How to Scrape Trulia

This blog is originally posted to the crawlbase blog.
Trulia, a popular real estate website, offers a wealth of information that can be scraped to gather insights and trends. Trulia provides a vast amount of real estate data, including property listings, prices, and market trends. With its user-friendly interface and comprehensive data, Trulia is a go-to destination for both homebuyers and real estate professionals alike.
With 46.5M visits in Feburary 2024, Trulia is the prime target for extracting and analyzing valuable data as millions of users actively look for homes, apartments, and rentals monthly. Trulia is a real estate powerhouse with millions of property records, making it a goldmine for market analysis and research.
Scraping Trulia can be particularly useful for real estate professionals, investors, or researchers looking to analyze market dynamics, identify investment opportunities, or keep track of property prices. With web scraping, you can gather up-to-date information efficiently and gain a competitive edge.
In this step-by-step guide, we will walk you through the entire process to scrape Trulia using the Python language. So, let’s start!
Table Of Contents
Installing Dependencies
Choosing an IDE
Extracting HTML Using Common Approach
Challenges While Scraping Trulia Using Common Approach
Extracting HTML Using Crawlbase Crawling API
Handling Pagination
Saving Scraped Data into an Excel file
Integrating Pagination and Saving Operation into Script
Is It Legal to Scrape Trulia?
Why Scrape Trulia?
What Can You Scrape from Trulia?
What are the Best Ways to Scrape Trulia?
1. Understanding Project Scope
In this guide, our goal is to create a user-friendly tutorial on scraping Trulia using Python and the Crawlbase Crawling API. The project scope involves leveraging essential tools, such as Python’s BeautifulSoup library for HTML parsing and the Crawlbase Crawling API for an efficient data extraction process.
We’ll focus on scraping various elements from Trulia listings, including property names, addresses, ratings, reviews, and images. The aim is to provide a step-by-step approach, making it accessible for users with varying levels of technical expertise.
Key Components of the Project:
- HTML Crawling: We’ll employ Python along with the Crawlbase Crawling API to retrieve the complete HTML content of Trulia listings. This ensures effective data extraction while adhering to Trulia’s usage policies. The target URL for this project will be provided for a hands-on experience.
We will scrape the Trulia property listing for the location “Los Angeles, CA” from this URL.
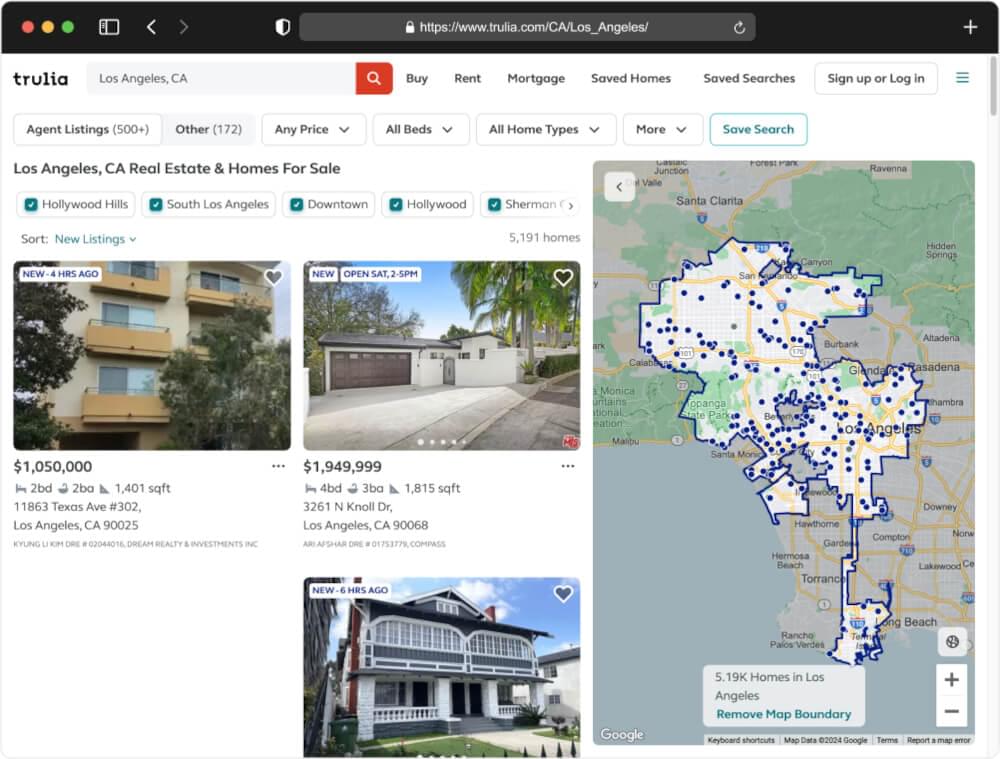
Data Extraction from Trulia: Our primary focus will be on using BeautifulSoup in Python to extract specific data elements from Trulia listings. This includes scraping property names, addresses, ratings, reviews, and images.
