Web Scrape Expedia Using JavaScript

This blog is originally posted to crawlbase blog.
Expedia is a popular website where people book flights, hotels, and more. Among the giants in the business of online travel booking, Expedia stands out as a leading platform, offering a plethora of travel options to millions. But have you ever wondered how you could use this data for your own purposes, be it for research, analysis, or simply to get the best deals? Welcome to the world of web scraping!
In this blog, we’ll delve into the fascinating journey of scraping Expedia using JavaScript, unlocking a realm of possibilities and opportunities. We’ll use the Crawlbase Crawling API to help us scrape Expedia smoothly.
Table of Contents
Diving into Expedia’s Search Paths
Expedia’s Front-end Technologies
Structure of Expedia Search Results Page
Identifying Data Points for Scraping
Installing NodeJS and NPM
Setting the Project Directory
Installing Required Libraries
Choosing the Right Development IDE
Getting a Token for Crawlbase Crawling API
Constructing the URL for Expedia Search
Inspecting HTML to Get CSS Selectors
Accessing HTML Content with Crawlbase Crawling API
Data Extraction from Expedia Search Outcomes
Understanding Pagination on Expedia
Handling Pagination Efficiently
Storing Extracted Data in CSV Format
Storing Extracted Data in SQLite Database
Why Scrape Expedia for Travel Data?
These days, planning a trip has become more accessible and personalized, thanks to online platforms like Expedia. However, with so many options and variables, making informed decisions can be overwhelming. This is where scraping Expedia for travel data becomes invaluable.
Scraping allows us to gather vast amounts of data from Expedia’s website, such as flight prices, hotel reviews, and availability. By analyzing this data, travelers can make more informed choices, find the best deals, and even uncover hidden gems that might not be immediately obvious.
For businesses in the travel industry, scraping Expedia provides a competitive edge. It offers insights into market trends, competitor pricing strategies, and customer preferences, enabling businesses to tailor their offerings and strategies effectively.
In essence, scraping Expedia for travel data empowers both individual travelers and businesses to navigate the complexities of travel planning more efficiently, ensuring better experiences and outcomes.
Understanding Expedia Website
Navigating the intricate web of online travel platforms, Expedia stands as a prominent player, offering a vast array of travel options at the fingertips of its users. To harness the full potential of Expedia’s offerings and glean valuable insights, it’s essential to understand the underlying structure and technologies powering its website.
Diving into Expedia’s Search Paths
Expedia offers various search options to cater to different travel needs. Each search path is designed to help users find specific types of accommodations or activities. Here’s a breakdown of some of the main search paths available:
Available Searches on Expedia

Cruise Search: This path is designed for users looking to book cruises. Example format:
https://www.expedia.com/Cruise-Search?querparams...Car Search: For those in need of rental cars, this path streamlines the search process. Example format:
https://www.expedia.com/carsearch?querparams...Flight Search: This path focuses on finding the best flight options for travelers. Example:
https://www.expedia.com/Flight-Search?querparams...Hotel Search: Specifically tailored for hotel bookings, this path is our focus for this example. Example format:
https://www.expedia.com/Hotel-Search?querparams...Things To Do: For travelers seeking activities and experiences, this path offers a curated list of options. Example format:
https://www.expedia.com/things-to-do/search?querparams...
Example: Hotel Search on Expedia
For the purpose of this blog, we’ll be delving into the Hotel Search feature of Expedia. Let’s take a closer look at a sample URL for hotel searching:
In this URL, you can see various parameters that help tailor the search:
adults=2: Specifies the number of adults.rooms=1: Indicates the number of rooms needed.destination=Dubai%2C%20Dubai%2C%20United%20Arab%20Emirates: Defines the destination, in this case, Dubai, United Arab Emirates.startDate=2023-12-26: Sets the start date for the stay.endDate=2023-12-30: Sets the end date for the stay.
Understanding these search paths and parameters is essential for effective scraping, as it allows us to target specific data and tailor our scraping approach accordingly.
Expedia’s Front-end Technologies
Expedia employs a blend of front-end technologies to deliver its user-friendly interface and dynamic functionalities:
HTML/CSS: The foundational languages for structuring and styling web content, ensuring a visually appealing and responsive design.JavaScript: Powering interactive elements and dynamic content loading, enhancing user experience and interactivity.AJAX: Facilitating seamless data retrieval and updates without requiring a full page reload, contributing to a smoother browsing experience.
