Reddit Scraper: Scrape Reddit Data in Python

This blog was originally posted to crawlbase blog.
In this blog post, we’ll build a Reddit Scraper for extracting data from Reddit with Python, focusing on getting important info from Reddit using the Crawlbase Crawling API. If you ever wanted to know how to collect Reddit data for analysis or research, you’re in the right spot. We’ll walk you through the steps to build a Reddit Scraper, so whether you’re new or experienced, it’ll be easy to understand.
To head right into the steps of scraping Reddit, Click here.
Understanding Reddit Data
Reddit is like a big collection of all sorts of things — posts, comments, and more. It’s a great place to find data for scraping, especially when using a Reddit Scraper. Before you start scraping Reddit, it’s important to know what kinds of data are there and figure out what exactly you want to take out.

Types of Data Available for Scraping Reddit:
Posts and Comments: These are what people share and talk about on Reddit. They tell you a bunch about what’s interesting or trending. For example, 80% of Reddit activity involves posts and comments.
User Profiles: Taking info from user profiles helps you learn what people like, what they’ve done, and how they’re part of different groups. There were 52M active users on Reddit in 2022.
Upvotes and Downvotes: This shows how much people liked or didn’t like posts and comments, giving you an idea of what’s popular. Upvotes make up 60% of interactions on Reddit.
Subreddit Info: Each subreddit is like a little community. Getting info on subreddits helps you know what makes each group different.If you’re using a Reddit Scraper, you can gather valuable insights into the characteristics of various subreddits.
Time Stamps: Knowing when posts and comments happen helps track trends and how active users are at different times.When utilizing a Reddit Scraper, timestamp data can be particularly useful for analyzing user activity patterns over time.
Identifying Target Data for Extraction:
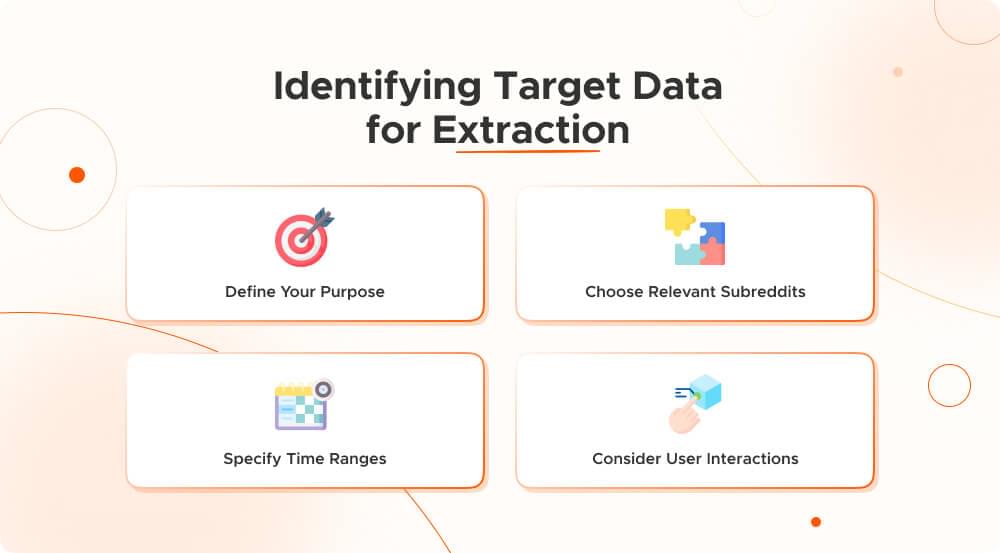
Define Your Purpose: Figure out why you need a Reddit Scraper. Are you looking for trends, what users do, or details about certain topics?
Choose Relevant Subreddits: Pick the specific parts of Reddit you’re interested in. This helps you get data that really matters to you.
Specify Time Ranges: Decide if you want recent info or data from the past. Setting a time range helps you focus on what you need.
Consider User Interactions: Think about what kind of interactions you want to know about—like what posts are popular, how users engage, or what people say in comments.
Knowing what data Reddit has and deciding what you want to get is the first step to scraping smart and getting the info you need.
Scrape Reddit Data: A Step-by-Step Guide
Setting Up the Environment
To create a free account on Crawlbase and receive your private token, just go to the account documentation section in your Crawlbase dashboard.
Follow these steps to install the Crawlbase Python library:
Ensure that you have Python installed on your machine. If not, you can download and install it from the official Python website.
Once Python is confirmed as installed, open your terminal and run the following command:
pip install crawlbase
This command will download and install the Crawlbase Python library on your system, making it ready for your web scraping project.