Handling Pagination: To cover multiple pages of Trulia listings, we’ll discuss techniques for handling pagination, ensuring that all relevant data is captured.
Saving Data: We’ll explore ways to store or save the scraped data, providing options such as saving to a CSV file for further analysis.
By outlining the project scope, we aim to guide you through a comprehensive Trulia scraping tutorial, making the process understandable and achievable. Now, let’s proceed to the prerequisites of the project.
2. Prerequisites
Before immersing ourselves in the world of web scraping Trulia with Python, let’s lay down the essential prerequisites to ensure a smooth journey:
- Basic Knowledge of Python:
Having a foundational understanding of the Python programming language is crucial. If Python is new to you, consider exploring introductory tutorials or courses to grasp the basics.
- Crawlbase Account with API Credentials:
Obtain an active account on Crawlbase along with API credentials to access Trulia pages programmatically. Sign up for the Crawlbase Crawling API to receive your initial 1,000 requests and secure your API credentials from the account documentation.
- Choosing a Token:
Crawlbase provides two types of tokens – one tailored for static websites and another designed for dynamic or JavaScript-driven websites. Trulia use JS rendering to load data on the website. So, We use JS token.
- Python Installed on Your Machine:
You can download Python from the official Python website based on your operating system. Additionally, confirm the presence of pip (Python package manager), which usually comes bundled with Python installations.
# Use this command to verify python installation |
3. Project Setup
Before we dive into scraping trulia.com, let’s set up our project to make sure we have everything we need.
Installing Dependencies
Now, let’s get our tools in place by installing the necessary libraries. These libraries are like the superheroes that will help us scrape Trulia effortlessly. Follow these simple steps:
- Open Your Terminal or Command Prompt:
Depending on your operating system, open the terminal or command prompt.
- Install
requests:
The requests library helps us make HTTP requests easily. Enter the following command and press Enter:
pip install requests |
- Install
beautifulsoup4:
BeautifulSoup aids in HTML parsing, allowing us to navigate and extract data seamlessly. Use the following command to install it:
pip install beautifulsoup4 |
- Install
pandas:
Pandas is our data manipulation powerhouse, enabling efficient handling of scraped data. Run the command below to install it:
pip install pandas |
- Install crawlbase:
The Crawlbase library integrates with the Crawlbase Crawling API, streamlining our web scraping process. Install the Crawlbase library using this command:
pip install crawlbase |
Choosing an IDE
Now that Python and the essential libraries are ready, let’s pick an Integrated Development Environment (IDE) to make our coding experience simple and enjoyable. Several IDEs are available, and here are a few user-friendly options for Python:
Visual Studio Code: It’s light and easy, perfect for those new to coding.
PyCharm: A feature-packed choice widely embraced in professional settings.
Jupyter Notebooks: Ideal for interactive and exploratory coding adventures.
In the upcoming section, we’ll kick off by extracting data from a single property on trulia.com. Let the scraping journey begin!
4. Extracting Trulia SERP HTML
When it comes to scraping Trulia, our first step is to retrieve the raw HTML content of the Search Engine Results Page (SERP). This lays the foundation for extracting valuable information. Let’s explore two methods: the common approach and the smart approach using the Crawlbase Crawling API.
Extracting HTML Using Common Approach
When it comes to extracting HTML, the common approach involves using Python libraries like requests and BeautifulSoup. These libraries allow us to send requests to Trulia’s website and then parse the received HTML for data.
import requests |
Run the Script:
Open your terminal or command prompt and navigate to the directory where you saved trulia_scraper.py. Execute the script using the following command:
python trulia_scraper.py |
As you hit Enter, your script will come to life, sending a request to the Trulia website, retrieving the HTML content and displaying it on your terminal.
