How to Scrape Samsung Products

This blog is originally posted to crawlbase.
Accessing product data from official websites is an important task in various domains, including market analysis, e-commerce, and trend forecasting. Within the technology sector, Samsung emerges as a significant player, known for its extensive range of products, notably its popular line-up of smartphones.
The process of scraping Samsung’s official website for product information, specifically targeting phone models and their associated details, serves as a means to acquire valuable insights for diverse analytical purposes, covering market research, price comparison, and trend analysis.
In this blog, we will demonstrate a straightforward method for scraping such data using JavaScript in conjunction with Crawlbase. This approach ensures anonymity and mitigates the risk of IP banning or blocking, allowing for seamless data extraction.
Table of Contents
II. Why Scrape Samsung Products
III. What can you scrape from Samsung Products Page
V. Setting Up Crawlbase Account
VI. Crawling Samsung Products Page
Step 1: Create Project Directory
Step 2: Create JavaScript File
Step 3: Install Crawlbase Package
Step 4: Write JavaScript Code
VII. Scraping Samsung Products Using Cheerio
Step 1: Install Cheerio
Step 2: Import Libraries
Step 3: Add Crawling API
Step 4: Scraping Product Title
Step 5: Scraping Product Color
Step 6: Scraping Product Variant
Step 7: Scrape Product Ratings
Step 8: Scraping Specifications
Step 9: Scraping Product URL
Step 10: Scraping Product Images
Step 11: Complete the Code
IX. Frequently Asked Questions
I. Project Scope
The scope of this project involves utilizing JavaScript along with a Crawling API to retrieve the complete HTML code of the Samsung Products Search page. After that, we will incorporate Cheerio, a lightweight and fast library, to parse and extract the specific content we require from the HTML structure.
Objective:
Utilize JavaScript to access the desired web page and take advantage of Crawling API to obtain the entire HTML code of the page anonymously and efficiently.
Integrate Cheerio, a powerful HTML parsing library for Node.js, to navigate and extract the relevant content from the retrieved HTML data.
Focus on scraping Samsung product information, specifically targeting phone models and associated details, from the HTML structure obtained through the Crawling API.
Deliverables:
Implementation of JavaScript code to interact with the Crawling API and fetch the complete HTML code of the target web page.
Integration of Cheerio library to parse and extract desired content, such as phone models and details, from the HTML data.
Outlining the step-by-step process of utilizing JavaScript, Crawling API, and Cheerio for effective data scraping of Samsung products.
Outcome:
By sticking to the outlined project scope, we aim to develop a robust and efficient solution for scraping Samsung product data from the official website. The combination of JavaScript, Crawling API, and Cheerio will enable seamless extraction of relevant information, allowing various analytical projects such as market research and trend analysis.
II. Why Scrape Samsung Products
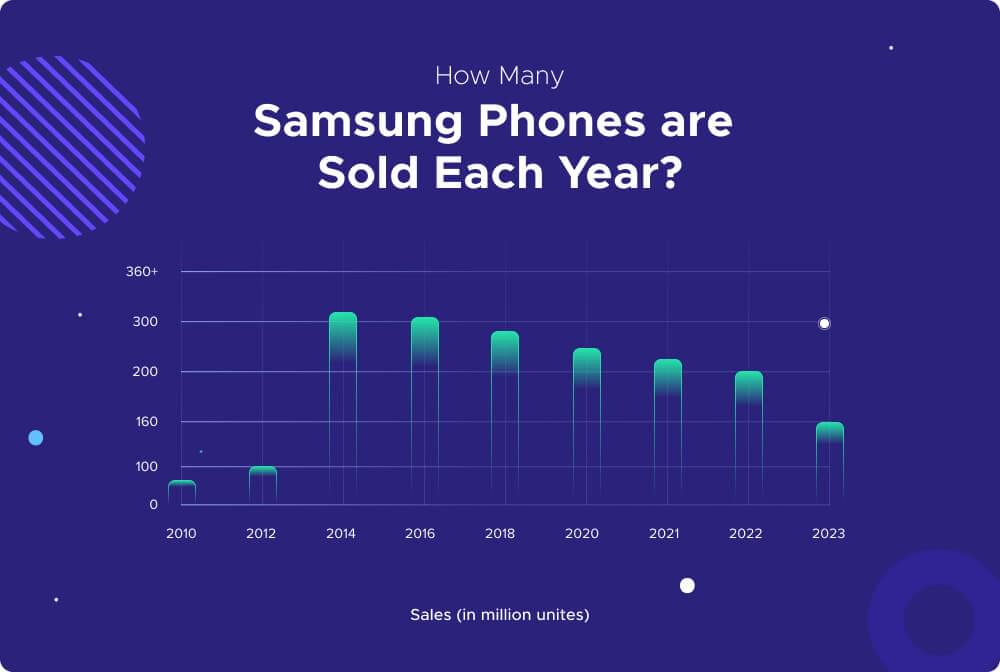
Samsung’s Global Sales and Shipments: Samsung holds a significant position in the global smartphone market, commanding a 21% share of global shipments. This translates to approximately 2 out of every 10 phones shipped worldwide being Samsung devices. In 2022 alone, an impressive 258.20 million units of Samsung smartphones were sold. Moreover, reports indicate Samsung’s ambitious goal to ship 270 million units in 2023.