Structure of Expedia Search Results Page
Expedia’s search results page is meticulously designed to provide users with a seamless booking experience. At its core, the search page typically comprises the following elements:
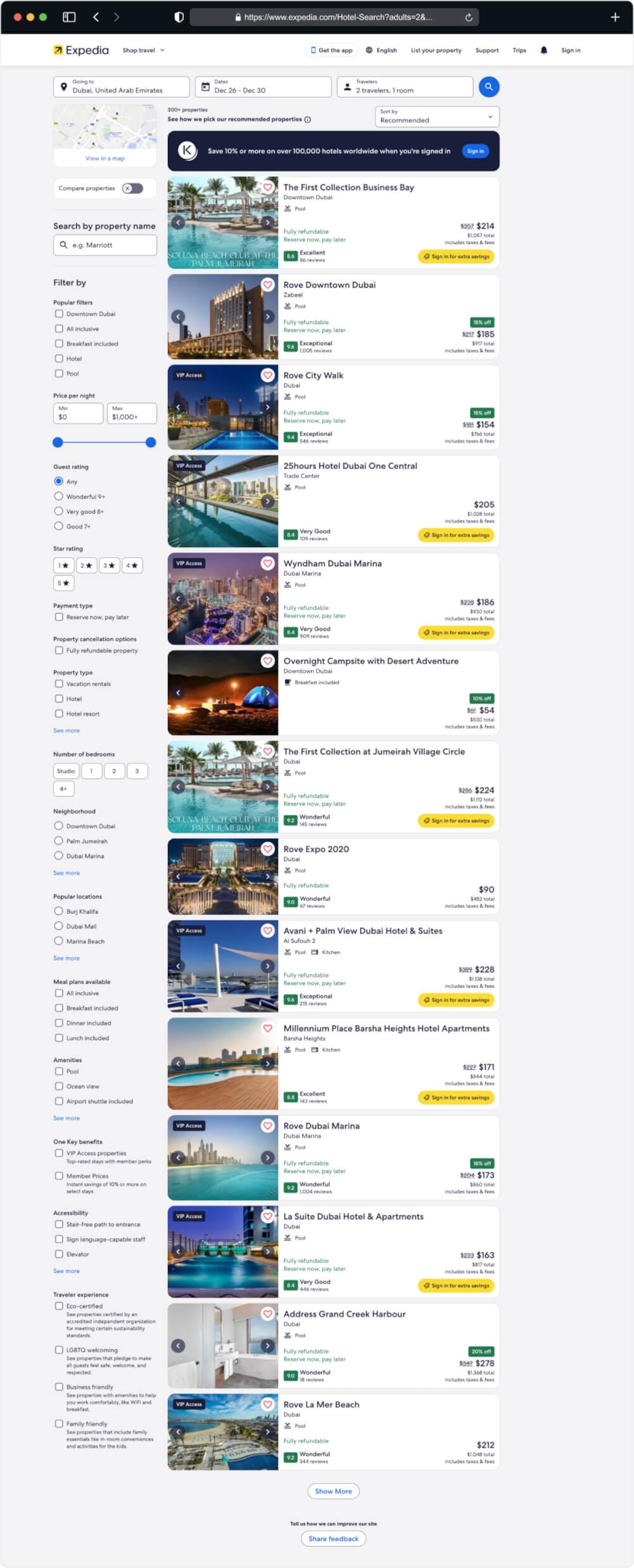
Search Bar: The central feature allowing users to input their travel preferences, including destination, dates, and other relevant details.
Filters and Sorting Options: Positioned alongside search results, these tools enable users to refine their search based on various criteria such as price, duration, airline, and more.
Search Results: Displayed prominently, this section showcases available flights, hotels, or packages matching the user’s criteria, often accompanied by relevant details and images.
Additional Information: Supplementary sections may include travel guides, recommendations, and customer reviews, offering users a comprehensive view of their options.
Identifying Data Points for Scraping
To extract meaningful data from Expedia, it’s crucial to identify and target specific data points relevant to your objectives. Common data points for scraping include:
Flight Details: Including airline, flight number, departure and arrival times, duration, and price.
Hotel Information: Such as hotel name, location, amenities, ratings, and pricing.
User Reviews and Ratings: Offering insights into the quality and experience of flights, hotels, or packages.
