How to Scrape Yellow Pages Data

This blog is originally posted to the Crawlbase blog.
Yellow Pages is a directory service that lists businesses in various industries. It originated as a printed directory, with businesses listed alphabetically along with their contact information. Over time, Yellow Pages transitioned into an online platform, making it easier for users to search for specific businesses based on their location, industry, or keyword.
Yellow Pages are an essential source of information for businesses looking to find potential customers, suppliers, or partners in their industry. With millions of businesses listed on the Yellow Pages, it has become a treasure trove of data for marketers, researchers, and businesses looking for a competitive advantage.
Yellow Pages witnesses a substantial volume of online traffic on a daily basis. Its user-friendly interface and comprehensive coverage have contributed to a significant number of visitors seeking local services, products, and contact information.
Whether you are an entrepreneur looking to explore new markets, a marketer aiming to refine your target audience, or a data enthusiast seeking to unravel trends, scraping Yellow Pages data is your gateway to actionable insights. In this guide, we will walk you through the process of efficiently extracting valuable data from Yellow Pages using Python with common approach and later with powerful Crawlbase Crawling API.
Let’s get started!
Table Of Contents
Navigating Yellow Pages SERP Structure
Key Data Points on Yellow Pages
Relevance and Applications of Yellow Pages Data
Installing Python and Essential Libraries
Choosing an IDE for Efficient Coding
Leveraging Python’s Requests Library
Inspecting Yellow Pages Website for HTML Elements
Parsing HTML with BeautifulSoup
Challenges and Limitations of the Common Approach
Advantages of Opting for Crawlbase’s Crawling API
Crawlbase Registration and API Token
Interfacing with the Crawling API Using Crawlbase Library
Extracting Business Information from Yellow Pages
Managing Pagination for Extensive Data Retrieval
Understanding Yellow Pages for Data Scraping
Yellow Pages acts as a valuable business development tool, enabling companies to identify potential partners, suppliers, or distributors within their industry. To effectively scrape Yellow Pages, it’s crucial to grasp its structure and the valuable data it holds. Here’s a breakdown to guide you through:
Navigating Yellow Pages SERP Structure
Understanding the structure of Yellow Pages’ Search Engine Results Page (SERP) is crucial for efficient data scraping. Let’s embark on a journey through the layout of Yellow Pages SERP, unlocking the potential to extract valuable business information.

Search Query Input: At the heart of Yellow Pages’ SERP is the search query input, where users input keywords related to the business or service they are looking for. Yellow Pages organizes search results based on these queries, making it imperative to choose accurate and relevant keywords for effective data extraction.
Business Listings: Yellow Pages presents search results in the form of business listings. Each listing encapsulates essential details such as the business name, contact information, address, and service categories. The structured display allows users to quickly scan and identify businesses relevant to their search.
Pagination: Yellow Pages organizes search results across multiple pages, implementing a pagination system. Users can navigate through different pages to access a broader scope of business listings. For data scrapers, handling pagination becomes a crucial step to ensure comprehensive data retrieval.
Additional Filters: To enhance user experience, Yellow Pages offers additional filters. Users can refine their search by applying filters like location, business category, and customer ratings. As a scraper, understanding and navigating through these filters becomes essential for targeted data extraction.
Map Integration: Yellow Pages integrates a map feature into its SERP, providing users with a visual representation of business locations. For data scrapers, extracting geospatial data from these maps can add an extra layer of valuable information for various analytical purposes.
Understanding these components of Yellow Pages SERP lays the groundwork for effective data scraping.
Key Data Points on Yellow Pages
To leverage the wealth of business insights on Yellow Pages, pinpointing crucial data is vital. Let’s explore the essential information provided by Yellow Pages and understand how each data point contributes to comprehensive business understanding.

Business Name: Identifying businesses relies on accurate extraction of business names. This serves as the primary identifier, ensuring a well-structured dataset.
Contact Information: Extracting contact details like phone numbers and email addresses is crucial for facilitating customer communication or outreach.