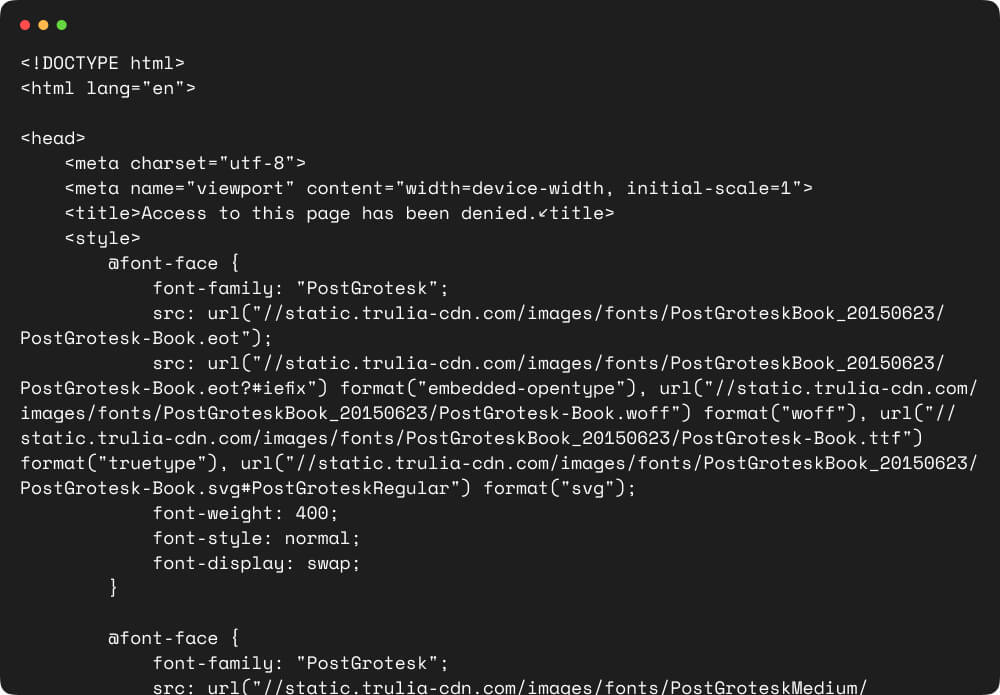
Challenges While Scraping Trulia Using Common Approach
As we navigate the path of scraping Trulia, we encounter certain challenges when relying on common or traditional approaches. Let’s shine a light on these hurdles:
- Anti-Scraping Measures
Trulia implements safeguards to protect its website from automated scraping. These measures often include CAPTCHAs and rate limiting, making it tricky for traditional scraping methods to smoothly collect data.
Related Read: How to bypass CAPTCHAS
- Dynamic Content
Trulia’s website extensively utilizes JavaScript to load dynamic content. Traditional scraping may struggle to capture this dynamic data effectively, resulting in incomplete or inaccurate information retrieval.
These challenges highlight the need for a more sophisticated approach, which we’ll address using the enhanced capabilities of the Crawlbase Crawling API in the subsequent sections.
Extracting HTML Using Crawlbase Crawling API
The Crawlbase Crawling API provides a more robust solution, overcoming common scraping challenges. It allows for efficient HTML extraction, handling dynamic content, and ensuring adherence to Trulia’s usage policies. Its parameters allow us to handle various scraping tasks effortlessly.
We’ll incorporate the ajax_wait and page_wait parameters to ensure that we get HTML after the page is loaded completely. Here’s an example Python function using the Crawlbase library:
from crawlbase import CrawlingAPI |
5. Scrape Trulia SERP Listing
Before we delve into specific elements, let’s create a function to get all property listings from the SERP. This will serve as the foundation for extracting individual details.
