Instagram Proxies | Avoid Instagram bots while Scraping Instagram

This blog was originally posted on crawlbase blog.
To tap into Instagram’s colorful tapestry of users and content, you’ll need an ace up your sleeve: Instagram proxies. These savvy tools are your ticket to gathering data without a hitch, whether it’s for sharp marketing analysis or creating the next buzz-worthy app. Think of proxies as your backstage pass to Instagram’s wealth of insights—grabbing the info you need while staying under the radar. It’s smart, it’s smooth, and absolutely essential for the modern data wrangler.
Whether you’re someone who studies things, sells stuff, or makes software, understanding proxies is super important for this. Instagram Proxies are like a shield that hides who you are and helps you get around Instagram’s protections and restrictions.
In this guide, we’ll guide you through the basics of getting set up, using Crawlbase Smart Proxy to scrape Instagram and answering common questions in a special Frequently Asked Questions part.
Come along with us as we explore Instagram scraping with Instagram proxy. We want to make it easier for you to get the info you need without getting bothered by annoying bots. Let’s first head into the risks of scraping Instagram without Instagram Proxy. And if you want to head right into scraping Instagram, Click here.
Table of Contents
Overview of Instagram’s anti-scraping measures
How does Instagram Proxy help in Avoiding Bots while Scraping Instagram
Selecting an Instagram Proxy Provider: Key Considerations
Tips for optimizing proxy settings for Instagram scraping
Crawlbase Smart Proxy and its benefits
Setting Up the Environment
Using Crawlbase Smart Proxy with Instagram
Instagram Bot Risks & Proxy Necessity
Instagram bots are automated scripts or programs interacting with the platform, performing actions like liking posts, following users, or scraping data. While some bots serve legitimate purposes, others can be malicious, violating Instagram’s policies. Some of the risks associated with Instagram Bots are:
Account Suspension: Instagram can suspend or block accounts engaging in suspicious bot-like activities.
Data Privacy Concerns: Bots collecting data may infringe on user privacy, leading to ethical concerns.
Impact on Platform Integrity: Excessive bot activity can degrade the user experience and compromise the integrity of the platform.
To engage in responsible and ethical Instagram scraping, it’s crucial to counter the risks associated with bots. Effective proxies act as a shield, allowing you to scrape data while maintaining a respectful and secure approach. They enable you to:
Scrape Responsibly: Proxies help you collect data without overwhelming Instagram’s servers.
Maintain Anonymity: By masking your IP, proxies keep your scraping activities discreet, leading to full data privacy.
Adapt to Anti-Scraping Measures: Proxies assist in evading detection and navigating Instagram’s anti-scraping safeguards.
Why Use Proxies for Instagram Scraping
This section provides an overview of Instagram’s robust anti-scraping measures and highlights the significant benefits of incorporating Instagram proxies into your scraping endeavors.
Overview of Instagram’s Anti-Scraping Measures
As a popular and data-rich platform, Instagram employs stringent measures to safeguard user privacy and maintain the integrity of its ecosystem. Some of the key anti-scraping measures implemented by Instagram include:
Rate Limiting: Instagram restricts the number of requests a user can make within a specified time frame. Exceeding this limit raises suspicions and may result in temporary or permanent restrictions.
CAPTCHAs: To differentiate between human users and bots, Instagram employs CAPTCHAs at various points, disrupting automated scraping attempts.
Session Management: Instagram employs session-based tracking to monitor user activity. Unusual patterns, such as rapid and repetitive actions, trigger alarms and may lead to access restrictions.
Behavioral Analysis: Instagram analyzes user behavior to identify patterns associated with automated scraping. Deviations from typical human behavior may result in anti-bot measures being activated.
How does Instagram Proxy help in Avoiding Bots while Scraping Instagram
Anonymity and IP Rotation: Proxies act as a shield by hiding your actual IP address. Proxies also enable IP rotation, distributing requests across different addresses, making it harder for Instagram to detect a consistent pattern.
Overcoming Rate Limiting: Instagram’s rate-limiting measures can hinder scraping efforts, but proxies provide a solution. By distributing requests across multiple IP addresses, residential proxies help stay within acceptable limits, preventing temporary or permanent access restrictions.
CAPTCHA Bypass: Proxy servers can aid in overcoming CAPTCHAs, a common obstacle in automated scraping. By rotating IPs, you can navigate CAPTCHAs without jeopardizing your scraping activities.
