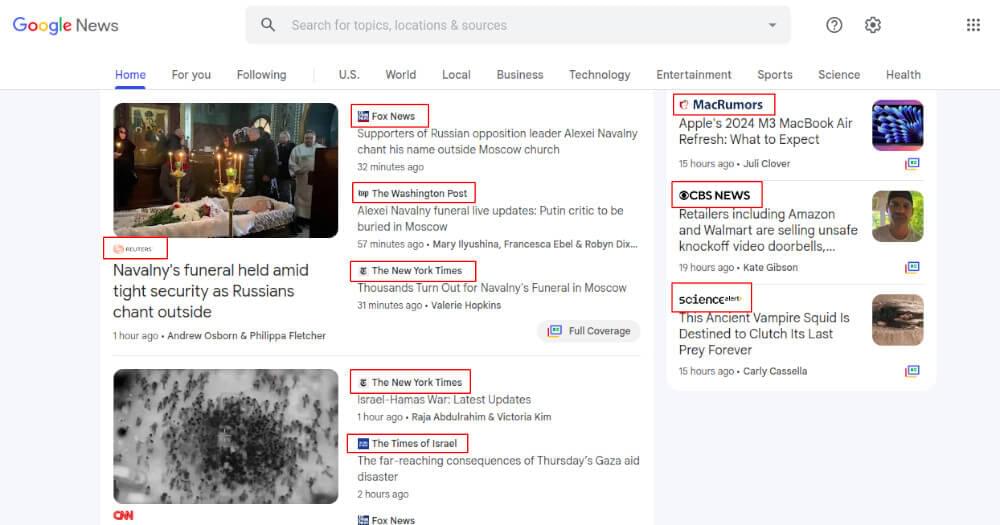
Similarly, find the part of the webpage displaying the article’s publisher. Right-click and inspect to view the source. Identify the HTML element containing the publisher’s name, then use Cheerio to extract and assign this text to the publisher variable. This step ensures capturing the publisher’s name accurately from the webpage.
const publisher = articleElement.find('.vr1PYe').text().trim(); |
Step 5: Scrape Google News Article Time:
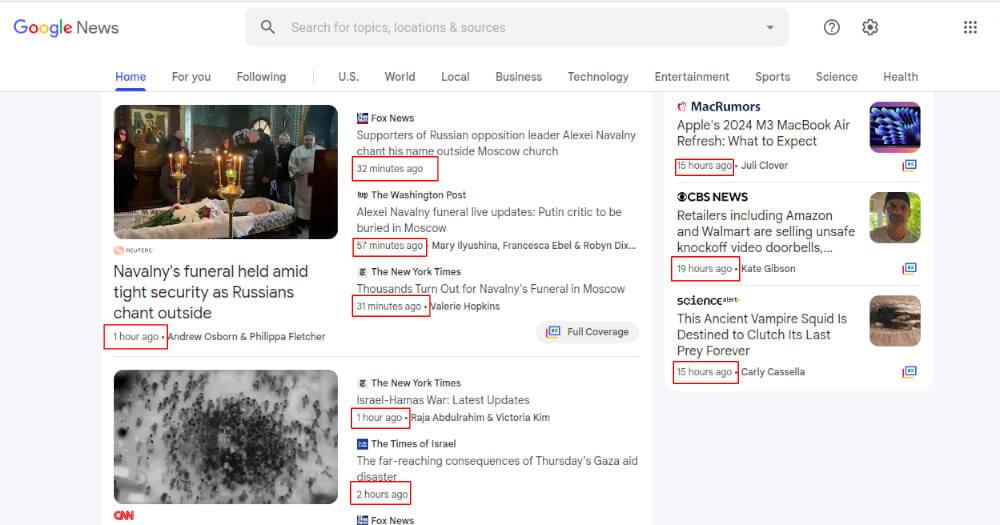
To find the article publish time, inspect the webpage source and identify the relevant element. Then, utilize Cheerio’s find method to target the text content within a <time> element with class “hvbAAd” in each article. The text method extracts this content, and trim removes any extra whitespace. The cleaned text is stored in the time variable for accurate time extraction.
