How to Scrape Realtor.com - Extract Real Estate Data

This blog is originally posted to crawlbase blog.
Realtor.com is a popular real estate website that helps people buy, sell, and rent properties. Realtor.com has a vast database of property listings. Its significance lies in the substantial search and traffic volumes it attracts. Many individuals looking for homes or real estate information use Realtor.com due to its user-friendly interface and comprehensive listings.
In this Blog, we will explore the process of scraping Realtor.com for real estate data using Python. We will cover everything from understanding the basics of web scraping to cleaning and organizing the extracted data. So let’s dive in and learn how to extract valuable information from Realtor.com!
Table Of Contents
Installing Python and Libraries
Choosing an IDE
Analyzing Realtor.com Property Page
Extracting data from a single property using Python
Utilizing Realtor.com’s search system for property discovery
Scraping property listings from a specific location
Realtor.com RSS feeds for tracking property changes
Writing a RSS feeds scraper to monitor changes
Crawlbase Crawling API for Anti-Scraping and Bypassing Restriction
Creating Realtor.com Scraper with Crawlbase Crawling API
1. Why Scrape Realtor.com?
Scraping Realtor.com provides real estate information, including property listings, sale prices, rental rates, and property features. This data serves as a valuable resource for staying updated on market trends and discovering investment opportunities.
Individuals leveraging Realtor.com scraping can dig into diverse real estate details, utilizing the data for market research, investment analysis, and identifying potential investment prospects.
In addition to accessing specific property data, scraping Realtor.com provides valuable insights into local real estate market dynamics. Analysis of property types, location preferences, and amenities empowers real estate professionals to adapt strategies according to evolving buyer and seller needs.
Real estate professionals can utilize historical data and monitor ongoing listings to comprehend market dynamics, supply and demand fluctuations, and pricing trends.
2. Project Setup
Before we dive into scraping Realtor.com, let’s set up our project to make sure we have everything we need. We’ll keep it simple by using the requests, beautifulsoup4, and lxml libraries for scraping.
Installing Python and Libraries
Python Installation:
If you don’t have Python installed, visit python.org to download and install the latest version.
During installation, make sure to check the box that says “Add Python to PATH” to easily run Python from the command line.
Library Installation:
Open your command prompt or terminal.
Type the following commands to install the necessary libraries:
pip install requests
pip install beautifulsoup4
pip install lxmlThis will install requests for handling web requests, beautifulsoup4 for parsing HTML, and lxml for parsing XML.
Choosing an IDE
Now that we have Python and the required libraries installed, let’s choose an Integrated Development Environment (IDE) to make our coding experience smoother. An IDE is a software application that provides a comprehensive set of tools for coding.
Popular IDEs:
There are various IDEs available, and some popular ones for Python are:
Visual Studio Code: Visual Studio Code is lightweight and user-friendly, great for beginners.
PyCharm: PyCharm is feature-rich and widely used in professional settings.
Jupyter Notebooks: Jupyter Notebooks are excellent for interactive and exploratory coding.
Installation:
Download and install your chosen IDE from the provided links.
Follow the installation instructions for your operating system.
Now that our project is set up, we’re ready to start scraping Realtor. In the next section, we’ll begin extracting data from a single property on Realtor.com.
3. Creating Realtor.com Scraper
In this section, we’ll roll up our sleeves and create a simple Realtor.com scraper using Python. Our goal is to analyze a property page on Realtor.com and extract valuable data.
