How to Scrape Google Scholar Results

This blog is originally posted to the Crawlbase blog.
Google Scholar has become a cornerstone for researchers, academics, and students seeking scholarly articles, papers, and academic resources. Launched in 2004, Google Scholar emerged as a specialized search engine that focuses on academic publications, providing a vast repository of scholarly knowledge across various disciplines. Over the years, it has become an invaluable tool, offering access to a wealth of academic content, including journals, conference papers, theses, and more.
With millions of users globally, Google Scholar plays a pivotal role in facilitating academic research, helping individuals stay updated on the latest advancements and discoveries within their fields of interest. In this blog, we will guide you on how you can scrape research papers with google scholar scraper with Python.
If you want to head right into the first step to scrape google scholar, click here.
Table Of Contents
What can you Scrape from Google Scholar?
Potential Use Cases for Google Scholar Data
Installing Python and Essential Libraries
Selecting a Suitable Development IDE
Utilizing Python’s Requests Library
Examining Google Scholar’s HTML Structure
Parsing HTML with BeautifulSoup
Limitations and Challenges of the Common Approach
Crawlbase Registration and API Token
Interacting with the Crawling API Using Crawlbase Library
Scrape Google Scholar SERP Results
Handling Pagination
Saving the Extracted Data in SQLite
Why Scrape Google Scholar SERP?
Web scraping Google Scholar SERP offers numerous benefits to researchers seeking academic information.
Access to a Wealth of Academic Information
By scraping Google Scholar SERP, researchers gain access to an exhaustive database of scholarly articles. This vast wealth of information allows them to explore a breadth of research and perspectives, enriching their understanding of their field of study.
Furthermore, accessing this wealth of academic information can also lead to serendipitous discoveries. Researchers may stumble upon relevant articles or studies that they were not initially seeking, opening up new avenues for exploration and potential breakthroughs in their research.
Enhancing Research Efficiency
Manual searching through countless pages of search results on Google Scholar SERP can be a time-consuming task. With web scraping, however, researchers can automate the process, saving valuable time and enabling them to focus on analyzing the retrieved data. This improved efficiency opens up new possibilities for collaboration and innovation.
Moreover, the enhanced research efficiency achieved through web scraping Google Scholar SERP can also lead to a more systematic and comprehensive literature review. Researchers can gather a larger volume of relevant articles and studies in a shorter amount of time, allowing them to synthesize information more effectively and make well-informed decisions in their own research projects.
What can you Scrape from Google Scholar?

Citation Metrics: Google Scholar provides citation metrics for scholarly articles, offering insights into the impact and relevance of a publication. Scraping these metrics allows researchers to identify influential works within a specific field.
Author Information: Extracting data on authors, their affiliations, and collaboration networks helps in understanding the academic landscape. It facilitates tracking the contributions of specific researchers and discovering potential collaborators.
Publication Details: Scrape details such as the publication date, journal, conference, or book source. This information aids in assessing the recency and credibility of scholarly works.
Abstracts and Keywords: Extracting abstracts and keywords provides a snapshot of the content of scholarly articles. This data is crucial for quickly gauging the relevance of a publication to specific research interests.
Link to Full Text: Direct links to the full text of scholarly articles are often available on Google Scholar. Scraping these links enables users to access the complete content of relevant publications.
Related Articles: Google Scholar suggests related articles based on content and citations. Scraping this data provides researchers with additional sources and perspectives related to their area of interest.
Author Profiles: Google Scholar creates profiles for authors, showcasing their publications and citation metrics. Extracting this data allows for a comprehensive understanding of an author’s body of work.
Potential Use Cases for Google Scholar Data
Scraping Google Scholar SERP results opens up numerous possibilities for academic and research-oriented information.
Here are some potential use cases for the extracted data:

Academic Research: Researchers and scholars can utilize the scraped data to analyze academic trends, identify key contributors in specific fields, and explore the distribution of scholarly content.
Citation Analysis: The data can be employed to conduct citation analyses, helping researchers understand the impact and influence of academic publications within a particular domain.
Author Profiling: By extracting information about authors, their affiliations, and publication histories, the data can contribute to creating detailed profiles of researchers, aiding in academic networking and collaboration.
Trend Analysis: Scraped data allows for the identification and analysis of emerging trends within academic disciplines, helping researchers stay informed about the latest developments in their fields.
Institutional Research Assessment: Educational institutions can use the data to assess the research output of their faculty, track academic collaborations, and gauge the impact of their research activities.
Content Summarization: Natural Language Processing (NLP) techniques can be applied to the scraped abstracts and texts, enabling the creation of summaries or topic clusters for quick insights into research areas.