Session Management Evasion: Rotating Residential Proxies play a crucial role in managing sessions effectively. By using different IP addresses, they help avoid triggering Instagram’s session-based tracking, allowing for seamless and undetected scraping.
Behavioral Camouflage: Rotating proxies contributes to mimicking human-like behavior in scraping activities. By rotating IP addresses and request patterns, they help avoid standing out as a bot, reducing the likelihood of detection.
Choosing the Right Proxy for Instagram
Selecting the appropriate proxy for Instagram scraping is a critical step. Here are the key factors to consider when choosing a proxy provider and provide valuable tips for optimizing your proxy settings specifically for Instagram scraping.
Selecting an Instagram Proxy Provider: Key Considerations
Reliability and Speed: Best proxy provider is the one that offers reliable and high-speed connections. This ensures that your scraping processes run smoothly without interruptions.
Location Diversity: Opt for a provider with a broad range of IP addresses in various geographic locations. This diversity helps mimic user behavior from different regions, which is crucial for comprehensive data gathering.
Type of Proxies Offered: Consider your scraping needs and choose a provider that offers the type of proxies suitable for your project. Whether it’s a residential or datacenter proxy, mobile proxy, Socks5, or a combination (proxy pool), ensure the provider aligns with your requirements.
Scalability: Choose a proxy provider that can accommodate the scale of your scraping project. Ensure they offer the flexibility to scale up or down based on your evolving needs.
Cost: While cost is a significant factor, it should be weighed against the quality of service. Balance your budget constraints with the features and reliability the proxy provider offers.
Customer Support: Assess the level of customer support provided by the proxy provider. Responsive and knowledgeable support can be invaluable when troubleshooting issues or seeking guidance.
Security and Privacy: Prioritize providers that prioritize data security and privacy. Ensure they have measures in place to protect your data and that their proxies comply with ethical standards.
Tips for Optimizing Proxy Settings for Instagram Scraping
Rotate IP Addresses: Constantly rotate IP addresses to mimic human behavior. This reduces the risk of being flagged as a bot by Instagram’s anti-scraping mechanisms.
Set Appropriate Request Headers: Configure your proxy settings to include appropriate request headers. This includes user-agent strings and other headers that make your requests look more like legitimate user activity.
Manage Request Frequency: Avoid rapid and excessive scraping. Set a reasonable request frequency to stay within Instagram’s rate limits and reduce the likelihood of detection.
Handle CAPTCHAs Effectively: Implement mechanisms to handle CAPTCHAs, such as integrating CAPTCHA-solving services or incorporating human-like interaction patterns into your scraping scripts.
Monitor and Adapt: Regularly monitor your scraping activities and adjust your proxy settings accordingly. Stay informed about any changes in Instagram’s anti-scraping measures and adapt your strategy accordingly.
Use Proxy Pools: If feasible, consider using proxy pools with a mix of different proxy types. This enhances rotation and diversifies your IP addresses, making detecting automated scraping more challenging for Instagram.
In summary, selecting the right proxy involves considering factors like reliability, performance, and customization options. Optimizing proxy settings for Instagram scraping requires attention to detail and an understanding of Instagram’s anti-scraping measures. Crawlbase Smart Proxy offers a user-friendly and efficient solution, seamlessly integrating with Instagram scraping and providing a range of benefits for a smoother and more effective data retrieval experience.
The Best Instagram Proxies of 2023
Following table shows some of the best Instagram proxies to scrape Instagram.