Address: Extracting addresses enables geospatial analysis, helping understand business distribution and popular zones.
Business Categories: Capturing the business category or industry type is valuable for creating segmented datasets and industry-specific analyses.
Ratings and Reviews: Scraping user-generated ratings and reviews provides insights into the reputation and quality of a business, reflecting customer sentiments.
Website URL: Extracting website URLs enables further exploration of businesses and understanding their online offerings.
Additional Services: Highlighting additional services offered by businesses adds depth to profiles, helping users understand the full range of services.
Business Hours: Extracting business hours facilitates time-sensitive analyses, helping users plan visits or contact establishments during specific time frames.
Understanding and extracting these key data points from Yellow Pages not only builds a rich and detailed database but also lays the foundation for various analytical applications.
Relevance and Applications of Yellow Pages Data
Data from Yellow Pages isn’t just information; it’s a powerful resource offering valuable business insights and applications. Here’s how Yellow Pages data is relevant and can be applied:

Market Analysis: Gain insights into market dynamics and identify industry trends.
Competitor Research: Analyze competitor offerings and market presence for strategic planning.
Targeted Marketing Campaigns: Tailor marketing campaigns based on specific industries, regions, or business types.
Business Expansion Strategies: Identify potential locations for business expansion by analyzing high-activity areas.
Consumer Behavior Analysis: Understand customer preferences and behaviors through ratings, reviews, and services.
Partner and Supplier Selection: Streamline partner and supplier selection by accessing contact information and services.
Local Business Support: Support local businesses by understanding their offerings and customer feedback.
Data-Driven Decision-Making: Empower data-driven decision-making across sectors for strategic planning.
In the upcoming sections, we will explore the techniques to scrape Yellow Pages effectively, ensuring the retrieval of these valuable business insights.
Setting Up Your Python Environment
To prepare for scraping Yellow Pages data, ensure a smooth coding experience by setting up your Python environment. This involves installing Python, required libraries, and selecting an IDE for streamlined coding.
Installing Python and Essential Libraries
Download and Install Python:
Begin by visiting the official Python website and navigating to the “Downloads” section. Choose the latest version compatible with your operating system and follow the installation instructions. Ensure that the option to add Python to your system’s PATH is selected during installation.
Installing Required Libraries:
For Yellow Pages scraping, we’ll be using essential libraries like requests and BeautifulSoup in Python. To utilize the Crawling API, we will make use of the crawlbase library. Open your command prompt or terminal and use the following commands to install these libraries:
pip install requests |
These libraries will enable your Python scripts to send HTTP requests and parse HTML content efficiently.
Choosing an IDE for Efficient Coding
Selecting the right Integrated Development Environment (IDE) can significantly enhance your coding experience. Here are a couple of popular choices:
PyCharm: PyCharm is a robust IDE developed specifically for Python. It provides features like intelligent code completion, debugging tools, and a user-friendly interface. You can download the community edition for free from the JetBrains website.
VSCode (Visual Studio Code): VSCode is a lightweight yet powerful code editor with excellent Python support. It offers a wide range of extensions, making it customizable for different programming languages. You can download it from the official Visual Studio Code website.
Jupyter Notebook: For a more interactive coding experience, especially for data analysis tasks, Jupyter Notebooks are a popular choice. You can install Jupyter using the command pip install jupyter and launch it with the jupyter notebook command.
Choose the IDE that aligns with your preferences and workflow. With Python installed and the necessary libraries ready, you’re well-equipped to embark on your journey to scrape valuable data from Yellow Pages using Python.
Common Approach for Yellow Pages Data Scraping
In this section, we’ll explore a common approach to scraping data from Yellow Pages using Python. We’ll leverage essential libraries such as the Requests library for making HTTP requests and BeautifulSoup for parsing HTML content.
In our example, let’s focus on scraping data related to “Information Technology” businesses located in “Los Angeles, CA”.
Leveraging Python’s Requests Library
To initiate the scraping process, we’ll use the Requests library to send HTTP requests to Yellow Pages servers. This library allows us to retrieve the HTML content of web pages, forming the basis of our data extraction.