Additional Fees and Taxes: Providing transparency on any extra costs associated with bookings.
By gaining a deeper understanding of Expedia’s search paths, mastering its underlying technologies, grasping its website architecture, and pinpointing essential data elements, you’ll be well-equipped to embark on a successful scraping journey, extracting valuable insights and optimizing your travel endeavors.
Setting Up Your Development Environment
Before you can dive into web crawling with JavaScript and the Crawlbase Crawling API, it’s essential to prepare your development environment. This section provides a concise yet detailed guide to help you set up the necessary tools and libraries for seamless e-commerce website crawling.
Installing NodeJS and NPM
NodeJS and NPM (Node Package Manager) are the backbone of modern JavaScript development. They allow you to execute JavaScript code outside the confines of a web browser and manage dependencies effortlessly. Here’s a straightforward installation guide:
NodeJS: Visit the official NodeJS website and download the latest LTS (Long-Term Support) version tailored for your operating system. Execute the installation following the platform-specific instructions provided.
NPM: NPM comes bundled with NodeJS. After NodeJS installation, you automatically have NPM at your disposal.
To confirm a successful installation, open your terminal or command prompt and run the following commands:
node --version |
These commands will display the installed versions of NodeJS and NPM, ensuring a smooth setup.
Setting the Project Directory
To begin, create a directory using the mkdir command. It is called ecommerce crawling for the sake of this tutorial, but you can replace the name with one of your choosing:
mkdir expedia\ scraping |
Next, change into the newly created directory using the cd command:
cd expedia\ scraping/ |
Initialize the project directory as an npm package using the npm command:
npm init --y |
The command creates a package.json file, which holds important metadata for your project. The --y option instructs npm to accept all defaults.
After running the command, the following output will display on your screen:
Wrote to /home/hassan/Desktop/ecommerce crawling/package.json: |
Inside your project directory, create a new file named expedia-scraping.js. This is where you’ll place the scraping code.
touch expedia-scraping.js |
Installing Required Libraries
For proficient web crawling and API interactions, equip your project with the following JavaScript libraries using NPM:
# Install the required libraries |
Here’s a brief overview of these vital libraries:
Cheerio: As an agile and high-performance library, Cheerio is designed for efficiently parsing HTML and XML documents. It plays a pivotal role in easily extracting valuable data from web pages.
Crawlbase: Crawlbase simplifies interactions with the Crawlbase Crawling API, streamlining the process of website crawling and data extraction.
SQLite3: SQLite3 stands as a self-contained, serverless, and zero-configuration SQL database engine. It will serve as your repository for storing the troves of data collected during crawling.
csv-writer: It simplifies the process of writing data to CSV files, making it easy to create structured data files for storage or further analysis in your applications. It provides an intuitive API for defining headers and writing records to CSV files with minimal code.
Choosing the Right Development IDE
Selecting the right Integrated Development Environment (IDE) can significantly boost productivity. While you can write JavaScript code in a simple text editor, using a dedicated IDE can offer features like code completion, debugging tools, and version control integration.
Some popular IDEs for JavaScript development include:
Visual Studio Code (VS Code): VS Code is a free, open-source code editor developed by Microsoft. It has a vibrant community offers a wide range of extensions for JavaScript development.
WebStorm: WebStorm is a commercial IDE by JetBrains, known for its intelligent coding assistance and robust JavaScript support.
Sublime Text: Sublime Text is a lightweight and customizable text editor popular among developers for its speed and extensibility.
Choose an IDE that suits your preferences and workflow.
Getting a Token for Crawlbase Crawling API
To access the Crawlbase crawling API, you need an access token. To get the token, you first need to create an account on Crawlbase. Now, let’s get you set up with a Crawlbase account. Follow these steps:
Visit the Crawlbase Website: Open your web browser and navigate to Crawlbase signup page to begin the registration process.
Provide Your Details: You’ll be asked to provide your email address and create a password for your Crawlbase account. Fill in the required information.
Verification: After submitting your details, you may need to verify your email address. Check your inbox for a verification email from Crawlbase and follow the instructions provided.
Login: Once your account is verified, return to the Crawlbase website and log in using your newly created credentials.
Access Your API Token: You’ll need an API token to use the Crawling API. You can find your tokens on this link.
Crawlbase provides two types of tokens: the Normal Token (TCP) for static website pages and the JavaScript Token (JS) for dynamic or JavaScript rendered website pages. For the website like Expedia, you need JS Token. You can read more here.