| Proxy Solution | Features and Benefits | Pricing | Pay As You Go Plan | Free Trial |
| Crawlbase Smart Proxy | - 200M+ Proxy Pool: A vast pool of proxies for diverse scraping needs. | Starting Price/Month: $99 | Yes | Yes |
| - Easy Integration: User-friendly solution for applications with no direct API support. | ||||
| - Rotating IP Mechanism: Dynamically rotates IPs to reduce detection risks. | ||||
| - Crawling API Compatibility: Seamlessly integrates with the Crawling API for advanced features. | ||||
| - Access Token Authorization: Ensures security through access token authentication. | ||||
| - JavaScript-Enabled Requests: Supports requests through a JavaScript-enabled headless browser. | ||||
| - Handle Anti-Scraping Technologies: Equipped to handle challenges posed by anti-scraping measures. | ||||
| ——————— | ————————————————————————————————— | ————————– | —————— | ———- |
| Apify | - User-Friendly Interface: Accessible platform with a visual editor for easy navigation. | Starting Price/Month: $49 | Yes | Yes |
| - Proxy Integration: Allows the use of custom proxies or their pool of residential proxies. | ||||
| - Data Storage and Management: Facilitates structured data storage for easy analysis. | ||||
| - Scheduled Crawling: Automates scraping tasks with a scheduling feature. | ||||
| ——————— | ————————————————————————————————— | ————————– | —————— | ———- |
| Brightdata | - Easy Data Scraping for Beginners: Simplifies data scraping for users of varying expertise. | Starting Price/Month: $500 | Yes | Yes |
| - Adapts to Site Changes: Can adapt to changes in website structure for effective scraping. | ||||
| - Collect as Much Data as Needed: Offers flexibility for extensive data collection. | ||||
| - Proxy-Like Integration: Enhances anonymity with a proxy-like integration. | ||||
| - Handle Anti-Scraping Technologies: Equipped to handle challenges posed by anti-scraping measures. | ||||
| ——————— | ————————————————————————————————— | ————————– | —————— | ———- |
| Smartproxy | - 40M+ Proxy Pool: A vast pool of proxies for diverse scraping needs. | Starting Price/Month: $50 | No | Yes |
| - Results in Raw HTML: Provides raw HTML results for in-depth data extraction. | ||||
| - Headless Scraping: Supports headless scraping for handling JavaScript-intensive pages. | ||||
| - Proxy-Like Integration: Integrates seamlessly, providing a proxy-like experience. | ||||
| - Handle Anti-Scraping Technologies: Equipped to tackle challenges posed by anti-scraping measures. |
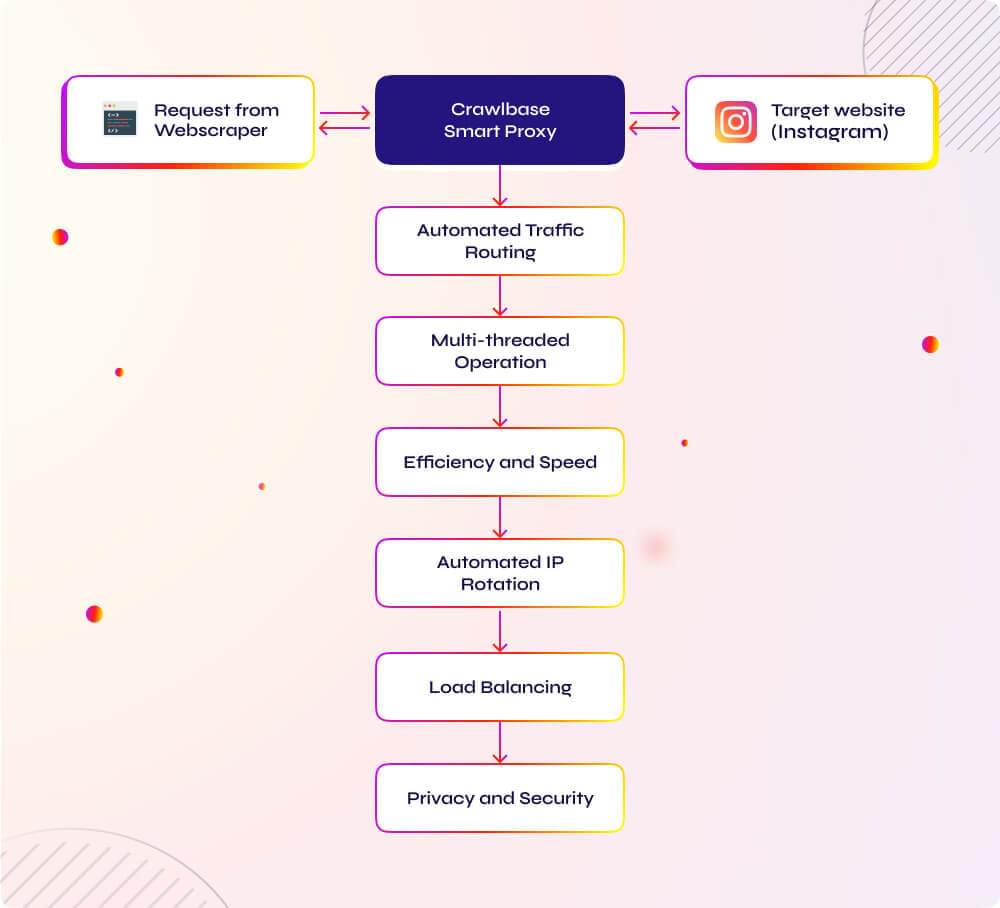
Scraping Instagram with Crawlbase Smart Proxy
Crawlbase Smart Proxy is an intelligent rotating proxy designed to seamlessly integrate with Instagram scraping. It acts as a bridge between your application and the Crawling API, simplifying the scraping process.