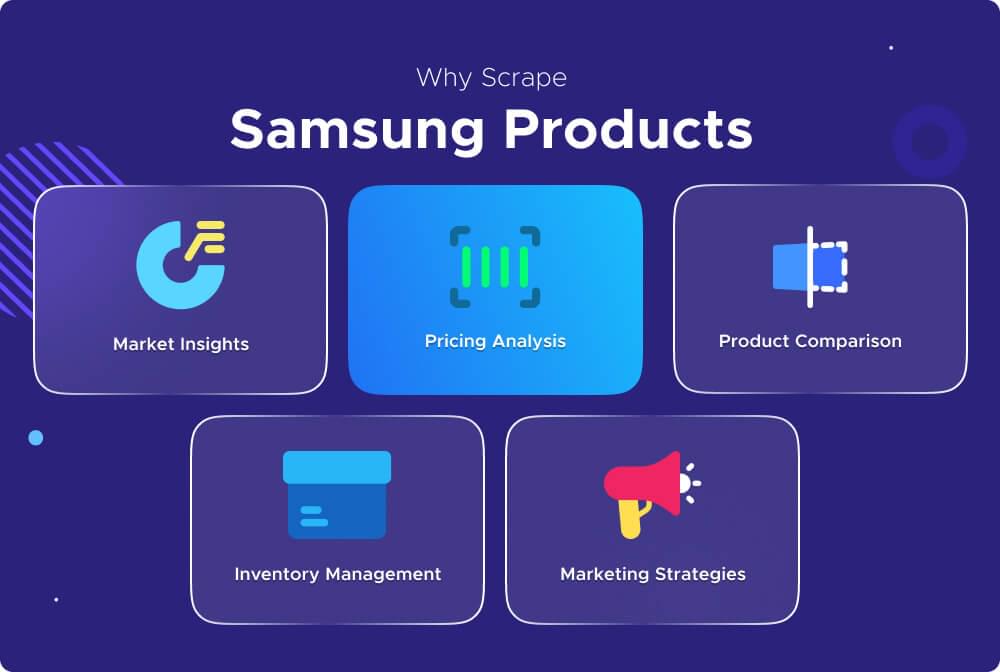
Market Insights: Scraping Samsung product data shows invaluable insights into market trends, understanding consumer preferences, and conducting detailed competitive analysis. Understanding market dynamics enables businesses to adapt their strategies effectively and stay ahead in a fiercely competitive landscape.
Pricing Analysis: Analyzing pricing trends of Samsung products across diverse platforms empowers businesses to make informed pricing decisions. By gauging the market’s response to different pricing strategies, companies can optimize their pricing structures to maximize profitability while remaining competitive.
Product Comparison: Scraping Samsung product data allows direct comparison with competitors’ offerings. This comparative analysis enables businesses to identify product strengths, weaknesses, and areas for improvement, informing product development strategies and enhancing overall competitiveness.
Inventory Management: Efficient inventory management is critical for businesses to meet consumer demand while minimizing costs. Scraping Samsung product data allows for real-time monitoring of product availability and stock levels. This enables businesses to optimize inventory management processes, prevent stockouts, and ensure stable supply chain operations.