Educational Resource Development: The data can be valuable for educators looking to develop course materials, case studies, or reference lists, ensuring that educational content aligns with the latest academic literature.
Competitive Analysis: Academic institutions, publishers, or researchers can conduct competitive analyses by comparing publication volumes, citation rates, and collaboration networks within specific research domains.
Scientometric Studies: Scientometricians can utilize the data for quantitative analyses of scholarly publications, exploring patterns of collaboration, citation dynamics, and the evolution of research topics.
Decision-Making Support: Researchers and decision-makers can use the scraped data to inform strategic decisions, such as funding allocations, academic partnerships, and investment in specific research areas.
Setting Up Your Python Environment
Scraping Google Scholar SERP demands a well-configured Python environment. Here’s a step-by-step guide to get your environment ready for this data retrieval journey.
Installing Python and Essential Libraries
Begin by installing Python, the versatile programming language that will be the backbone of your scraping project. Visit the official Python website, download the latest version, and follow the installation instructions.
To streamline the scraping process, certain Python libraries are essential:
- Requests: This library simplifies HTTP requests, enabling you to fetch the HTML content of Google Scholar SERP pages.
pip install requests |
- BeautifulSoup: A powerful library for parsing HTML and extracting information, BeautifulSoup is invaluable for navigating and scraping the structured content of SERP pages.
pip install beautifulsoup4 |
- Crawlbase: For an advanced and efficient approach, integrating Crawlbase into your project brings features like dynamic content handling, IP rotation, and overcoming common scraping hurdles seamlessly. Visit the Crawlbase website, register, and obtain your API token.
pip install crawlbase |
Selecting a Suitable Development IDE
Choosing the right Integrated Development Environment (IDE) significantly impacts your coding experience. Here are a couple of popular choices:
PyCharm: PyCharm is a robust IDE developed specifically for Python. It provides features like intelligent code completion, debugging tools, and a user-friendly interface. You can download the community edition for free from the JetBrains website.
Jupyter Notebooks: Ideal for interactive data exploration and visualization, Jupyter Notebooks provide a user-friendly interface for code development and analysis.
Visual Studio Code: Known for its versatility and extensibility, Visual Studio Code offers a robust environment with features like syntax highlighting, debugging, and Git integration.
Whichever IDE you choose, ensure it aligns with your workflow and preferences. Now that your Python environment is set up, let’s proceed to explore the common approach for scraping Google Scholar SERP.
Common Approach for Google Scholar SERP Scraping
When embarking on Google Scholar SERP scraping with the common approach, you’ll leverage Python’s powerful tools to gather valuable data. Follow these steps to get started:
Utilizing Python’s Requests Library
While Google Scholar SERP scraping, the first step is to use the power of Python’s Requests library. This library simplifies the process of making HTTP requests to fetch the HTML content of the search results page. Let’s delve into the details using the example of a search query for “Data Science”.
import requests |
In this script, we start by defining our search query, and then we construct the URL for Google Scholar by appending the query. The requests.get() method is used to make the HTTP request, and the obtained HTML content is stored for further processing.
Run the Script:
Open your preferred text editor or IDE, copy the provided code, and save it in a Python file. For example, name it google_scholar_scraper.py.
Open your terminal or command prompt and navigate to the directory where you saved google_scholar_scraper.py. Execute the script using the following command:
python google_scholar_scraper.py |
As you hit Enter, your script will come to life, sending a request to the Google Scholar website, retrieving the HTML content and displaying it on your terminal.
Examining Google Scholar’s HTML Structure
When scraping Google Scholar, inspecting elements using browser developer tools is essential. Here’s how to identify CSS selectors for key data points:
Right-Click and Inspect: Right-click on the element you want to scrape (e.g., titles, authors, publication details) and choose “Inspect” from the context menu.
Use Browser Developer Tools: Browser developer tools allow you to explore the HTML structure by hovering over elements, highlighting corresponding code, and understanding the class and tag hierarchy.
Identify Classes and Tags: Look for unique classes and tags associated with the data points you’re interested in. For example, titles may be within
tags with a specific class.
Adapt to Your Needs: Adapt your understanding of the HTML structure to create precise CSS selectors that target the desired elements.
By inspecting elements in Google Scholar’s search results, you can discern the CSS selectors needed to extract valuable information during the scraping process. Understanding the structure ensures accurate and efficient retrieval of data for your specific requirements.
Parsing HTML with BeautifulSoup
Parsing HTML is a critical step in scraping Google Scholar SERP results. BeautifulSoup, a Python library, simplifies this process by providing tools to navigate, search, and modify the parse tree. Let’s Use BeautifulSoup to navigate and extract structured data from the HTML content fetched earlier.