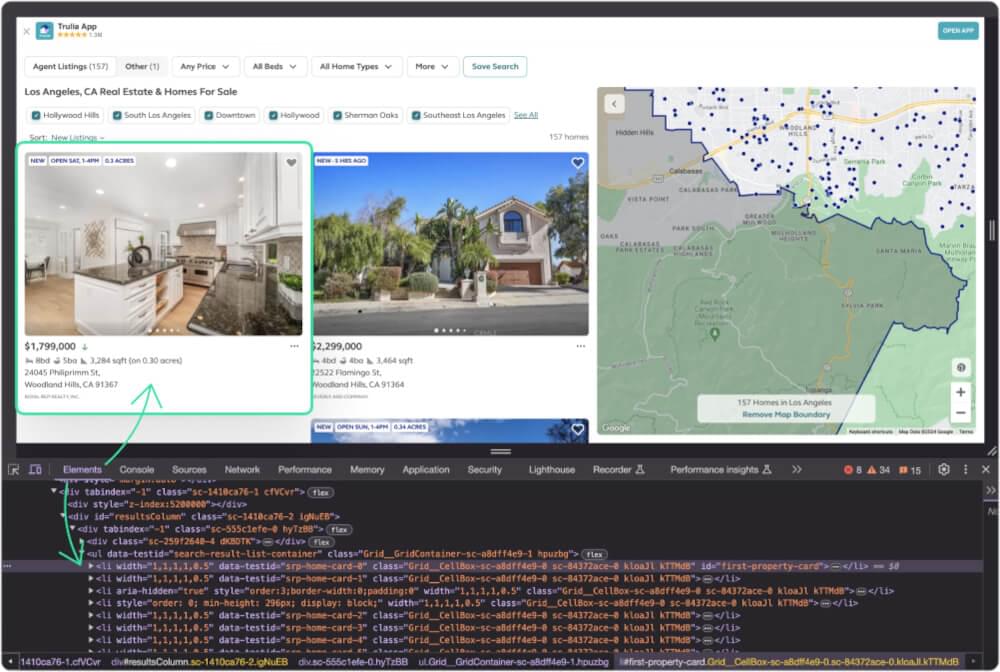
Every listing is inside li element and all li elements are inside ul element with data-testid as search-result-list-container.
# Import necessary libraries |
6. Scrape Trulia Price
Let’s create a function to scrape the property prices from the search results.
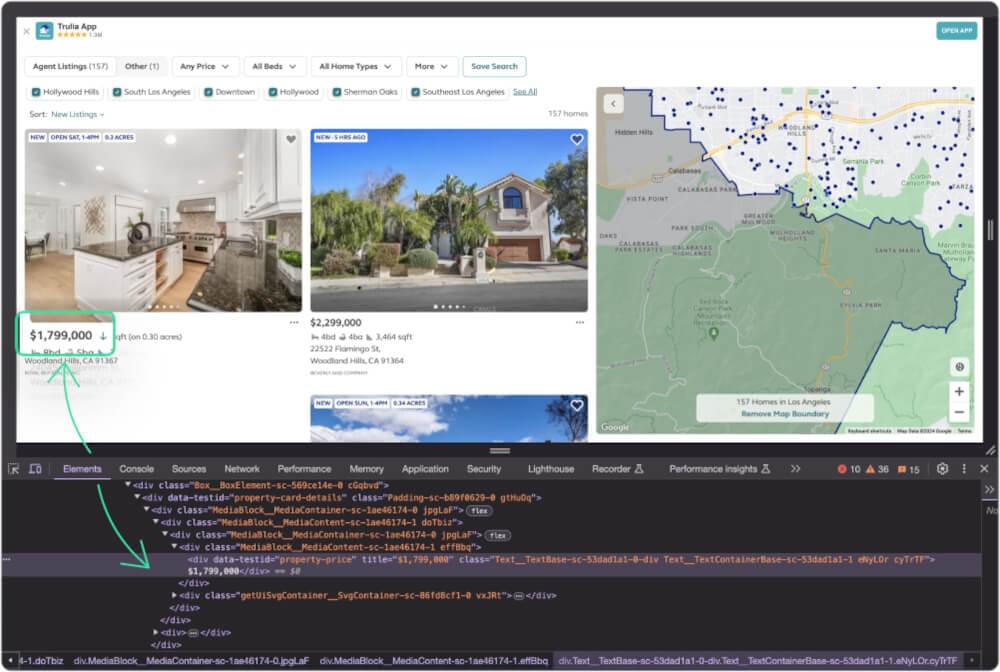
When you inspect a price, you’ll see it’s enclosed in div having the class data-testid as property-price.
# Function to scrape Trulia price |
7. Scrape Trulia Address
Now, let’s grab the property addresses.