Marketing Strategies: Utilizing scraped data from Samsung products enables businesses to tailor marketing campaigns with precision. By analyzing consumer preferences and behavior, companies can segment their target audience effectively, personalize marketing messages, and devise targeted marketing strategies. This facilitates enhanced customer engagement and improved marketing ROI.
III. What can you scrape from Samsung Products Page
Before proceeding with scraping the Samsung Products List Page, it’s important to study the HTML structure to gain insights into how the information is organized. This understanding is crucial for developing a scraper capable of extracting the specific data we require efficiently and accurately.
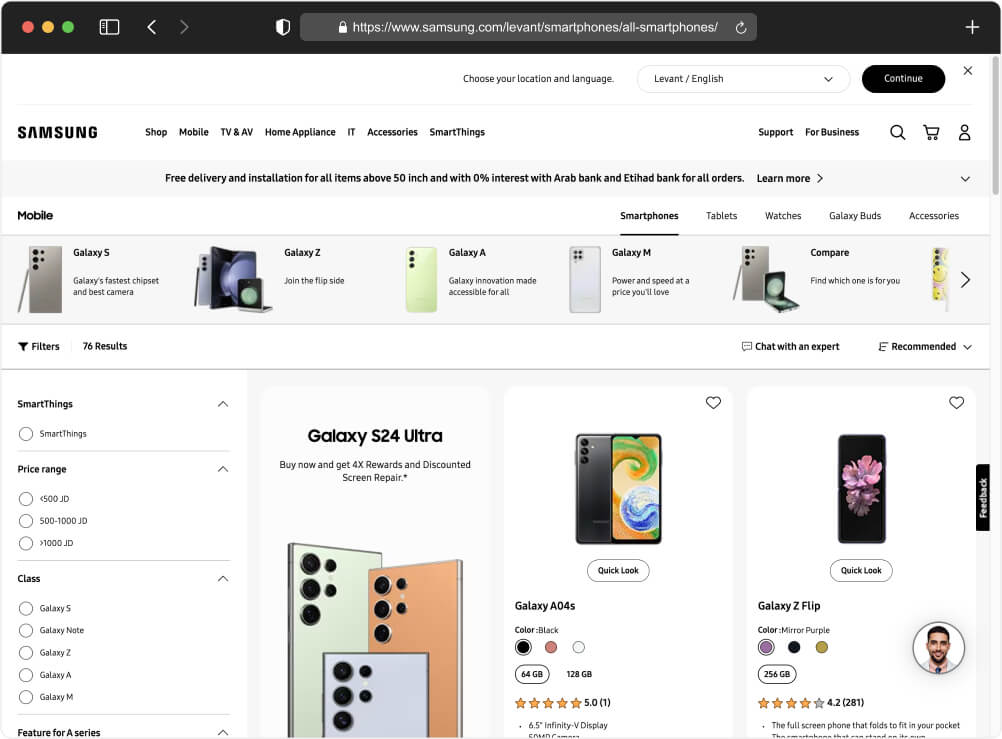
Let’s begin by exploring the Samsung Products List Page to understand its HTML structure. Our goal is to identify key elements that contain the data we need to scrape.
We have several types of data that we aim to scrape from the Samsung Products List Page:
Titles: The titles of Samsung products are likely to be found within HTML elements such as
<h1>,<h2>,<h3>, etc., which typically represent headings or titles on a webpage. Additionally, the<title>element within the<head>section of the HTML code often contains the title of the entire webpage, which might also include the product name.Specifications: Specifications of products are commonly presented within specific sections or containers on the webpage. These could be nested within
<div>,<ul>,<dl>, or other structural elements. Look for consistent patterns or classes assigned to these elements to identify where specifications are located.URLs: URLs linking to individual product pages can usually be found within
<a>(anchor) elements. These elements often have an href attribute containing the URL. They might be nested within lists, tables, or other containers, depending on the layout of the webpage.Properties: Additional properties or specifications associated with each product might be embedded within specific HTML elements. These could be represented as
<span>,<div>, or other elements with class or id attributes indicating the type of property.Product Images: Images of products are typically included within
<img>elements. These elements often have a src attribute containing the URL of the image file. Look for consistent patterns or classes assigned to these elements to identify where product images are located.Ratings: Ratings or reviews may be displayed within specific sections of the webpage, often accompanied by textual content. Look for elements such as
<span>,<div>, or<p>containing numerical ratings or descriptive reviews. These elements might also have class attributes indicating their purpose.