Note: For the latest CSS selectors customized for Google Scholar’s HTML structure, refer to the previous step to learn how to identify CSS selectors.
import requests |
In this updated script, we use BeautifulSoup to locate and extract specific HTML elements corresponding to the position, title, link, description, and author information of each search result. We define a function parse_google_scholar that takes the HTML content as input and returns a list of dictionaries containing the extracted details. The main function demonstrates how to use this function for the specified search query.
Example Output:
[ |
Limitations and Challenges of the Common Approach
While the common approach using Python’s Requests library and BeautifulSoup is accessible, it comes with certain limitations and challenges that can impact the efficiency and reliability of scraping Google Scholar SERP results.
No Dynamic Content Handling
The common approach relies on static HTML parsing, which means it may not effectively handle pages with dynamic content loaded through JavaScript. Google Scholar, like many modern websites, employs dynamic loading to enhance user experience, making it challenging to capture all relevant data with static parsing alone.
No Built-in Mechanism for Handling IP Blocks
Websites, including Google Scholar, may implement measures to prevent scraping by imposing IP blocks. The common approach lacks built-in mechanisms for handling IP blocks, which could result in disruptions and incomplete data retrieval.
Vulnerability to Captchas
Web scraping often encounters challenges posed by captchas, implemented as a defense mechanism against automated bots. The common approach does not include native capabilities to handle captchas, potentially leading to interruptions in the scraping process.
Manual Handling of Pagination
The common approach requires manual handling of pagination, meaning you must implement code to navigate through multiple result pages. This manual intervention can be time-consuming and may lead to incomplete data retrieval if not implemented correctly.
Potential for Compliance Issues
Scraping Google Scholar and similar websites raises concerns about compliance with terms of service. The common approach does not inherently address compliance issues, and web scrapers need to be cautious to avoid violating the terms set by the website.
To overcome these limitations and challenges, a more advanced and robust solution, such as Crawlbase Crawling API, can be employed. Crawlbase offers features like dynamic content handling, automatic IP rotation to avoid blocks, and seamless pagination management, providing a more reliable and efficient approach to scraping Google Scholar SERP results.
Enhancing Efficiency with Crawlbase Crawling API
In this section, we’ll delve into how Crawlbase Crawling API can significantly boost the efficiency of your Google Scholar SERP scraping process.
Crawlbase Registration and API Token
To access the powerful features of Crawlbase Crawling API, start by registering on the Crawlbase platform. Registration is a simple process that requires your basic details.
To interact with the Crawlbase Crawling API, you need a token. Crawlbase provides two types of tokens: JS (JavaScript) and Normal. For scraping Google Scholar SERP results, the Normal token is the one to choose. Keep this token confidential and use it whenever you initiate communication with the API.
Here’s the bonus: Crawlbase offers the first 1000 requests for free. This allows you to explore and experience the efficiency of Crawlbase Crawling API without any initial cost.
Interacting with the Crawling API Using Crawlbase Library
The Python-based Crawlbase library seamlessly enables interaction with the API, effortlessly integrating it into your Google Scholar scraping endeavor. The following code snippet illustrates the process of initializing and utilizing the Crawling API via the Crawlbase Python library.
from crawlbase import CrawlingAPI |
For in-depth information about the Crawling API, refer to the comprehensive documentation available on the Crawlbase platform. Access it here. To delve further into the capabilities of the Crawlbase Python library and explore additional usage examples, check out the documentation here.
Scrape Google Scholar SERP Results
Let’s enhance the Google Scholar scraping script from our common approach to efficiently extract Search Engine Results Page (SERP) details. The updated script below utilizes the Crawlbase Crawling API for a more reliable and scalable solution:
from crawlbase import CrawlingAPI |
This updated script incorporates the Crawlbase Crawling API to ensure smooth retrieval of Google Scholar SERP results without common challenges like IP blocks and captchas.
Example Output:
[ |
Handling Pagination
When scraping Google Scholar SERP, handling pagination is crucial to retrieve a comprehensive set of results. Google Scholar uses the start query parameter to manage paginated results. Below is the modified script to incorporate pagination handling for an improved scraping experience:
from crawlbase import CrawlingAPI |
This modified script now efficiently handles pagination using the start query parameter, ensuring that all relevant results are retrieved seamlessly.
Saving the Extracted Data in SQLite
Once you have successfully extracted data from Google Scholar SERP, the next steps involve saving the information. To persistently store the scraped data, we can use an SQLite database. Here is an updated script that incorporates saving the results into an SQLite database.
import sqlite3 |
This script creates a database file named google_scholar_results.db and a table to store the extracted results. It then inserts each result into the database.