Yellow Pages utilizes the search_terms parameter in the URL for the search query and the geo_location_terms parameter for the location.
import requests |
Open your preferred text editor or IDE, copy the provided code, and save it in a Python file. For example, name it yellowpages_scraper.py.
Run the Script:
Open your terminal or command prompt and navigate to the directory where you saved yellowpages_scraper.py. Execute the script using the following command:
python yellowpages_scraper.py |
As you hit Enter, your script will come to life, sending a request to the Yellow Pages website, retrieving the HTML content and displaying it on your terminal.
Inspecting Yellow Pages Website for HTML Elements:
Once we have the HTML content, we need to inspect the structure of the Yellow Pages website to identify relevant HTML elements. This involves understanding the page’s Document Object Model (DOM) and pinpointing elements that contain the desired data.
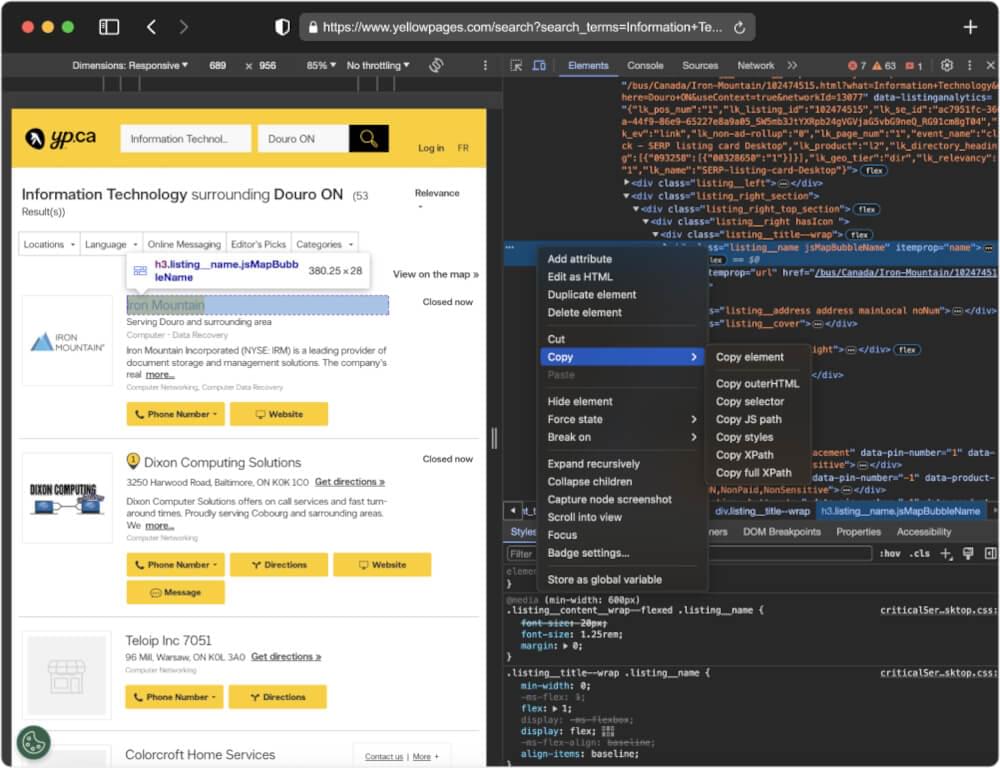
Follow these points to effectively inspect the Yellow Pages website:
Right-Click and Inspect: Open Developer Tools by right-clicking on the webpage.
Navigate the DOM Tree: Explore the Document Object Model (DOM) to locate HTML tags.
Identify Unique Attributes: Look for unique attributes like class names or IDs.
Use Selectors: Utilize CSS selectors for precise element identification.
Consider Pagination: Inspect pagination elements for multiple pages.
Account for Dynamic Content: Be aware of dynamically loaded content through JavaScript.
Document Findings: Record identified elements and patterns for efficient scraping.