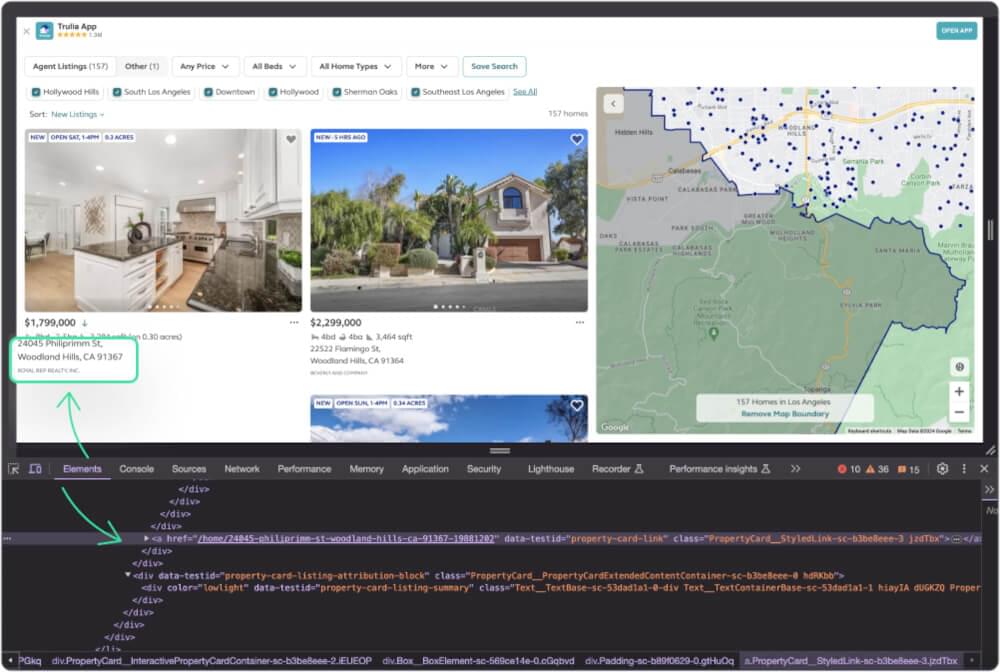
Address is enclosed in div having the class data-testid as property-address.
# Function to scrape Trulia address |
8. Scrape Trulia Property Size
Extracting the property size is up next.
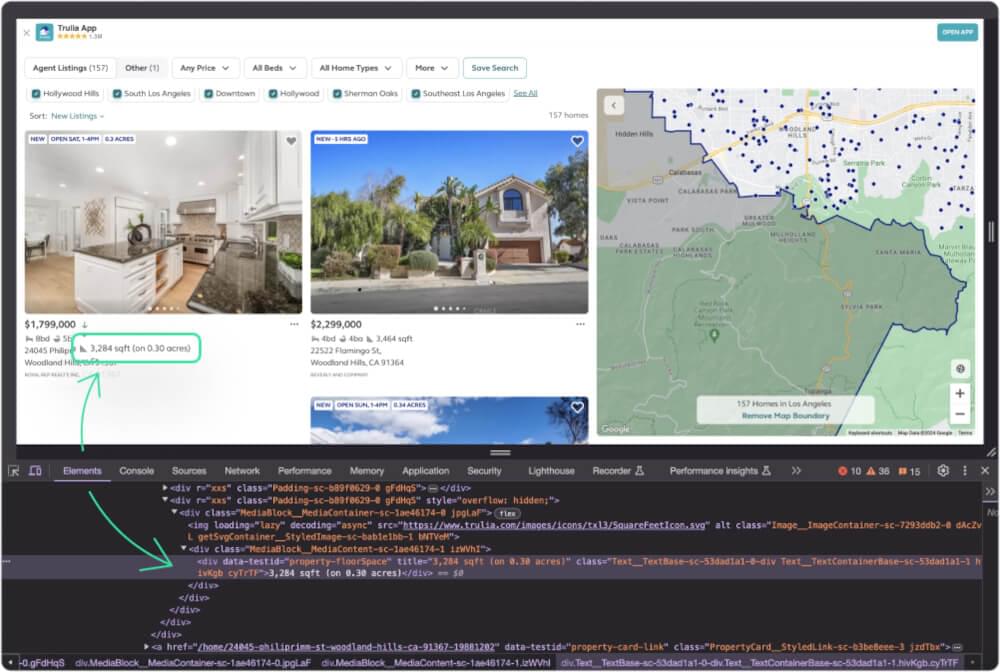
Property size is enclosed in div having the class data-testid as property-floorSpace.