Analyzing Realtor.com Property Page
When we want to scrape data from Realtor.com, the first thing we do is take a good look at how a property page is built. To kick things off, we’ll examine a specific property page – for instance, let’s consider below page:
Realtor.com - Property Listing
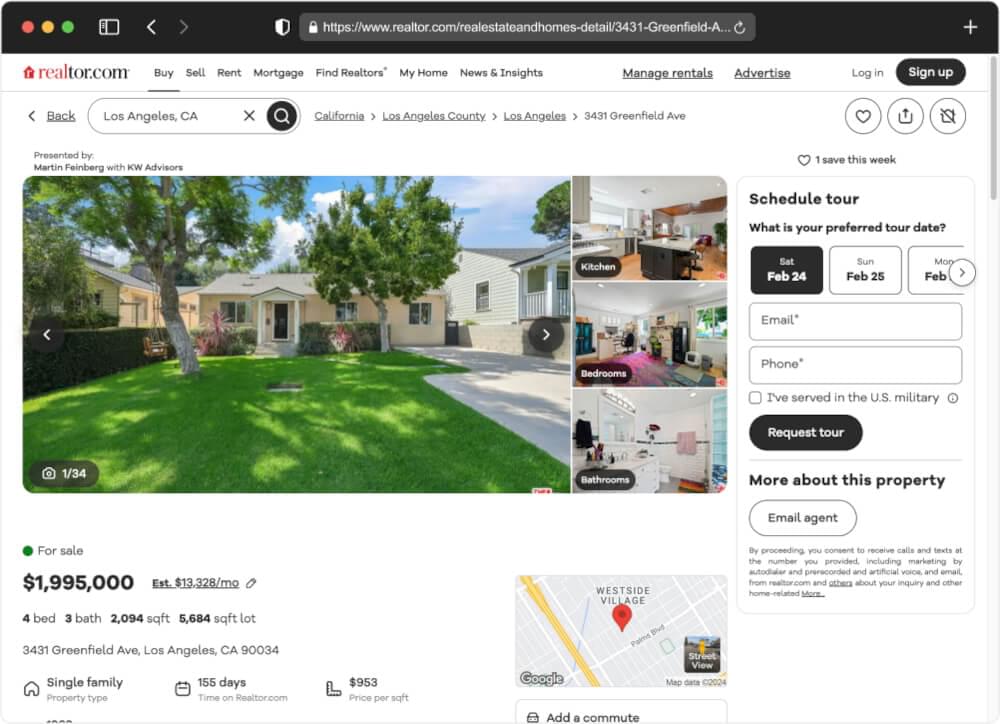
Simply right-click on the webpage in your browser and choose “Inspect”. This will reveal the Developer Tools, allowing you to explore the HTML structure. We explore the HTML, and what do we discover? A hidden script named __NEXT_DATA__.
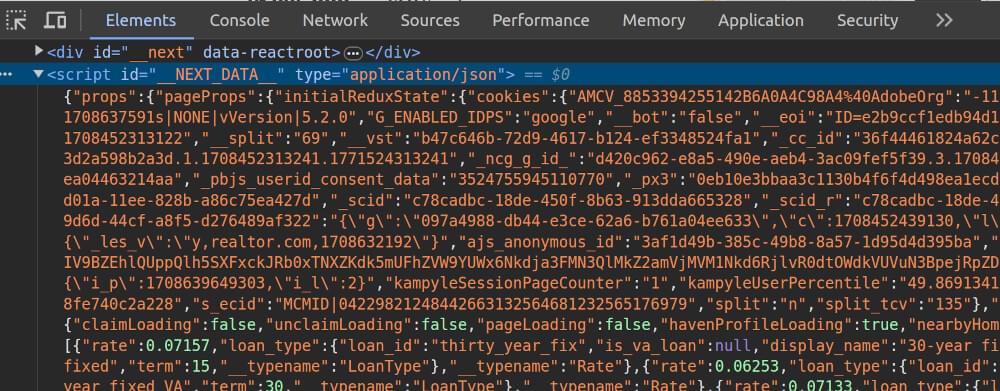
This script doesn’t just reveal the obvious things; it shares all the details, even the ones you might not notice at first glance. Now, let’s write a Python script to scrape this data from the Realtor.com property page.
Extracting Data from a Single Property Using Python
Now, let’s jump into some code to extract data from a single property page. We’ll use the beautifulsoup4 library for parsing HTML and requests for making HTTP requests.
import requests |
In our Python script, we’ve created a set of functions to efficiently navigate Realtor.com’s property pages. The make_request function politely requests data from the selected property’s URL using enhanced headers designed to mimic a web browser. The extract_data_from_script function delves into the script on the page, revealing hidden information. This information is then transformed into an understandable format by the parse_json function. The key function, scrape_realtor_property, coordinates these actions to uncover a wealth of real estate data. The main function, our central character, takes the spotlight, presenting the script’s discoveries. It’s a digital exploration, uncovering insights in Realtor.com’s web pages and poised to share these valuable findings.
