Web Scraping for Machine Learning 2024

This blog is originally posted to the Crawlbase blog.
Web scraping gives you the ability to collect vast amounts of data in a structured format, allowing you to train your machine learning models more effectively. By automatically extracting data from different sources, you can gather insights, spot trends, and make data-driven predictions.
But how does web scraping work? What web crawling techniques and scraping tools can you use to scrape data? And most importantly, how can you use web scraping to enhance your machine learning projects?
By the end of this article, you’ll know how you can take your machine learning endeavors to new heights.
What is Machine Learning?
Machine learning is a subfield of artificial intelligence that focuses on the development of algorithms and models that enable computers to learn and make predictions or decisions without being explicitly programmed. Through the analysis of data, machine learning algorithms can identify patterns and relationships, and use them to make accurate predictions or decisions.
Machine learning finds applications in various domains, such as healthcare, finance, marketing, and more. It has revolutionized industries by automating complex tasks, improving accuracy and efficiency, and uncovering hidden insights from large datasets.
The Importance of Web Scraping in Machine Learning
The success of your machine learning projects heavily relies on the quality and quantity of data you have at your disposal. Without web scraping, obtaining such data would be a time-consuming and manual process. Alongside this, your models will struggle to make accurate predictions or provide meaningful insights.
By scraping websites, you can access data that is not readily available through traditional means. This includes user-generated content, product reviews, social media data, news articles, and much more.
Web scraping empowers researchers and businesses to explore new domains and gather insights from diverse sources. It opens up possibilities for innovation and discovery by leveraging the wealth of information available across the web.
With a diverse dataset obtained through web scraping, you can train your machine learning models to recognize patterns, make predictions, and gain valuable insights. Whether you’re building a recommendation system, sentiment analysis tool, or fraud detection algorithm, web scraping can provide the data foundation you need for success.
Web scraping also enables you to keep your machine learning models up-to-date with the latest information. By regularly scraping websites, you can ensure that your models are trained on the most recent data, allowing them to adapt and provide accurate predictions even in a rapidly evolving environment.
Uses of Scraped Data for Machine Learning
Here are some common ways you can use web scraped data for machine learning:
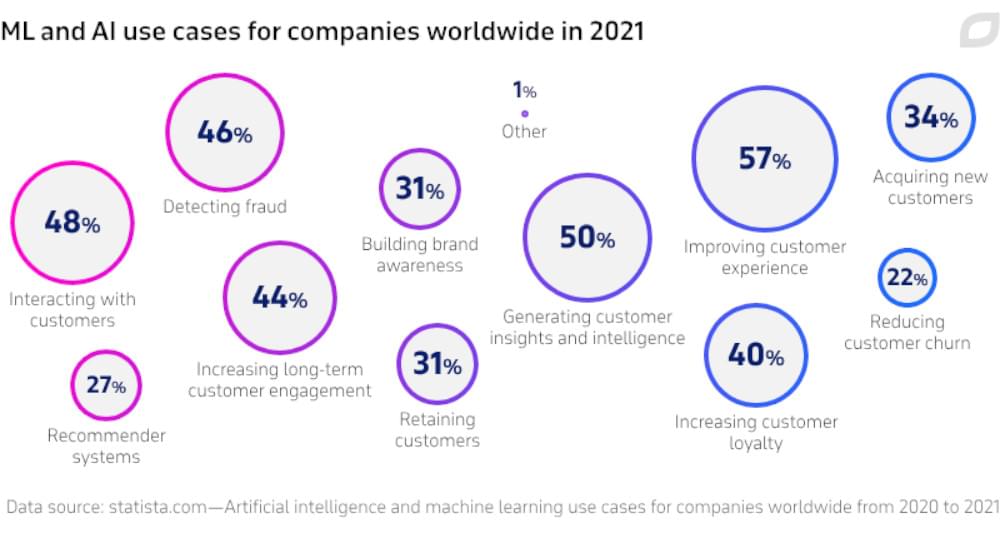
Feature engineering:
Web scraped data can provide valuable features for your machine learning models. You can extract features such as text sentiment, image features, or social network metrics from the scraped data to enhance the predictive power of your models.