To create a file named “reddit-scraper.py,” you can use a text editor or an integrated development environment (IDE). Here’s how to create the file using a standard command-line approach:
Run this command:
touch reddit-scraper.py
- Executing this command will generate an empty reddit-scraper.py file in the specified directory. You can then open this file with your preferred text editor and add your Python code for web scraping.
Fetching HTML using the Crawling API
Once you have your API credentials, installed the Crawlbase Python library, and made a file named reddit-scraper.py, pick a Reddit post page to scrape. In this instance, we’ve selected the Reddit page with the best technology posts.
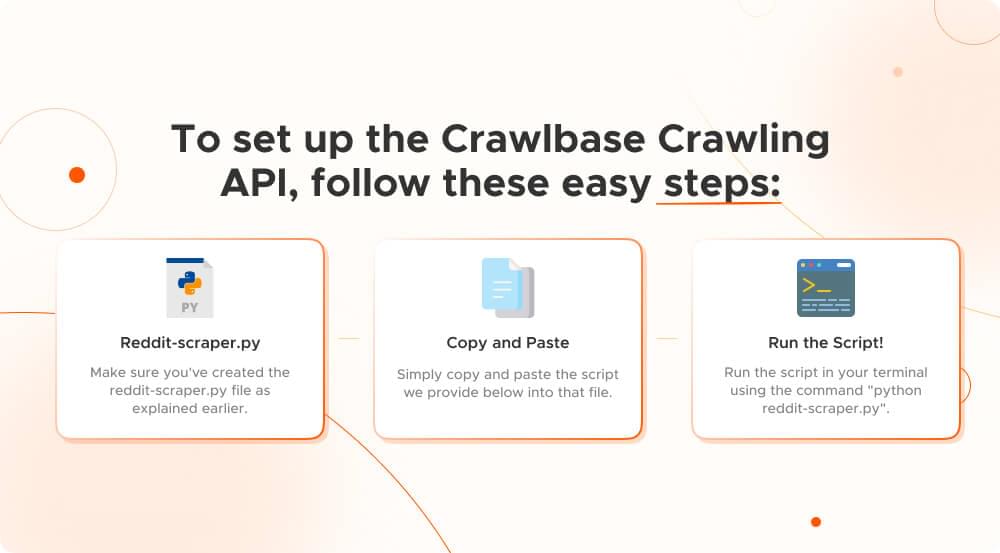
To set up the Crawlbase Crawling API, follow these easy steps:
Make sure you’ve created the reddit-scraper.py file as explained earlier.
Simply copy and paste the script we provide below into that file.
Run the script in your terminal using the command “python reddit-scraper.py”.
from crawlbase import CrawlingAPI |
The code above guides you on using Crawlbase’s Crawling API to collect information from a Reddit post page. You have to arrange the API token, specify the Reddit page URL which you wish to scrape and then make a GET request. When you execute this code, it will show the basic HTML content of the Reddit page on your terminal.
Scrape meaningful data with Crawling API Parameters
In the previous example, we figured out how to get the basic structure of a Reddit post page. However, most of the time, we don’t just want the basic code; we want specific details from the webpage. The good news is that the Crawlbase Crawling API has a special parameter called “autoparse” that makes it easy to extract key details from Reddit pages. To use this feature, you need to include “autoparse” when working with the Crawling API. This feature simplifies the process of gathering the most important information in a JSON format. To do this, you’ll need to make some changes to the reddit-scraper.py file. Let’s take a look at the next example to see how it works.
# Import the CrawlingAPI from the crawlbase module |
JSON Response:
Handling Rate Limits and Errors
Understanding Rate Limits on Reddit and Crawlbase
- Reddit API Rate Limits
Explanation of Reddit’s API rate-limiting policies
Different rate limits for various types of requests (e.g., read vs. write operations)
How to check the current rate limit status for your application
- Crawlbase Crawling API Rate Limits
Overview of rate limits imposed by Crawlbase
Understanding rate limits based on subscription plans
Monitoring usage and available quota
Implementing Rate Limit Handling in Python Scripts
- Pacing Requests for Reddit API
Strategies for pacing requests to comply with rate limits
Using Python libraries (e.g.,
time.sleep()) for effective rate limitingCode examples demonstrating proper rate limit handling
- Crawlbase API Rate Limit Integration
Incorporating rate limit checks in requests to the Crawlbase API
Adapting Python scripts to dynamically adjust request rates
Ensuring optimal usage without exceeding allocated quotas
Dealing with Common Errors and Exceptions
- Reddit API Errors
Identification of common error codes returned by the Reddit API
Handling cases such as 429 (Too Many Requests) and 403 (Forbidden)
Error-specific troubleshooting and resolution techniques
- Crawlbase API Error Handling
Recognizing errors returned by Crawlbase Crawling API
Strategies for gracefully handling errors in Python scripts
Logging and debugging practices for efficient issue resolution
- General Best Practices for Error Handling
Implementing robust try-except blocks in Python scripts
Logging errors for post-execution analysis
Incorporating automatic retries with exponential back off strategies
Data Processing and Analysis
Storing Scraped Data in Appropriate Formats
- Choosing Data Storage Formats
Overview of common data storage formats (JSON, CSV, SQLite, etc.)