By inspecting the HTML code of the Samsung Products List Page and identifying the patterns and structures mentioned from the previous section, we can effectively locate the relevant data and develop a scraper to extract it programmatically.
IV. Prerequisites
Now that we have a grasp of the HTML code structure of the target page, it’s time to prepare our development environment before diving into coding. Below are the prerequisites we need to fulfill:
- Node.js Installed on Your PC:
Node.js is a runtime environment that allows you to run JavaScript code outside of a web browser.
Installing Node.js on your PC enables you to execute JavaScript-based applications and tools directly on your computer.
It provides access to a vast ecosystem of packages and libraries through npm (Node Package Manager), which you can use to enhance your development workflow.
- Basics of JavaScript:
JavaScript is a programming language commonly used for web development.
Understanding the basics of JavaScript involves learning its syntax, data types, variables, operators, control structures (like loops and conditionals), functions, and objects.
Proficiency in JavaScript enables you to manipulate web page content, interact with users, and perform various tasks within web applications.
- Crawlbase API Token:
Crawlbase is a known service that provides APIs for web crawling and scraping tasks.
An API token is a unique identifier that grants access to Crawlbase’s services.
Obtaining a Crawlbase API token allows you to authenticate and authorize your requests when using Crawlbase’s Crawling API endpoint for web scraping and crawling.
This token acts as a key to access Crawlbase’s features and services securely.
V. Setting Up Crawlbase Account
Obtaining API Credentials: Start by signing up for Crawlbase and obtaining your API credentials from account docs. These credentials are essential for making requests for their service. Crawlbase API credentials, which will enable you to interact with the Crawling API service and scrape Samsung Products Page content. These credentials are a crucial part of the web scraping process, so make sure to keep them secure.
VI. Scrape Samsung Products Page
Now that we’ve completed the setup of our coding environment, let’s dive into writing the code to crawl the Samsung Products Page. We’ll utilize the Crawling API provided by Crawlbase to fetch the HTML content of the target page efficiently.
Step 1: Create Project Directory:
Run
mkdir scrape-samsung-productsto create an empty folder namedscrape-samsung-products.Navigate into the project directory by running cd
scrape-samsung-products.
Step 2: Create JavaScript File:
- Use
touch index.jsto create a new JavaScript file namedindex.js. This file will contain our code for crawling the Samsung Products Page.
Step 3: Install Crawlbase Package:
- Execute
npm install crawlbaseto install the Crawlbase package, which provides access to the Crawling API for fetching HTML content from websites efficiently.
Step 4: Write JavaScript Code:
- Open the
index.jsfile in a text editor and add the following JavaScript code:
// Importing CrawlingAPI from the crawlbase package |
Explanation of the code:
This code sets up the Crawling API instance with your Crawlbase token and defines the URL of the Samsung Products page.
It then makes a GET request to the specified URL using the
get()method of the CrawlingAPI instance, with options to wait for AJAX requests (ajax_wait: true) and wait for the page to fully render (page_wait: 10000milliseconds).Upon receiving the response, it checks the status code. If the status code is 200 (indicating success), it logs the HTML body to the console. Otherwise, it throws an error and logs the error message.
Outcome:
Executing this code by using the command node index.js will initiate the crawling process, fetching the HTML content of the Samsung Products Page using the Crawling API. This marks the initial step in retrieving the necessary data for our scraping task.
VII. Scraping Samsung Products Using Cheerio
In this section and beyond, we’ll explore the process of extracting essential details from the Samsung Product Page. Our goal is to retrieve valuable data such as titles, color, variants, specifications, URLs, product images, and ratings.
To achieve this, we’ll build a JavaScript scraper using two key libraries: Cheerio, which is ideal for web scraping tasks, and fs, which handles file operations. The script we’ll develop will analyze the HTML structure of the Samsung Products Page, extract the required information, and store it in a JSON file for further analysis and processing.