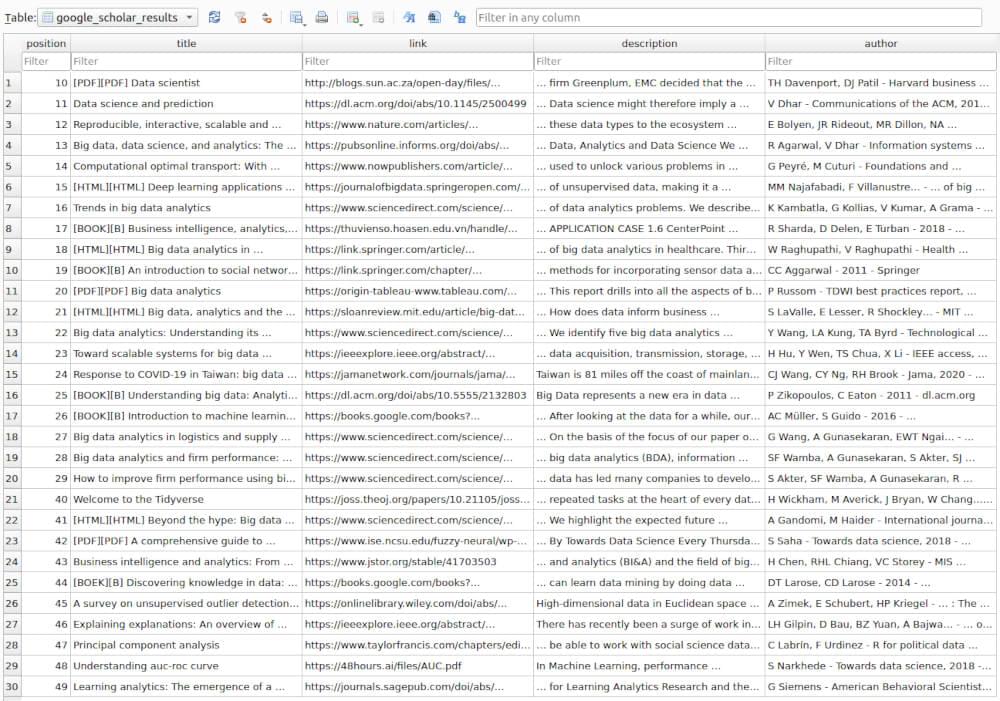
google_scholar_results Table Snapshot:
Final Thoughts
This guide shares essential tips for scraping Google Scholar search results using Python and the Crawlbase Crawling API. As you explore the world of web scraping, keep in mind that these skills can be applied not only to Google Scholar but also to various other platforms.
Explore our additional guides below to broaden your search engine scraping expertise.
📜 How to scrape Google Search Results
📜 How to scrape Bing Search Results
📜 How to scrape Yandex Search Results
We understand that web scraping can present challenges, and it’s important that you feel supported. Therefore, if you require further guidance or encounter any obstacles, please do not hesitate to reach out. Our dedicated team is committed to assisting you throughout your web scraping endeavors.
Frequently Asked Questions (FAQs)
Q: Is it legal to scrape Google Scholar?
Web scraping legality depends on the terms of service of the website. Google Scholar’s terms explicitly forbid scraping for commercial purposes. It is crucial to review and adhere to the terms of service and robots.txt file of any website to ensure compliance with legal and ethical guidelines. Always prioritize ethical scraping practices to maintain a positive online presence and avoid potential legal issues.
Q: How can I scrape Google Scholar data using Python?
To scrape Google Scholar data with Python, you can leverage the Requests library to make HTTP requests to the search results page. Utilizing BeautifulSoup, you can then parse the HTML to extract relevant information such as titles, links, authors, and more. For a more efficient and reliable solution, you can opt for Crawlbase’s Crawling API, which streamlines the process and provides enhanced features for handling complexities in web scraping.
Q: What are the common challenges when scraping Google Scholar SERP results?
Scraping Google Scholar SERP results can present challenges like handling pagination effectively to retrieve comprehensive data. Additionally, overcoming IP blocks, dealing with dynamic content, and maintaining compliance with ethical scraping practices are common hurdles. By implementing proper error handling and utilizing google scholar scraper like Crawlbase’s Crawling API, you can address these challenges more efficiently.
Q: Can I analyze and visualize the scraped Google Scholar data for research purposes?
Certainly! Once you’ve scraped Google Scholar data, you can save it in a database, such as SQLite, for long-term storage. Subsequently, you can use Python libraries like pandas for in-depth data analysis, allowing you to uncover patterns, trends, and correlations within the scholarly information. Visualization tools like Matplotlib or Seaborn further enable you to present your findings in a visually compelling manner, aiding your research endeavors.