Factors influencing the choice of storage format based on data structure
Best practices for efficient storage and retrieval
- Implementing Data Storage in Python
Code examples demonstrating how to store data in different formats
Using Python libraries (e.g., json, csv, sqlite3) for data persistence
Handling large datasets and optimizing storage efficiency
Cleaning and Preprocessing Reddit Data
- Data Cleaning Techniques
Identifying and handling missing or inconsistent data
Removing duplicate entries and irrelevant information
Addressing data quality issues for accurate analysis
- Preprocessing Steps for Reddit Data
Tokenization and text processing for textual data (posts, comments)
Handling special characters, emojis, and HTML tags
Converting timestamps to datetime objects for temporal analysis
Basic Data Analysis Using Python Libraries
- Introduction to Pandas for Data Analysis
Overview of the pandas library for data manipulation and analysis
Loading Reddit data into pandas DataFrames
Basic DataFrame operations for exploration and summary statistics
- Analyzing Reddit Data with Matplotlib and Seaborn
Creating visualizations to understand data patterns
Plotting histograms, bar charts, and scatter plots
Customizing visualizations for effective storytelling
- Extracting Insights from Reddit Data
Performing sentiment analysis on comments and posts
Identifying popular topics and trends
Extracting user engagement metrics for deeper insights
Conclusion
I hope this guide helped you scrape Reddit data effectively using Python and the Crawlbase Crawling API. If you’re interested in expanding your data extraction skills to other social platforms like Twitter, Facebook, and Instagram, check out our additional guides.
📜 How to Store Linkedin Profiles in MySQL
We know web scraping can be tricky, and we’re here to help. If you need more assistance or run into any problems, our Crawlbase support team is ready to provide expert help. We’re excited to help you with your web scraping projects!
Frequently Asked Questions
Can I scrape Reddit without violating its terms of service?
To scrape Reddit without breaking the rules, you gotta follow Reddit’s policies closely. Reddit lets you use public info, but if you’re using automated scraping, stick to their API rules. Don’t go too fast, follow the limits, and keep users’ privacy in mind.
If you scrape without permission, especially for money stuff, your account might get suspended. It’s super important to read and stick to Reddit’s rules, making sure you’re getting data in a good and legal way. Keep an eye out for any changes in their rules to make sure you’re still doing things right while being responsible with web scraping.
How do I avoid getting blocked while scraping Reddit?
To make sure you don’t get blocked while scraping Reddit, just follow some good habits. First, don’t flood Reddit’s servers with too many requests at once keep it reasonable. Act like a human by putting random breaks between your requests, and don’t scrape a lot during busy times. Follow the rules by not scraping anything private or sensitive. Keep your scraping code up to date in case Reddit changes things. By scraping responsibly, you boost your chances of staying unblocked.
How to analyze and visualize the scraped Reddit data?
To understand the info you got from Reddit, you need to follow some steps. First, arrange the data neatly into groups like posts, comments, or user stuff. Use Python tools like Pandas to clean up the data. Make graphs and charts with Matplotlib and Seaborn to see what’s going on. Check out trends, hot topics, or how users are involved by looking at the numbers.
To catch the vibe of the content, tools like TextBlob can help with word clouds and sentiment analysis. Make your data look cool with interactive stuff using Plotly. In short, by mixing up data organizing, number stuff, and cool pictures, you can learn a lot from the Reddit info you scraped.
What kind of data can I extract from Reddit using web scraping?
When scraping Reddit, you can get lots of info stuff from posts, comments, and user pages, plus how much people liked or disliked things. You get to choose what subreddit, time, or user you want info from. This helps gather different details, like what’s popular, what users like, and how the community interacts. Just remember, it’s crucial to follow Reddit’s rules while doing this to keep things fair and square. Stick to what’s right, and you’ll be on the good side of web scraping on Reddit.