Run the Script:
Open your preferred text editor or IDE, copy the provided code, and save it in a Python file. For example, name it realtor_scraper.py.
Open your terminal or command prompt and navigate to the directory where you saved realtor_scraper.py. Execute the script using the following command:
python realtor_scraper.py |
Example Output:
{ |
4. Finding Realtor.com Properties
Discovering properties on Realtor.com is streamlined through their search system. Let’s delve into how the search functionality operates on Realtor.com and explore the scraping process.
Utilizing Realtor.com’s Search System for Property Discovery
Realtor.com’s search system is a powerful tool that allows us to find properties based on various criteria, such as location, price range, and property type. Our goal is to leverage this system to fetch property listings efficiently.
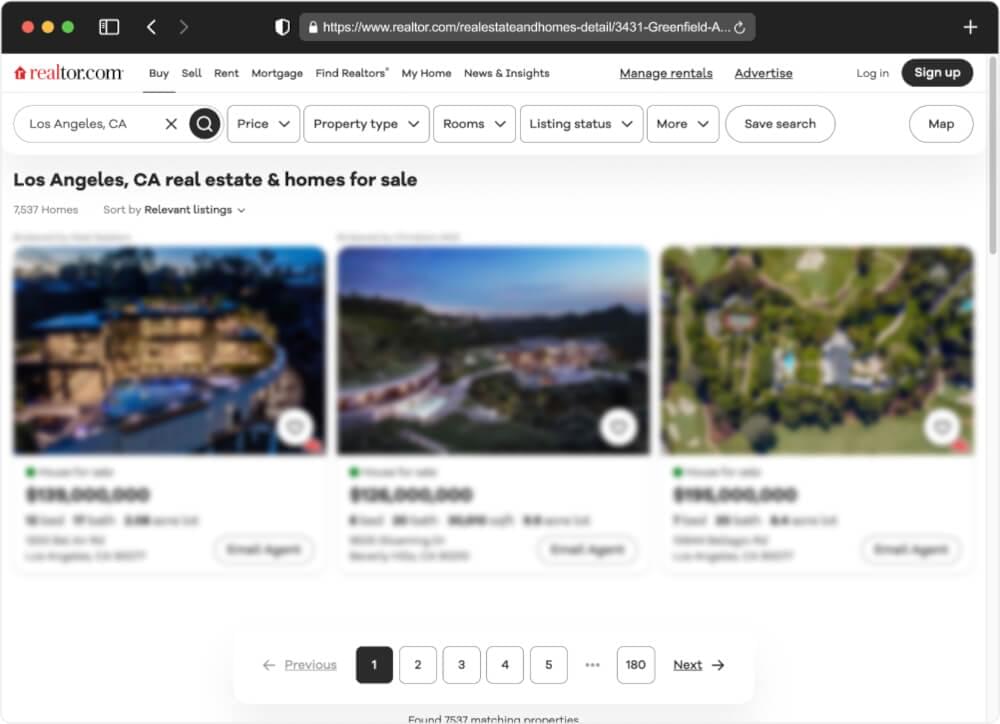
When we perform a search, the results page contains essential metadata, including the total number of pages and listings available in the specified area.
The URL structure for the search results follows a clear pattern, making it convenient for our scraper:
https://www.realtor.com/realestateandhomes-search/<CITY>_<STATE>/pg-<PAGE> |
Understanding this structure empowers us to design a scraper capable of extracting all property listings from a specified geographical location, leveraging variables like city and state.
Scraping Property Listings from a Specific Location
Let’s consider we want to scrape the data of properties in Los Angeles, California. To accomplish this, we have update the previous script and crafted a function named find_properties that takes a state and city as parameters. This function constructs the appropriate search URL, makes a respectful request to Realtor.com, and then parses the search results.
import requests |
Within the find_properties function, a loop iterates through the range of page numbers, dynamically constructing the search URL for each page using the provided state, city, and page number. For each URL, a respectful request is made using the make_request function, and the HTML content is parsed using beautifulsoup4. The hidden web data containing property information is then extracted and processed into structured JSON format with the parse_json function. The property previews from each page are appended to the search_results list, and the final dataset is returned.