Parsing HTML with BeautifulSoup
After identifying the relevant HTML elements, we’ll use the BeautifulSoup library to parse the HTML and extract the desired data. BeautifulSoup provides a convenient way to navigate and search the HTML tree.
For the example, we will extract essential details such as the Business Name, Contact Information, Address, Business Categories, Ratings and Reviews Count, Years in Business, and Website URL from every result on the YellowPages SERP. Now, let’s enhance our existing script to gather this information directly from the HTML.
import requests |
The script incorporates functions for constructing the search URL, fetching HTML content, and extracting details from the HTML. If an element is not found during extraction, the corresponding value in the result dictionary is set to None. The main function orchestrates the entire process and prints the extracted details for the specified search query and location.None
Example Output:
[ |
Challenges and Limitations of the Common Approach
While the common approach to scraping Yellow Pages data using Python’s requests and BeautifulSoup is accessible, it comes with several challenges and limitations that can impact the efficiency and success of your scraping efforts.
Anti-Scraping Measures
Yellow Pages deploys anti-scraping measures, including CAPTCHAs, which can hinder automated scraping scripts and require manual intervention.
Rate Limiting
Websites implement rate limiting to control request frequency. Exceeding limits can result in temporary or permanent IP blockages, restricting access.
Dynamic Website Structure
Websites, including Yellow Pages, may change structure over time, requiring frequent script updates to accommodate modifications.
IP Blocking
Aggressive scraping may trigger IP blocking, hindering further access. Automated solutions are often necessary for overcoming IP blocks.
Data Extraction Challenges
Basic HTML parsing for data extraction may pose challenges, especially with evolving website structures, leading to less reliable scraping logic.
For a smoother and more reliable Yellow Pages scraping experience, consider using the Crawlbase Crawling API, designed to overcome common scraping hurdles and enhance the overall process.
Using Crawling API for Yellow Pages
Unlock the full potential of your Yellow Pages data scraping by leveraging the power of Crawlbase’s Crawling API. This user-friendly approach seamlessly integrates into your Python project, offering enhanced efficiency and reliability.
Say goodbye to the challenges of IP blocks, captchas, and compliance issues. Crawlbase’s dynamic content handling, asynchronous crawling, and customizable requests ensure a dependable solution for tailored and high-speed data retrieval from Yellow Pages.
Benefit from comprehensive documentation and responsive support, streamlining your scraping experience for maximum efficiency. Elevate your Yellow Pages scraping endeavors with Crawlbase’s Crawling API – the trusted solution for precise and scalable web scraping.
Follow these simple steps to effortlessly integrate the API into your Python scraping project and experience a new level of scraping convenience and performance.
Crawlbase Registration and API Token
To kickstart your journey with Crawlbase and harness the power of its Crawling API for Yellow Pages scraping, follow these straightforward steps:
Visit Crawlbase Platform: Head to the Crawlbase platform by visiting their website.
Create an Account: Signup for a Crawlbase account. This process typically involves providing a valid email address and creating a secure password.
Explore Plans (if applicable): Depending on your requirements, explore the available plans on Crawlbase. Choose a plan that aligns with the scale and scope of your Yellow Pages scraping project. The first 1000 requests are free of charge. No card required.
Retrieve Your API Token: You can find yours in your account documentation. This alphanumeric string is crucial for authenticating your requests to the Crawling API.
Quick Note: Crawlbase provides two types of tokens – one tailored for static websites and another designed for dynamic or JavaScript-driven websites. Since our focus is on scraping Yellow Pages, we will use Normal token.
Interfacing with the Crawling API Using Crawlbase Library
The Python-based Crawlbase library seamlessly enables interaction with the API, effortlessly integrating it into your YellowPages scraping endeavor. The following code snippet illustrates the process of initializing and utilizing the Crawling API via the Crawlbase Python library.
from crawlbase import CrawlingAPI |
For in-depth information about the Crawling API, refer to the comprehensive documentation available on the Crawlbase platform. Access it here. To delve further into the capabilities of the Crawlbase Python library and explore additional usage examples, check out the documentation here.