We will build upon the previous code, so we just need to install Cheerio this time. To install Cheerio, execute the command below:
Step 1 : Install Cheerio
npm i cheerio |
Step 2: Import Libraries
Next, we import the libraries and define necessary variables.
const { CrawlingAPI } = require('crawlbase'), |
Step 3: Add Crawling API
Then, we add the Crawling API call and pass the crawled data to a function.
api |
Step 4: Scraping Samsung Product Title
In the HTML source code, locate the section or container that represents each product card. This typically involves inspecting the structure of the webpage using browser developer tools or viewing the page source.
Locate the HTML element within each product card that corresponds to the product title. To do this, right-click on the title in your browser and select ‘Inspect’ to reveal the page source and highlight the container.
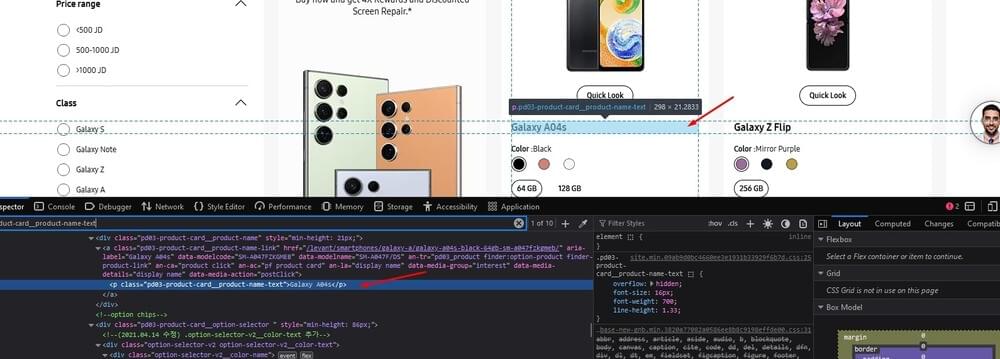
Utilize Cheerio selectors to target the title element within the product card. This involves specifying the appropriate class that matches the desired element.
Once the title element is selected, use the .text() method provided by Cheerio to extract the textual content contained within it. This retrieves the product title as a string value as you can see in the code snippet below.
title = $(element) |
Step 5: Scraping Samsung Product Color
Same as the previous element, locate the section where it shows the color of the product, right click and inspect to show the source code.
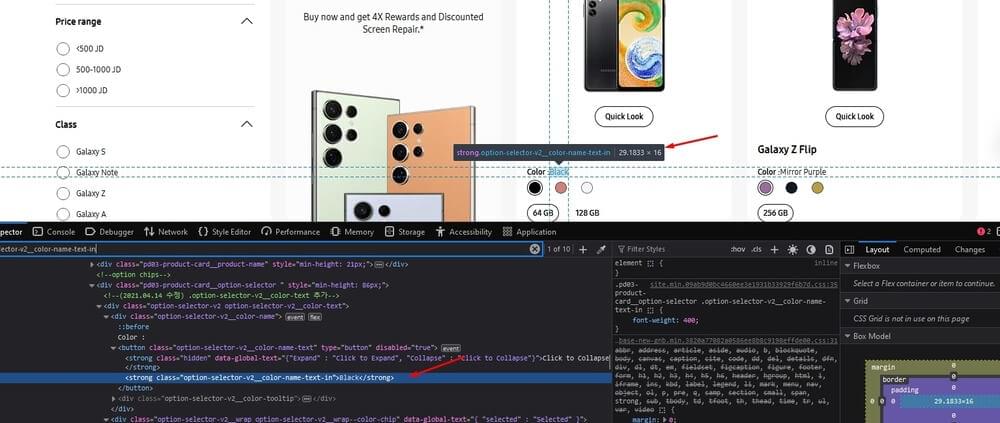
Select the HTML element(s) representing the color name within the product card, extract the text content (i.e., the color name), and assigns it to the color variable.
color = $(element) |
Step 6: Scraping Samsung Product Variant
This time, search for the product variant and locate it within the page source.