# Function to scrape Trulia property size |
9. Scrape Trulia Property Bedrooms Count
Now, let’s create a function get the count of bedrooms for the property.
Bedrooms count is enclosed in div having the class data-testid as property-beds.
# Function to scrape Trulia property bedrooms count |
10. Scrape Trulia Property Baths Count
Now, let’s create a function get the count of baths for the property.
Baths count is enclosed in div having the class data-testid as property-baths.
# Function to scrape Trulia property baths count |
11. Scrape Trulia Property Agent
Now, let’s get the information about property agent.
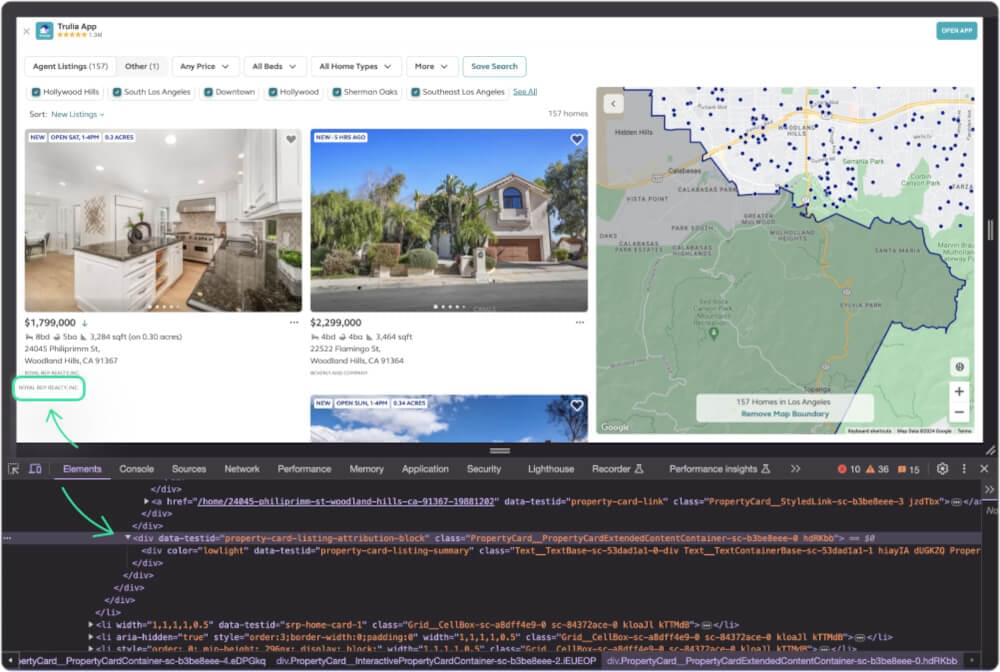
Property agent information can be found in a div having the attribute data-testid with value property-card-listing-summary.
# Function to scrape Trulia property agent |
12. Scrape Trulia Images
Capturing property images is crucial. Here’s a function to get those.
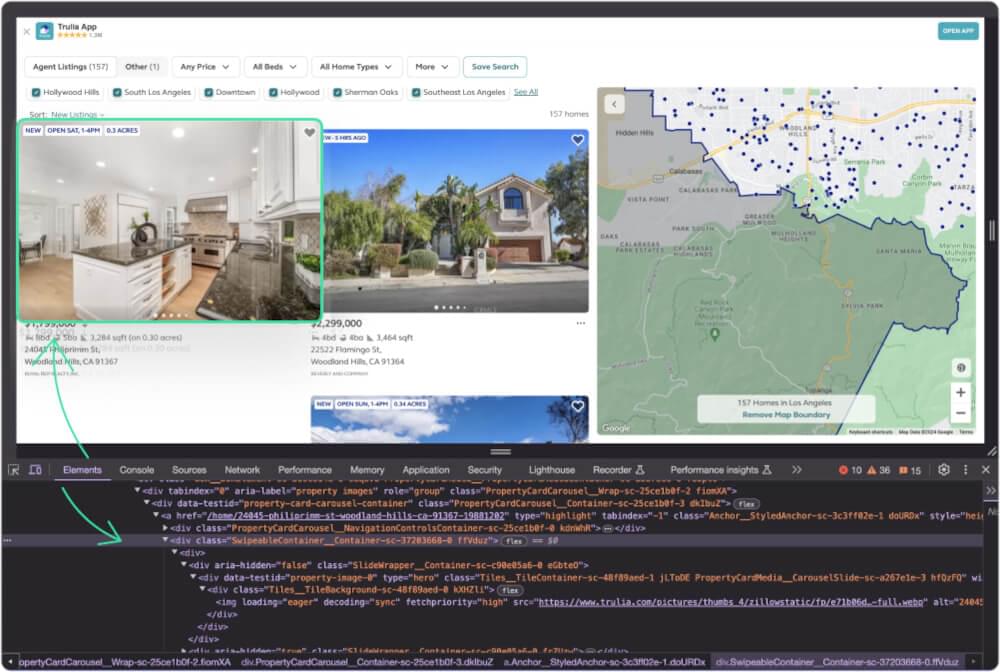
All the images are present inside a div with the class staring with SwipeableContainer__Container. Once we get the element, we can scrape all the img element src attribute to get image links.