Extracting Business Information from Yellow Pages
Integrate the Crawlbase library into your Python project and initialize it with your unique API token. This ensures secure and authenticated access to the Crawling API.
Let’s enhance our common script by bringing in the Crawling API.
from crawlbase import CrawlingAPI |
This updated code integrates the Crawlbase Crawling API for fetching HTML content, ensuring a reliable and efficient scraping process.
Example Output:
[ |
Managing Pagination for Extensive Data Retrieval
Handling pagination is a crucial aspect of scraping extensive data from Yellow Pages, where results span multiple pages. Yellow Pages typically employs a page parameter in the URL to signify different result pages. Let’s enhance the previous Python code to incorporate pagination seamlessly:
from crawlbase import CrawlingAPI |
This enhanced script introduces the page parameter in the constructed URL, enabling the seamless retrieval of data from multiple pages on YellowPages. Adjust the max_pages variable based on your requirements for extensive data retrieval.
Final Thoughts
Scraping Yellow Pages data is now a streamlined process, thanks to the efficiency of the Crawlbase Crawling API. By eliminating common challenges associated with web scraping, such as IP blocks and CAPTCHAs, Crawlbase ensures a smooth and reliable experience. Simplify your data extraction journey with Crawlbase and unlock the full potential of Yellow Pages scraping.
Here are some more guides you might be interested in:
How to Scrape Yelp
How to Scrape Expedia
How to Scrape Real Estate data from Zillow
How to Extract News Articles from BloomBerg
How to Scrape Stackoverflow Questions
If you encounter obstacles or seek further guidance, the Crawlbase support team is ready to assist. Your success in web scraping is our priority, and we look forward to supporting you on your scraping journey.
Frequently Asked Questions (FAQs)
Q. Is scraping data from Yellow Pages legal?
The legal aspects of scraping Yellow Pages data depend on the website’s terms of service. It is crucial to thoroughly review and comply with Yellow Pages’ terms and conditions before engaging in scraping activities. Always prioritize adherence to legal and ethical standards to avoid potential legal consequences.
Q. How can I prevent IP blocking while scraping Yellow Pages?
To mitigate the risk of IP blocking during Yellow Pages scraping, employing effective strategies is essential. Techniques such as rotating IP addresses and introducing random delays between requests can help. Crawlbase Crawling API offers advanced features like IP rotation, reducing the likelihood of getting blocked and ensuring a smoother scraping experience.
Q. Does Yellow Pages implement anti-scraping measures like captchas?
Yes, Yellow Pages may employ anti-scraping measures, including captchas, to protect its data. When utilizing a common scraping approach, encountering captchas is possible. However, Crawlbase Crawling API is equipped to handle such challenges seamlessly, providing an efficient solution that minimizes manual intervention and ensures reliable data extraction.
Q. Can I scrape Yellow Pages data at scale with the Crawlbase Crawling API?
Absolutely, the Crawlbase Crawling API is specifically designed for scalable web scraping. It includes features like pagination handling, asynchronous crawling, and IP rotation, making it highly suitable for extracting extensive data from Yellow Pages and other websites. This scalability ensures efficiency and reliability, even when dealing with large datasets.
Q. How do I extract data from Yellow Pages to Excel?
Extracting data from Yellow Pages and saving it to Excel is a straightforward process with Crawlbase’s Crawling API. Follow these steps:
Data Extraction: Use the Crawling API to retrieve data from Yellow Pages, ensuring you get the necessary information.
Format Data: Organize the extracted data into a suitable structure. For example, you may have a list of dictionaries where each dictionary represents the details of a business.
Export to Excel: Utilize Python libraries like pandas to convert your structured data into an Excel-friendly format. Pandas provides functions like to_excel that simplify this process.
import pandas as pd |
- Excel File: The above code creates an Excel file named
yellow_pages_data.xlsxcontaining your extracted data.
Remember, this is a simplified example, and adjustments may be needed based on your specific data structure and requirements. The key is to leverage Python libraries to efficiently handle the data extraction and Excel formatting processes.