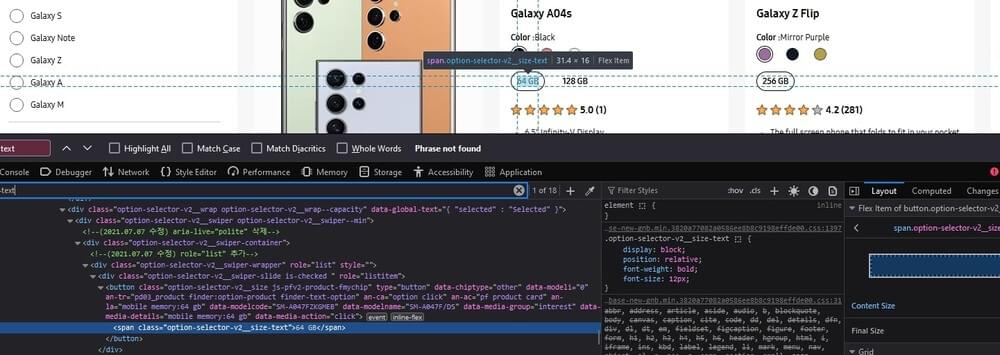
Then, copy the relevant element and utilize the find method in Cheerio, as demonstrated in the code snippet below:
variants = $(element) |
Step 7: Scrape Samsung Product Ratings
Next, look for the product rating. It typically refers to the numerical or qualitative assessments provided by customers or users regarding their satisfaction or experience with the product. These ratings are often represented using a scale, such as stars, numerical values, or descriptive labels (e.g., “excellent,” “good,” “average,” “poor”).
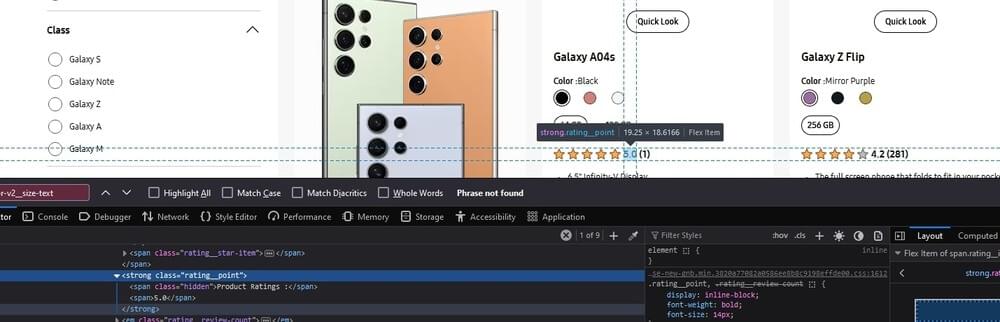
Initialize a variable named ratings and assign it the value extracted from the HTML element representing the product ratings. The .text() method extracts the text content of the element, representing the numerical value associated with the product.
ratings = $(element).find(".rating__point span:last-child")?.text(), |
Step 8: Scraping Samsung Product Specifications
Use the browser’s developer tools once again to inspect the HTML structure and identify the section containing the product specifications. Look for a class or identifier associated with this section.
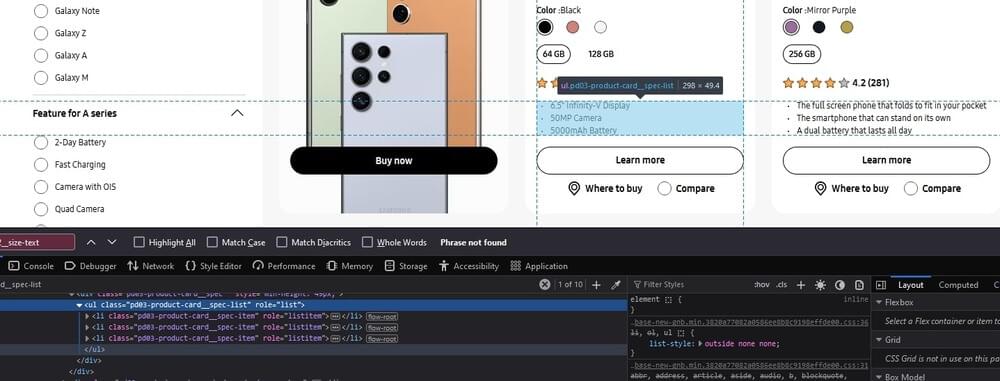
Search for HTML elements within the product card that match the specified CSS selector .pd03-product-card__spec-list .pd03-product-card__spec-item, which represents the individual specification items.