With NodeJS, NPM, essential libraries, and your API token in place, you’re now ready to dive into the Expedia scraping using JavaScript and the Crawlbase Crawling API. In the following sections, we’ll guide you through the process step by step.
Scraping Expedia Search Results
The vast repository of travel information and options available on Expedia is a treasure trove for travelers and analysts alike. By scraping Expedia’s search results, one can obtain rich data insights that can be leveraged for various purposes. In this segment, we’ll walk you through the meticulous process of scraping Expedia’s search results step by step.
Constructing the URL for Expedia Search
Every online platform operates on a structured framework, and Expedia is no exception. To initiate a search or scrape data, one needs to construct the appropriate URL that encapsulates the desired search parameters.
For instance, if you’re interested in exploring hotel options in Paris for a weekend getaway, your URL might look something like:
Breaking down the components:
Base URL: https://www.expedia.com/Hotel-Search
Parameters:
adults=2: Specifies the number of adults.rooms=1: Indicates the number of rooms needed.destination=Paris: Specifies the destination in URL-encoded format.startDate=2023-12-26: Sets the start date for the stay.endDate=2023-12-30: Sets the end date for the stay.
Constructing such URLs with the right parameters is the foundation of scraping accurate and relevant data from Expedia.
Accessing HTML Content with Crawlbase Crawling API
Once you’ve meticulously crafted the requisite URL, the subsequent imperative is to extract the webpage’s HTML content. The Crawlbase Crawling API emerges as an instrumental asset in this endeavor. Below delineates a structured approach to facilitate this operation:
API Configuration: Initialize the Crawlbase Crawling API, integrating your specific API token.
Request Execution: Employ the API to fetch the HTML content from the designated URL. To further optimize your scraping process, it’s essential to understand the parameters you can employ with the Crawlbase Crawling API:
ajax_wait: A boolean parameter indicating whether the API should wait for AJAX content to load. Setting it to true ensures that asynchronous content is fully rendered before capturing the HTML.
page_wait: Specifies the duration, in milliseconds, for which the API should wait after the page loads before capturing the HTML. Adjusting this value can help in cases where content takes longer to become fully interactive or when dealing with sites that have intricate loading sequences.
Here’s a refined example illustrating the integration of these parameters:
const { CrawlingAPI } = require('crawlbase'); |
Execution Instructions:
Copy and paste the above code into the expedia-scraping.js file.
To execute the script, navigate to your project directory in the terminal and run:
node expedia-scraping.js |
This will display the retrieved HTML in your terminal.
Inspecting HTML to Get CSS Selectors
With the HTML content obtained from the property page, the next step is to analyze its structure and pinpoint the location of pricing data. This task is where web development tools and browser developer tools come to our rescue. Let’s outline how you can inspect the HTML structure and unearth those precious CSS selectors:
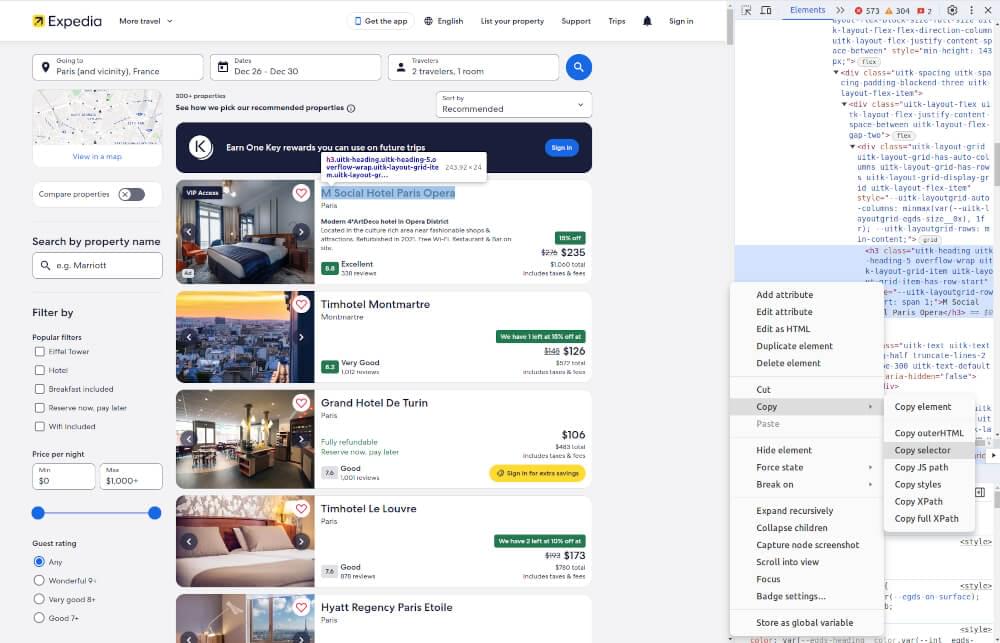
Open the Web Page: Navigate to the Airbnb website and land on a property page that beckons your interest.