Example Output:
[ |
5. Watching Realtor.com Listing Changes
Stay updated on the latest real estate developments with Realtor.com’s powerful RSS feeds. This section guides you through utilizing Realtor.com’s RSS feeds to stay well-informed about essential property updates. Learn how to build a personalized RSS feed scraper to effortlessly monitor these changes and stay ahead in the real estate game.
Realtor.com RSS feeds for tracking property changes
Realtor.com provides a set of specialized RSS feeds, each catering to distinct property events. These feeds include:
Price Change Feed: Announces alterations in property prices.
Open House Feed: Highlights upcoming open house events.
Sold Property Feed: Notifies you when a property is successfully sold.
New Property Feed: Keeps you in the loop when new properties are listed.
These resources are handy for keeping tabs on real estate happenings. You can keep an eye on price adjustments, new property listings, and sales as they happen!
Each feed is organized by U.S. state, and it’s just a straightforward RSS XML file with announcements and dates. For example, let’s take a look at Price Change Feed for Los Angeles.
<?xml version="1.0" encoding="utf-8"?> |
We can see that it includes links to properties and the dates of price changes.
Writing a RSS feeds scraper to monitor changes
Now, let’s write a custom RSS feed scraper to actively monitor and capture changes in Realtor.com listings. Follow these key steps:
- Scrape the Feed Periodically:
- Set up your scraper to fetch the feed at regular intervals (e.g., every X seconds).
- ParseElements for Property URLs:
- Extract property URLs from the parsed RSS feed.
- Utilize Property Scraper to Collect Datasets:
- Employ your property scraper to gather detailed datasets for each property URL obtained from the feed.
- Save Data and Repeat:
Save the collected data to a database or file.
Repeat the entire process by going back to step 1.
Let’s look at a Python example of how this process can be implemented. In this Atom RSS feed Scraper, we scrape the feed every 5 minutes and append the results to a JSON-list file, with one JSON object per line.
import requests |
The scrape_feed function extracts entries from the feed, containing property URLs and their publish dates, in a “url: publish date” format. The track_feed function continuously monitors the feed, scraping new listings, and appends them as JSON entries to an output file while avoiding duplicates. The main function sets up the URL for the Realtor.com price feed for Los Angeles and initiates the tracking process, saving the results to a file named realtor-price-rss-feed-tracker.jsonl. The program runs asynchronously using the asyncio library.
6. Challenges and Roadblocks in Scraping Realtor.com
When it comes to scraping data from Realtor.com, there are a few challenges that you might encounter along the way. Realtor.com is a dynamic platform, meaning its structure can change, making it a bit tricky to consistently find and extract the information you need.

Website Changes:
Realtor.com likes to keep things fresh, and that includes how its website looks and behaves. So, you might run into situations where the way the site is set up changes. This means you need to stay on your toes and adjust your scraping approach when needed.
Anti-Scraping Measures:
To protect its data, Realtor.com has measures in place to detect and block automated scraping. This could result in your IP getting banned or facing those annoying CAPTCHA challenges. To tackle this, you’ll need to be smart about how you interact with the site to avoid detection.
Avoiding IP Blocks:
If you’re too aggressive with your scraping, Realtor.com might block your IP or limit your access. To prevent this, you can control the rate at which you make requests and switch between different proxy IP addresses. The Crawlbase Crawling API can be handy for getting around these restrictions.
Dealing with JavaScript:
Some parts of Realtor.com use JavaScript to display content. To make sure you’re grabbing everything you need, you might have to tweak your scraping methods a bit.
Tackling these challenges takes a bit of finesse, but with the right strategies, you can make your way through and get the data you’re looking for. In the next section, we’ll explore how the Crawlbase Crawling API can be a valuable tool to make your scraping efforts more efficient and scalable.
7. Scale Realtor.com Scraping with Crawlbase
Now, let’s talk about taking your Realtor.com scraping game to the next level. Scaling up your efforts can be challenging, especially when dealing with anti-scraping measures and restrictions. That’s where the Crawlbase Crawling API steps in as a powerful ally.
Crawlbase Crawling API for Anti-Scraping and Bypassing Restrictions
Realtor.com, like many websites, doesn’t always appreciate automated scraping. They might have measures in place to detect and block such activities. Here’s where Crawlbase Crawling API becomes your secret weapon.