For each matched element, extract the text content using the .text() method.
Finally, the extracted specification information can be stored in an array using the .map() and .get() methods.
The code snippet below allows for the extraction of product specifications from the HTML source code of each product card element on the target website.
specifications = $(element) |
Step 9: Scraping Samsung Product URL
For the product URL, examine the HTML markup to understand how the product link is structured within the page. Determine whether it’s represented as an anchor (<a>) tag or another HTML element. Look for a class or identifier that distinguishes the link from other elements on the page.
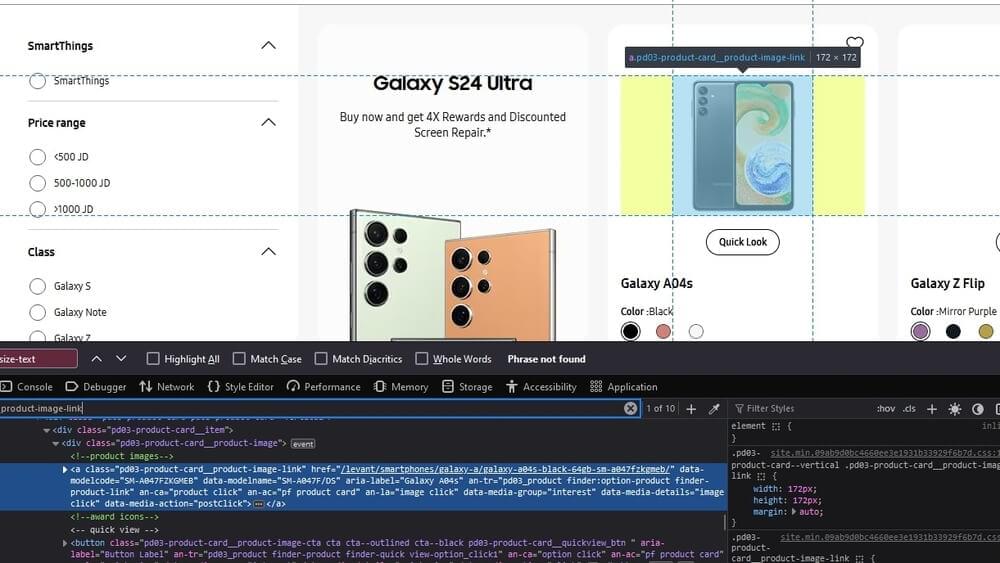
The code snippet below allows for the extraction of the URL associated with each product from the HTML source code of the product card element on the website.
url = $(element) |
Step 10: Scraping Samsung Product Images
Lastly, for the product images, look for specific classes, IDs, or attributes that distinguish the images. Examine the HTML markup to understand how the images are represented within the page. Determine whether they’re represented as <img> tags, background images, or other HTML elements.
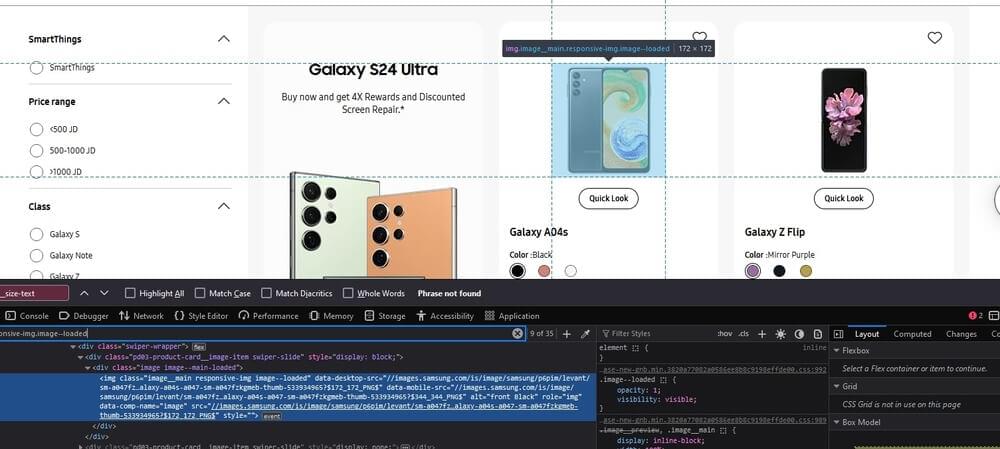
This code snippet is designed to scrape the URLs of images associated with products from a website’s HTML source code.