Right-Click and Inspect: Employ your right-clicking prowess on an element you wish to extract (e.g., a Buy Box) and select “Inspect” or “Inspect Element” from the context menu. This mystical incantation will conjure the browser’s developer tools.
Locate the HTML Source: Within the confines of the developer tools, the HTML source code of the web page will lay bare its secrets. Hover your cursor over various elements in the HTML panel and witness the corresponding portions of the web page magically illuminate.
Identify CSS Selectors: To liberate data from a particular element, right-click on it within the developer tools and gracefully choose “Copy” > “Copy selector.” This elegant maneuver will transport the CSS selector for that element to your clipboard, ready to be wielded in your web scraping incantations.
Once you have these selectors, you can proceed to structure your data scraper to extract the required information effectively.
Data Extraction from Expedia Search Outcomes
Upon successfully retrieving the HTML content, the subsequent step is the meticulous extraction of essential data elements. For this task, we harness the capabilities of parsing tools, with the cheerio library in JavaScript standing out as our primary choice.
Here’s a refined approach to the process:
HTML Parsing: Integrate the acquired HTML content into a parsing framework like Cheerio, enabling seamless navigation through the Document Object Model (DOM).
Precise Data Extraction: Deploy CSS selectors strategically to isolate and extract crucial data fragments from the HTML structure. This includes pivotal metrics such as hotel names, nightly rates, cumulative prices, ratings, and user review counts.
Data Structuring: As the extraction unfolds, methodically organize the harvested data into structured formats, be it JSON or CSV. This ensures clarity, accessibility, and facilitates subsequent data analysis or archival.
To align with our earlier scripting endeavors, the revised code section remains:
const { CrawlingAPI } = require('crawlbase'); |
Using the CrawlingAPI from the ‘crawlbase’ library, the script fetches the HTML content of a predefined Expedia URL. This content is then parsed using the cheerio library, a server-side implementation similar to jQuery, to extract essential hotel details like names, prices, ratings, and reviews. After processing, the script outputs the extracted data to the console. Notably, error handling is incorporated to manage any potential issues during the scraping operation.
Running above code will give output like this:
[ |
Handling Pagination in Expedia
Scraping platforms like Expedia often present their search results through a series of pages, commonly known as pagination. To ensure that we capture all the desired data, we need to account for this pagination during the scraping process. Below, we’ll explore how to handle pagination effectively when scraping Expedia using the Crawlbase library.
Understanding Pagination on Expedia
Pagination on Expedia is designed to streamline user experience by displaying search results in manageable chunks. As you scroll or navigate through these results, the platform dynamically loads additional listings.