Setting up Your Environment
Before scraping Instagram pages, we have to ensure our setup is ready. This means we need to install the tools and libraries we’ll need, pick the right Integrated Development Environment (IDE), and get the important API credentials.
Installing Python and Required Libraries
The first step in setting up your environment is to ensure you have Python installed on your system. If you haven’t already installed Python, you can download it from the official website at python.org.
Once you have Python installed, the next step is to make sure you have the required libraries for this project.
- Requests: The
requestslibrary in Python simplifies the process of sending HTTP requests and handling responses. It provides an intuitive API for making HTTP calls, supporting various methods like GET, POST, and more, along with features for managing headers, parameters, and authentication. Install requests with pip:
- Requests: The
pip install requests |
Choosing the Right Development IDE
An Integrated Development Environment (IDE) provides a coding environment with features like code highlighting, auto-completion, and debugging tools. While you can write Python code in a simple text editor, an IDE can significantly improve your development experience.
Here are a few popular Python IDEs to consider:
PyCharm: PyCharm is a robust IDE with a free Community Edition. It offers features like code analysis, a visual debugger, and support for web development.
Visual Studio Code (VS Code): VS Code is a free, open-source code editor developed by Microsoft. Its vast extension library makes it versatile for various programming tasks, including web scraping.
Jupyter Notebook: Jupyter Notebook is excellent for interactive coding and data exploration. It’s commonly used in data science projects.
Spyder: Spyder is an IDE designed for scientific and data-related tasks. It provides features like a variable explorer and an interactive console.
Using Crawlbase Smart Proxy with Instagram
Now that we understand the significance of proxies and have explored the features of Crawlbase Smart Proxy, let’s dive into practical examples of making requests through Smart Proxy using Python. These examples cover a range of scenarios, including GET requests, POST requests, utilizing Crawling API parameters, and making requests with a JavaScript-enabled headless browser.
Obtaining Crawlbase API credentials
To use the Crawlbase Smart Proxy for Instagram scraping, you’ll need to sign up for an account on the Crawlbase website and get your Access Token. Now, let’s get you set up with a Crawlbase account. Follow these steps:
Visit the Crawlbase Website: Open your web browser and navigate to the Crawlbase website Signup page to begin the registration process.
Provide Your Details: You’ll be asked to provide your email address and create a password for your Crawlbase account. Fill in the required information.
Verification: After submitting your details, you may need to verify your email address. Check your inbox for a verification email from Crawlbase and follow the instructions provided.
Login: Once your account is verified, return to the Crawlbase website and log in using your newly created credentials.
Access Your API Token: You’ll need an access token to use the Crawlbase Smart Proxy. You can find your tokens here.
GET Requests with Crawlbase Smart Proxy
Making a GET request through Crawlbase Smart Proxy is straightforward. The following Python script demonstrates how to achieve this using the popular requests library:
import requests |
This script configures the Smart Proxy URL, specifies the target URL for the GET request, and utilizes the requests library to execute the request.
Example Output:

POST Requests with Crawlbase Smart Proxy
Performing a POST request through Smart Proxy is similar to a GET request. Here’s an example of sending both form data and JSON data:
Form Data POST Request:
In POST request with Form data,The data is typically encoded as a series of key-value pairs. The content type in the HTTP header is set to application/x-www-form-urlencoded. The data is sent in the body of the request in a format like key1=value1&key2=value2.
import requests |
JSON Data POST Request:
In POST request with JSON data, the data is formatted as a JSON (JavaScript Object Notation) object. The content type in the HTTP header is set to application/json. The data is sent in the body of the request in a JSON format like {"key1": "value1", "key2": "value2"}.
import requests |
These scripts showcase how to structure POST requests with both form data and JSON data through Crawlbase Smart Proxy.