image = $(element).find('.image__main.responsive-img.image--loaded')?.attr('src'); |
Step 11: Complete the Code
Utilizing Cheerio, we extracted details such as the product's name, color variations, available options, ratings, features, web links, and images. Cheerio simplifies the process of navigating through the HTML markup, enabling us to effortlessly pinpoint the desired information.
Below you can see the complete code. Feel free to copy and save it to your local machine:
// Import required modules and libraries |
Executing the code by using the command node index.js should provide a similar output as shown below:
{ |
VIII. Conclusion
In this tutorial, we have provided a comprehensive guide for crawling and scraping Samsung product data from the official website. It’s important to note that the code demonstrated here is free to use, and readers are encouraged to modify or expand upon it to suit their specific requirements. The techniques showcased in this tutorial can be applied not only to scrape Samsung’s website but also to crawl and extract data from other websites.
By utilizing JavaScript along with Crawlbase’s Crawling API and Cheerio, users have the flexibility to gather valuable insights from web pages efficiently. Whether it’s analyzing market trends, conducting pricing research, or comparing products, the methods discussed here offer a versatile approach to web scraping tasks.
Feel free to adapt the code and techniques demonstrated here to scrape data from various websites and tailor it to your specific needs. With the foundational knowledge gained from this tutorial, users can begin scraping endeavors across different domains and extract actionable information for their projects.
If you are interested in similar projects, we recommend browsing the following tutorials:
How to Scrape Alibaba Search Results Data
How To Scrape Google (SERP) Search Results
How to Scrape Apple App Store Data
Do you have questions regarding Crawlbase or this article? Contact our support team. Happy scraping!
IX. Frequently Asked Questions
Q. Can I scrape large amounts of data from Samsung’s website without being blocked?
Yes, it is possible to scrape large amounts of data from Samsung’s website without encountering blocks or CAPTCHAs. This is made possible through the utilization of the Crawling API provided by Crawlbase. The Crawling API employs thousands of proxies, effectively hiding the scraper’s real IP address. Additionally, it simulates human-like interaction with the website, mimicking natural browsing behavior. These measures help to prevent blocks and CAPTCHAs, allowing for the seamless extraction of data in large quantities.
Q. Is it legal to scrape data from Samsung’s website?
The legality of web scraping from Samsung’s website depends on various factors, including the website’s terms of service, copyright laws, and applicable regulations in your area. While some websites explicitly prohibit scraping in their terms of service, others may allow it or have no clear policy.
It’s important to review Samsung’s terms of service and any relevant legal guidelines to determine whether scraping their website is permitted. Additionally, consider the purpose of the scraping, the manner in which the data will be used, and whether it may infringe on any intellectual property rights or privacy concerns.
In many cases, web scraping for personal use or research purposes may be permissible, but commercial use or redistribution of scraped data may require explicit permission from the website owner. It’s advisable to consult with legal experts or seek clarification from Samsung directly to ensure compliance with applicable laws and regulations.
Q. Can I scrape data from other websites using similar techniques?
Yes, the techniques demonstrated for scraping Samsung’s website can be applied to scrape data from other websites as well. The process typically involves:
Identifying the target website and understanding its HTML structure.
Using libraries like Cheerio or BeautifulSoup to parse the HTML and extract relevant information.
Utilizing services like the Crawling API from Crawlbase to avoid blocks and CAPTCHAs when scraping various websites.
Making HTTP requests to fetch web pages or utilizing APIs, if available, to access structured data.
Implementing strategies to handle challenges such as dynamic content, pagination, and anti-scraping measures.
Storing the scraped data in a structured format such as JSON, CSV, or a database for further analysis or use.
By using these techniques and adapting them to the specific requirements of other websites, you can scrape data from various sources depending on your goal or purpose.