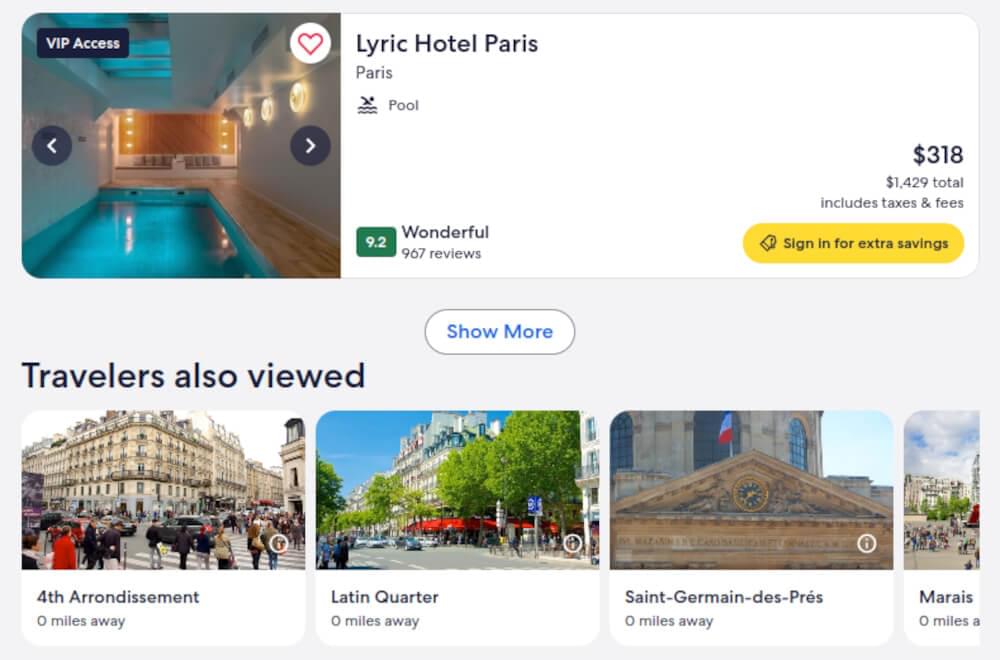
To extract all listings programmatically, it becomes necessary to interact with the “Show More” button or its equivalent until no further results load.
Handling Pagination Efficiently
To effectively handle pagination, the Crawlbase Crawling API provides a css_click_selector parameter. This parameter allows us to programmatically click an element on the page, triggering the loading of additional content.
When using the JavaScript token, the css_click_selector parameter expects a valid CSS selector, be it an ID (e.g., #some-button), a class (e.g., .some-other-button), or an attribute (e.g., [data-tab-item="tab1"]). It’s crucial to ensure the CSS selector is correctly encoded to avoid any discrepancies.
Let’s incorporate this into our existing script:
const { CrawlingAPI } = require('crawlbase'); |
In the output, you will notice that there are more results than in the previous run.
Storing Scraped Data
After successfully extracting data from platforms like Expedia, it’s imperative to have a robust system for data storage. This ensures that the data remains accessible, organized, and can be efficiently used for various purposes in the future. Let’s explore two systematic approaches to store your scraped data: using CSV files and leveraging SQLite databases.
Storing Extracted Data in CSV Format
CSV (Comma Separated Values) stands as a standard for data interchange due to its simplicity and compatibility with various software. By saving scraped data in CSV format, you ensure its widespread usability.
You can modify the existing script as follows to integrate this update.
const { CrawlingAPI } = require('crawlbase'); |