const time = articleElement.find('time.hvbAAd').text().trim(); |
Step 6: Scrape Google News Article Authors:
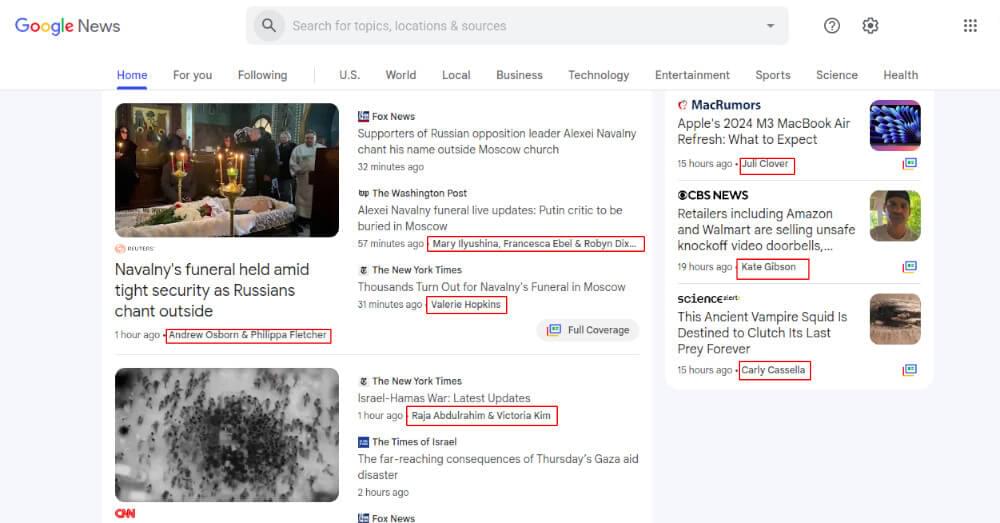
To extract article authors, identify unique classes, IDs, or attributes indicating authors in the HTML markup. Examine how author names are presented on the webpage. The provided code snippet is tailored to gather author names from a Google News webpage’s HTML source.
const authors = articleElement.find('.bInasb span[aria-hidden="true"]').text().trim(); |
Step 7: Complete Code:
Here is the entire code. Feel free to copy and save it on your machine.
const fs = require('fs'), |
JSON Output:
[ |
Conclusion
This comprehensive guide gives you all you need to scrape data from Google News using JavaScript and Crawlbase Smart Proxy. It covers scraping article headlines, publishers, publish times, and author names. Whether you’re new to web scraping or have some experience, these web scraping tips make it easier to extract data effectively. You can adapt the code to scrape data from other sites, helping you get actionable information for your projects.
Explore additional scraping guides:
How to Scrape Realtor.com - Extract Real Estate Data
How to Scrape Samsung Products
How to Scrape Google Scholar Results
How to Scrape Apple App Store Data
How to Scrape Yellow Pages Data
Frequently Asked Questions
What is Smart Proxy?
Smart Proxy by Crawlbase is an advanced solution for web crawling, offering a dynamic and intelligent proxy network. Unlike traditional proxies, Smart Proxy utilizes AI and machine learning to navigate through IP rotation effectively, evading blocks and CAPTCHAs. It enables users to access millions of IPs seamlessly, ensuring anonymity and preventing bans. With features like unlimited bandwidth, custom geolocation, and a mix of data center and residential proxies, it simplifies proxy management, making it an ideal choice for efficient, secure, and unrestricted data extraction from the web.
Is it legal to scrape Google News with Smart Proxy?
Google News operates as a news aggregator, with content owned by individual creators. According to Google’s terms of service, scraping publicly available factual information is generally legal, considering it falls under common knowledge. However, users must avoid reproducing or distributing copyrighted data. Crawlbase’s Smart Proxy aids in lawful scraping by efficiently navigating through rotating IP addresses, ensuring access to data without violating copyright. It enhances anonymity, compliance, and security, making it a valuable tool for ethically collecting information from Google News.
Does Smart Proxy guarantee 100% success in scraping Google News?
While Crawlbase’s Smart Proxy enhances success rates with its rotating IP addresses, AI, and machine learning techniques, it cannot guarantee 100% success in scraping Google News. Success depends on various factors, including website changes, anti-scraping measures, and compliance with Google’s terms. Smart Proxy significantly improves efficiency and reduces the likelihood of blocks or CAPTCHAs, providing a powerful tool for web scraping. Users should, however, monitor and adjust their scraping strategies to accommodate any changes in the target website’s structure or policies.
Can I use Smart Proxy for scraping other websites besides Google News?
Absolutely! Crawlbase’s Smart Proxy is versatile and can be used for scraping various websites beyond Google News. Its dynamic IP rotation and AI-driven features make it effective in navigating through different platforms, ensuring efficient data extraction while avoiding blocks and bans. Whether for market research, competitor analysis, or any web scraping needs, Smart Proxy provides a secure and scalable solution for accessing and collecting data from diverse online sources.
How do I integrate Smart Proxy into my web scraping script for Google News?
Integrating Smart Proxy into your web scraping script for Google News involves configuring your script to route requests through Smart Proxy’s rotating IP addresses. Instead of directly connecting to Google News, your script sends requests to Smart Proxy, which, in turn, forwards them to the Crawling API. The intelligent proxy handles authorization using your private access token, enhancing anonymity and reducing the risk of blocks or CAPTCHAs. Ensure that your script supports HTTP/S-based APIs, and use Smart Proxy’s designated URL and port with your access token for seamless integration. This way, your web scraping activities benefit from enhanced security, efficiency, and compliance with web scraping regulations.