13. Scrape Trulia Property Page Link
Now, let’s get the property detail page link.
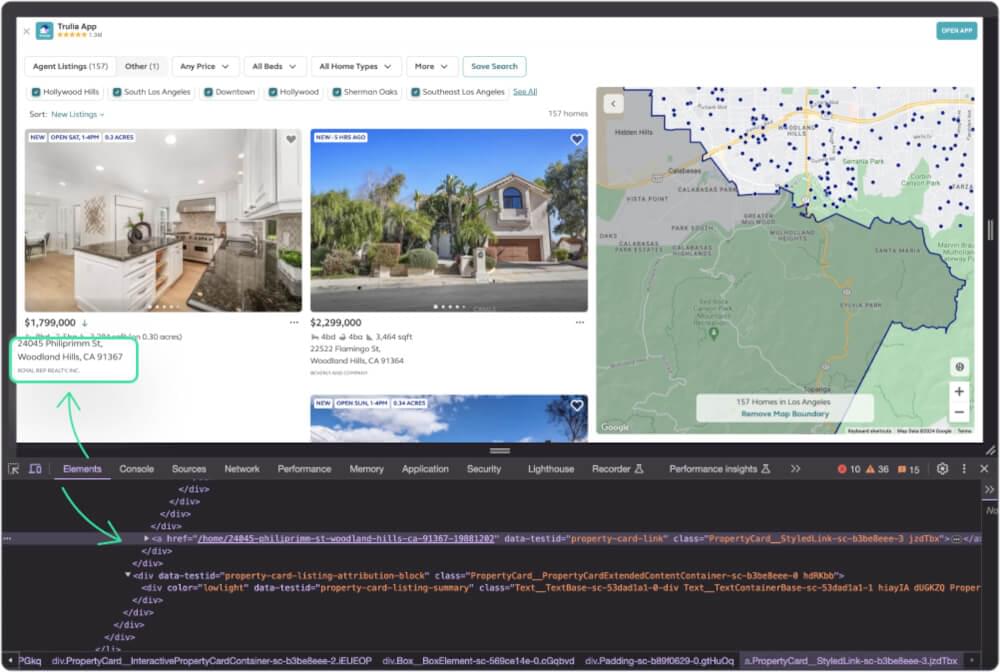
Property page link can be found in an a element having the attribute data-testid with value property-card-link.
# Function to scrape Trulia property page link |
14. Complete Code
Now, let’s combine these functions to create a comprehensive script for scraping Trulia search results.
# Import necessary libraries |
Example Output:
[ |
15. Handling Pagination and Saving Data
Our journey with Trulia scraping continues as we address two crucial aspects: handling pagination to access multiple search result pages and saving the scraped data into a convenient Excel file.
Handling Pagination
Trulia often employs pagination to display a large number of search results. We need to navigate through these pages systematically.