The saveToCSV function utilizes the createCsvWriter module to define a CSV writer configuration. This configuration specifies that the data should be written to a file named hotels.csv, and it provides the structure of the CSV with headers like “Name”, “Price Per Night”, “Total Price”, “Rating”, and “Reviews”. The extracted hotel data, previously organized into an array of objects, is then written to this CSV file.
hotels.csv Preview:
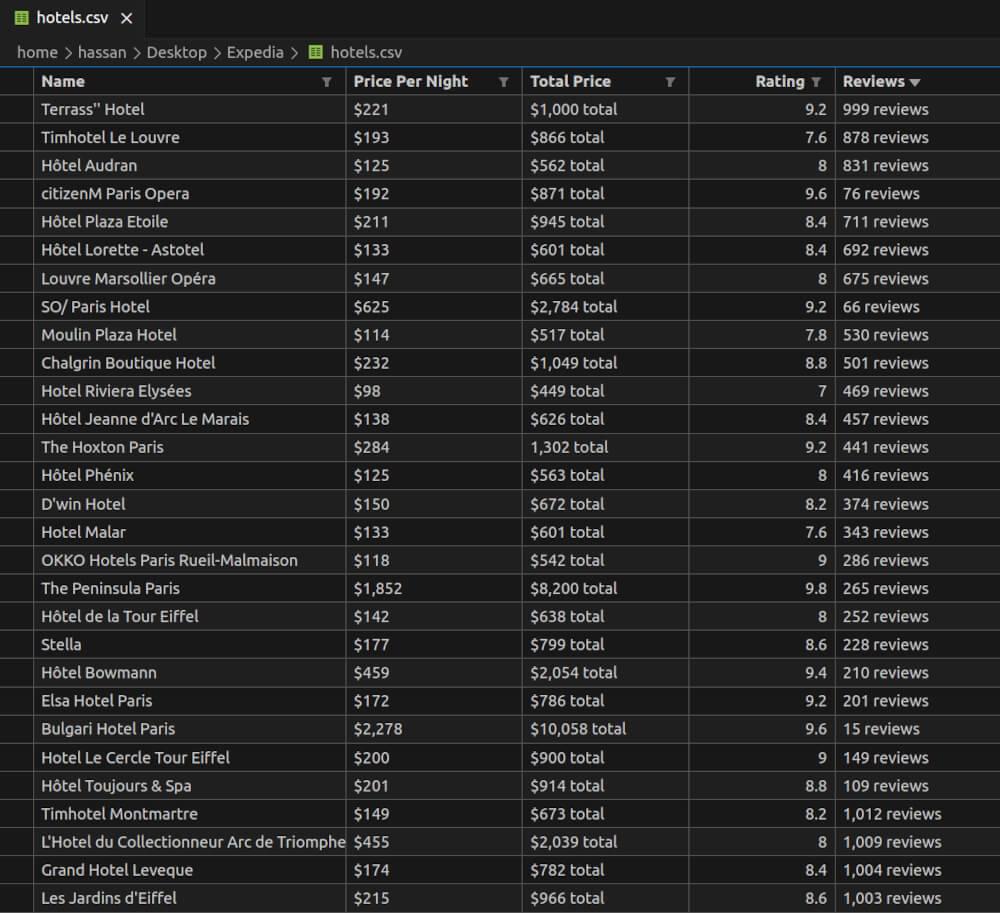
Storing Extracted Data in SQLite Database
SQLite offers a reliable, serverless solution for data storage. By using an SQLite database, you can benefit from structured querying capabilities, ensuring data integrity and efficient retrieval.
You can modify the script as follows to integrate this update.
const { CrawlingAPI } = require('crawlbase'); |
The saveToSQLite function is designed to store hotel data into an SQLite database named hotels.db. Upon invocation, it establishes a connection to the SQLite database using the sqlite3 module. Before inserting any data, the function ensures that a table named hotels exists in the database; if not, it creates this table with columns for an ID (as the primary key), hotel name, price per night, total price, rating, and number of reviews. Subsequently, the function iterates over each hotel object passed to it, executing an insertion query to add the hotel’s details into the hotels table. Once all the data has been inserted, the function closes the database connection, ensuring that the data is safely persisted within the SQLite database.
hotels Table Preview:
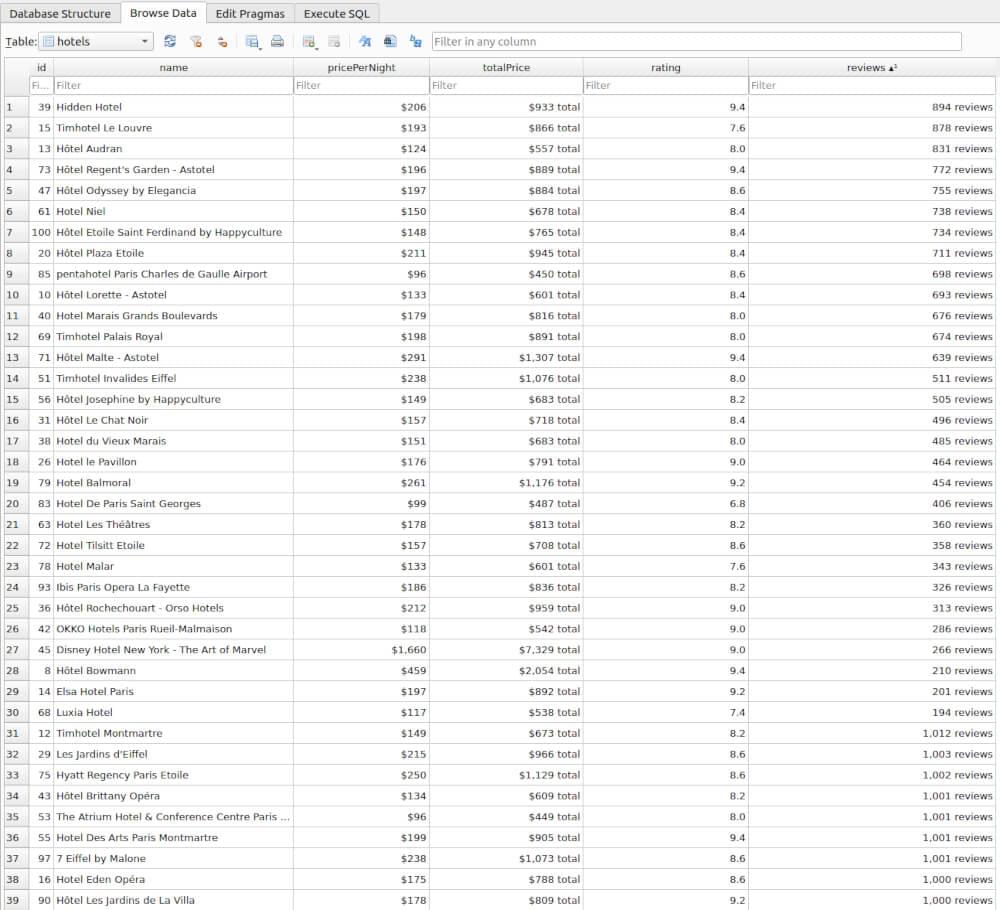
Final Words
Congrats! You took raw data straight from a web-page and turned it into structured data in JSON file. Now you know every step of how to build a Expedia scraper in JS!