Sample Output:
{ |
Using Crawling API Parameters
Crawlbase Smart Proxy allows you to leverage Crawling API parameters to customize your scraping requests. You can read more about Crawlbase Crawling API here. We will use scraper parameter with instagram-post scraper. Here’s an example:
import requests |
Example Output:
{ |
An important observation from the output JSON is the absence of meaningful data. This is attributed to Instagram’s use of JavaScript rendering on its frontend to dynamically generate content. To retrieve the desired data, a brief delay is required before capturing and scraping the HTML of the page. To achieve this, enabling JavaScript rendering becomes imperative. The subsequent section provides insights on how to enable JavaScript rendering for a more comprehensive data extraction process.
Requests with JavaScript-Enabled Headless Browser
Crawlbase Smart Proxy supports JavaScript-enabled headless browsers, providing advanced capabilities for handling JavaScript-intensive pages. As you know that Instagram use JavaScript to loads its content, So, it very important that we use the Crawlbase Smart Proxy with JavaScript rendering enabled to get the HTML with meaningful data. You have to pass javascript=true parameter. Here’s an example:
import requests |
Example Output:
{ |
These Python examples offer a practical guide on leveraging Crawlbase Smart Proxy for various Instagram scraping scenarios. Whether it’s simple GET or POST requests, utilizing Crawling API parameters, or harnessing JavaScript-enabled headless browsers, Crawlbase Smart Proxy provides a versatile and efficient solution for your scraping needs.
Final Words
Great job on grasping the basics of making Instagram scraping easier! Whether you’re just starting with web scraping or you’ve done it before, the tips we’ve shared here give you a good foundation. I hope this guide on scraping Instagram using Smart Proxy helped.
We have created another detailed guide on scraping Instagram with Crawler API using Python. If you want to read more about using proxies while scraping other channels, check out our guides on scraping Walmart using Smart Proxy and scraping Amazon ASIN with Smart Proxy.
You might be interested in Scraping Instagram and Facebook with Crawling API so I’m leaving those links here for you ;)
📜 Scrape Instagram using Python
📜 Scrape Facebook Data
Remember, web scraping might throw some challenges your way, but don’t worry too much. If you ever need help or get stuck, the friendly Crawlbase support team is here to lend a hand. Keep going, tackle those challenges, and enjoy the journey of successful web scraping. Happy scraping!
Frequently Asked Questions
Q. Why should I use proxies for Instagram scraping?
Proxies play a crucial role in Instagram scraping by providing anonymity and helping to avoid detection. Instagram employs anti-scraping measures, and proxies help distribute requests, rotate IPs, and mimic human behavior, reducing the risk of being flagged as a bot.
Q. What factors should I consider when choosing a proxy provider for Instagram scraping?
When selecting a proxy provider, consider factors such as reliability, speed, location diversity, IP rotation capabilities, scalability, and cost-effectiveness. A reputable provider with a history of reliability is essential to ensure a smooth and efficient scraping experience.
Q. How do I optimize proxy settings for Instagram scraping?
Optimizing proxy settings involves customizing HTTP headers, adjusting IP rotation frequency, scheduling scraping activities during off-peak hours, and implementing throttling mechanisms to simulate human browsing patterns. These measures help prevent rate limiting and reduce the likelihood of triggering anti-scraping measures.
Q. How does Crawlbase Smart Proxy enhance Instagram scraping compared to other solutions?
Crawlbase Smart Proxy offers a user-friendly and intelligent rotating proxy specifically designed for Instagram scraping. It seamlessly integrates with the Crawling API, providing dynamic IP rotation, access token authorization, and compatibility with advanced features like JavaScript-enabled headless browsers. This enhances scraping efficiency and reduces the risk of detection, making it a valuable solution for sophisticated Instagram scraping tasks.
Q. Is it legal to scrape Instagram?
Instagram’s policies prohibit unauthorized access to their data, and scraping may violate these terms. It’s essential to review and adhere to Instagram’s terms of service and data usage policies. It is crucial to comply with their laws, terms of service and rules outlined in the robots.txt to stay within legal boundaries.