Anti-Scraping Protection:
Crawlbase Crawling API is equipped with features that mimic human-like interactions, helping you fly under the radar. It navigates through the website more intelligently, avoiding detection and potential bans.
Bypassing IP Blocks:
If you’ve ever faced the frustration of your IP being blocked, Crawlbase comes to the rescue. It allows you to rotate through different IP addresses, preventing any pesky blocks and ensuring uninterrupted scraping.
Creating Realtor.com Scraper with Crawlbase Crawling API
Now, let’s get hands-on. How do you integrate the Crawlbase Crawling API into your Realtor.com scraper? Follow these steps:
- Sign Up for Crawlbase:
Head over to the Crawlbase website and sign up for an account. After signup, We will provide you 2 types of API Tokens (Normal Token, JS Token). You need to provide one of these token while authenticating with the Crawlbase Crawling API.
- Choosing a Token:
Crawlbase provides two types of tokens, Normal token which is tailored for static websites and JS token designed for dynamic or JavaScript-driven websites. Since our focus is on scraping realtor.com, Normal token is a good choice.
Note: The first 1000 requests are free of charge. No card required.
- Install the Crawlbase Library:
Use pip to install the Crawlbase Library. This library will be the bridge between your Python script and the Crawlbase Crawling API.
$ pip install crawlbase |
Read the Crawlbase Python Library documentation here.
- Adapt Your Script:
To use Crawlbase Crawling API into the Realtor.com scraper to make HTTP requests instead of requests library, you can create a function like below and use this function to make requests.
from crawlbase import CrawlingAPI |
By seamlessly integrating Crawlbase into our Realtor.com scraper, we can enhance our scraping capabilities, ensuring smoother navigation through anti-scraping measures and restrictions. This dynamic duo of Realtor.com scraping and Crawlbase empowers us to extract data more efficiently and at scale.
8. Final Thoughts
Real estate data scraping from Realtor.com demands a balance of simplicity and efficiency. While traditional methods have their merits, incorporating the Crawlbase Crawling API elevates your scraping experience. Bid farewell to common challenges and embrace a seamless, trustworthy, and scalable solution with the Crawlbase Crawling API for Realtor.com scraping.
For those eager to explore scraping data from diverse platforms, delve into our insightful guides:
📜 How to Scrape Zillow
📜 How to Scrape Airbnb
📜 How to Scrape Booking.com
📜 How to Scrape Expedia
Embark on your scraping journey with confidence! Should you encounter any obstacles or seek guidance, our dedicated team is ready to assist you as you navigate the ever-evolving landscape of real estate data. Happy scraping!
9. Frequently Asked Questions (FAQs)
Q. Why Should I Scrape Realtor.com for Real Estate Data?
Realtor.com stands out as one of the largest real estate websites in the United States, making it an unparalleled source for a vast public real estate dataset. This dataset encompasses crucial details such as property prices, locations, sale dates, and comprehensive property information. Scraping Realtor.com is invaluable for market analytics, understanding trends in the housing industry, and gaining a comprehensive overview of your competitors.
Q. What Tools and Libraries can I use for Realtor.com Scraping?
When diving into Realtor.com scraping, Python proves to be a robust choice. Leveraging popular libraries such as requests for making HTTP requests and BeautifulSoup4 for HTML parsing streamlines the scraping process. For scalable scraping, you can explore advanced solutions like the Crawlbase Crawling API. These services provide effective measures for overcoming challenges like anti-scraping mechanisms.
Q. How can I track changes in Realtor.com Listings in Real-Time?
Realtor.com offers convenient RSS feeds that promptly announce various property changes, including alterations in prices, open house events, properties being sold, and new listings. To keep tabs on these changes in real-time, you can develop a custom RSS feed scraper. This scraper can be programmed to run at regular intervals, ensuring that you stay updated on the latest developments in the real estate market.
Q. What Measures can I take to Avoid Blocking While Scraping Realtor.com?
Scraping at scale often comes with the risk of being blocked or encountering captchas. To mitigate this, consider leveraging advanced services like the Crawlbase Crawling API. These platforms offer features such as Anti Scraping Protection Bypass, JavaScript rendering, and access to a substantial pool of residential or mobile proxies. These measures collectively ensure a smoother scraping experience without interruptions.