This guide has given you the basic know-how and tools to easily scrape Expedia search results using JS and the Crawlbase Crawling API. Keep reading our blogs for more tutorials like these. Some of the links are given below:
And, If you want to browse other JavaScript projects, we recommend checking the links below:
Mastering E-Commerce Web Crawling with JavaScript
How to Scrape G2 Using JavaScript
How to Scrape eBay using JavaScript
Till then, If you encounter any issues, feel free to contact the Crawlbase support team. Your success in web scraping is our priority, and we look forward to supporting you on your scraping journey.
Frequently Asked Questions
Is it legal to scrape data from Expedia?
Web scraping, especially from large commercial platforms like Expedia, exists in a legal gray area. While some jurisdictions and terms of service explicitly prohibit scraping, others might not have clear guidelines. It’s crucial to thoroughly review Expedia’s terms of service or consult with legal experts familiar with internet laws in your region. Remember, even if scraping isn’t explicitly prohibited, it’s essential to practice ethical scraping, ensuring you’re not violating any terms or causing undue strain on Expedia’s servers. Additionally, always respect robots.txt files, which websites often use to indicate which parts of the site can or cannot be scraped.
Why use JavaScript libraries like cheerio for scraping?
JavaScript libraries such as cheerio are invaluable tools for web scraping tasks. Unlike traditional browsers, which execute JavaScript to render pages, cheerio operates on the server-side, providing a simulated DOM environment. This server-side approach eliminates the need for rendering the entire webpage, resulting in faster data extraction processes. Developers can employ familiar jQuery-like syntax to navigate and extract specific HTML elements, simplifying complex scraping tasks and optimizing performance.
How can I handle rate limiting or IP bans when scraping Expedia?
Websites, including Expedia, employ various mechanisms like rate limiting or IP bans to deter and manage aggressive or unauthorized scraping activities. If you notice delays or get blocked, it’s a sign that your scraping activity might be too aggressive. To navigate these challenges:
Implement Delays: Introduce random or systematic delays between your scraping requests to mimic human behavior and reduce the load on the server.
Use Proxies: Rotate through a pool of proxies to mask your IP address and distribute requests, making it harder for websites to track and block your scraping activity.
Rate Limiting Tools: Consider integrating middleware or tools designed to manage and respect rate limits, adjusting your scraping speed dynamically based on server responses.
Additionally, for a streamlined and hassle-free experience, platforms like Crawlbase offer dedicated Crawling APIs. Leveraging such services can further automate and optimize your scraping endeavors, providing an added layer of sophistication in managing potential restrictions.
What should I do with the scraped data from Expedia?
The ethical and legal use of scraped data is paramount. Before using the scraped data:
Purpose of Use: Clearly define your intentions. If you’re analyzing data for personal insights or academic research, ensure your activities align with the website’s terms of service.
Commercial Usage: If you plan to use the data commercially, always obtain explicit permission from Expedia or the respective website. Selling or re-purposing scraped data without consent can lead to legal repercussions and tarnish your reputation in the industry.
Data Privacy: Always prioritize data privacy. Ensure that any personal or sensitive information extracted from Expedia or other sources is handled securely, respecting individual privacy rights and regulations.