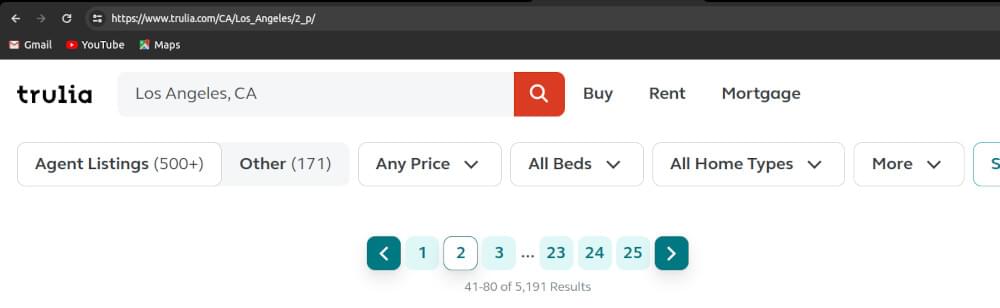
Trulia uses a specific path-based method, assigning each page a sequential number. For example, the first page has the path /1_p/, the second page uses /2_p/, and so on.
Here’s a function to handle pagination and fetch HTML content for a given page:
# Function to fetch HTML content with Trulia's pagination |
Saving Scraped Data into an Excel File
Once we have scraped multiple pages, it’s crucial to save our hard-earned data. Here’s how we can do it using the pandas library:
import pandas as pd |
Integrating Pagination and Saving Operation into Script
Now, let’s integrate these functions into our existing script from previous section. Add above functions in the script and replace the existing main function with this updated one:
def main(): |
trulia_scraped_data.xlsx Snapshot:
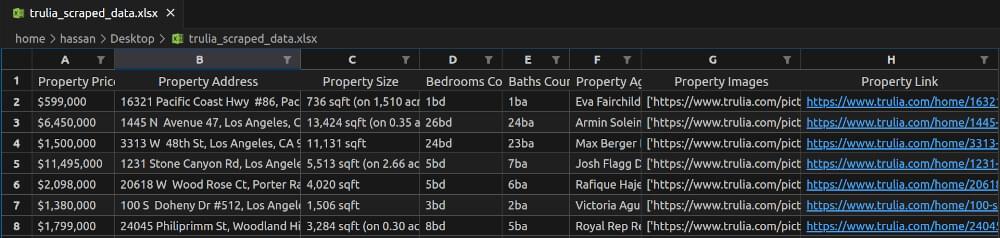
This integrated script now handles pagination seamlessly and saves the scraped Trulia data into an Excel file. Happy scraping and data handling!
16. Final Thoughts
Scraping Trulia for real estate data requires a strategic blend of simplicity and effectiveness. While traditional approaches have their merits, integrating the Crawlbase Crawling API elevates your scraping endeavors. Say goodbye to common challenges and welcome a seamless, reliable, and scalable solution with the Crawlbase Crawling API for Trulia scraping.
For those eager to broaden their horizons and explore data scraping from various platforms, our insightful guides await your exploration:
📜 How to Scrape Zillow
📜 How to Scrape Airbnb
📜 How to Scrape Booking.com
📜 How to Scrape Expedia
Should you encounter obstacles or seek guidance, our dedicated team stands ready to assist you as you navigate the dynamic realm of real estate data.
17. Frequently Asked Questions (FAQs)
Q. Is It Legal to Scrape Trulia?
While web scraping legality can vary, it’s important to review Trulia’s terms of service to ensure compliance. Trulia may have specific guidelines regarding data extraction from their platform. It’s advisable to respect website terms and policies, obtain necessary permissions, and use web scraping responsibly.
Q. Why Scrape Trulia?
Scraping Trulia provides valuable real estate data that can be utilized for various purposes, such as market analysis, property trends, and competitive insights. Extracting data from Trulia allows users to gather comprehensive information about property listings, prices, and amenities, aiding in informed decision-making for buyers, sellers, and real estate professionals.

Q. What Can You Scrape from Trulia?
Trulia offers a rich source of real estate information, making it possible to scrape property details, listing descriptions, addresses, pricing data, and more. Additionally, user reviews, ratings, and images associated with properties can be extracted. The versatility of Trulia scraping allows users to tailor their data extraction based on specific needs.

Q. What are the Best Ways to Scrape Trulia?
The best approach to scrape Trulia involves leveraging the dedicated API with IP rotation like Crawlbase Crawling API for efficient and reliable data extraction. By using a reputable scraping service, you ensure smoother handling of dynamic content, effective pagination, and adherence to ethical scraping practices. Incorporating Python libraries alongside Crawlbase services enhances the scraping process.