Training machine learning models
Use the scraped data as the training dataset for your machine learning models. Depending on the nature of your project, you can use supervised learning, unsupervised learning, or semi-supervised learning algorithms to train your models.
Data augmentation:
If your machine learning dataset is limited, web scraped data can be used to augment it. By combining your existing dataset with the scraped data, you can increase the diversity and size of your training data, leading to more robust and accurate models.
Model evaluation and validation:
Use the scraped data as a test dataset to evaluate and validate the performance of your machine learning models. By comparing the predictions of your models with the ground truth labels in the scraped data, you can assess their accuracy and generalization capabilities.
Access real-time data:
Traditional data sources, such as databases, may not always provide up-to-date information. However, by scraping data directly from websites, we can ensure that our models are trained on the most recent and relevant data available. sThis is particularly important in domains where data is constantly changing, such as stock market prediction or weather forecasting.
Analyze user behavior:
Web scraping also allows us to gather data from websites that do not provide APIs or other means of accessing their data programmatically. This opens up new possibilities for machine learning applications, as we can now extract valuable information from sources that were previously inaccessible. For example, we can scrape data from online forums to analyze user behavior and preferences, or extract data from product listings on e-commerce websites to train recommendation systems.
Examples and Case Studies: Successful Applications of Web Scraping in Machine Learning
To showcase the successful applications of web scraping in machine learning, let’s explore a few case studies:
Stock Market Prediction
Web scraping can be used to collect historical stock market data, news articles, and social media sentiment related to specific stocks. By combining this data, machine learning models can predict stock prices and assist investors in making informed decisions.
Social Media Analysis
Scraping social media platforms such as Twitter or Facebook allows you to gather user-generated content and perform sentiment analysis. By analyzing the sentiment of posts or comments, you can gain valuable insights into public opinion and brand perception. Machine learning models trained on this data can help businesses understand customer perception, improve their marketing strategies, or detect emerging trends.
E-commerce Product Recommendation
By scraping product information, customer reviews, and ratings from e-commerce websites, you can build recommendation systems that provide personalized product suggestions to users. This can enhance the user experience and increase sales for e-commerce platforms.
Healthcare Data Analysis
The global AI in the healthcare market was valued at $11.06 billion in 2021 and is expected to reach $187.95 billion by 2030. Web scraping can be used to collect healthcare-related data, such as patient records, medical research papers, or drug interactions. Machine learning models trained on this data can assist healthcare professionals in diagnosing diseases, predicting patient outcomes, or identifying potential drug interactions.
Fraud detection in online marketplaces
Web scraping can be used to collect transaction data from online marketplaces and detect fraudulent activities. By analyzing patterns and anomalies in the scraped data, you can build machine learning models that identify suspicious transactions and protect users from fraud.
Sentiment Analysis
One application of web scraping in machine learning is sentiment analysis. By scraping customer reviews from e-commerce websites or social media platforms, we can train machine learning models to classify sentiments as positive, negative, or neutral. This can provide valuable insights for businesses about customer satisfaction, product feedback, or emerging trends.
Image Recognition
Web scraping can also be utilized for training image recognition models. By scraping images from websites that contain labeled or annotated data, we can create a robust dataset for training machine learning models to recognize specific objects, faces, or scenes. This can be applied in various domains, such as autonomous vehicles, surveillance systems, or creative content generation.
Price Prediction Models for Financial Platforms
Web scraping can be an excellent source of data for building price prediction models. By scraping historical price data from e-commerce websites or financial data, we can train machine learning models to forecast future prices. These models can assist investors, retailers, or consumers in making informed decisions based on market trends and price fluctuations.
Future Trends and Innovations in Web Scraping for Machine Learning
As technology continues to advance, so does the field of web scraping for machine learning.
Natural language processing algorithms
This combination allows extracting valuable insights from large amounts of unstructured text data, like customer reviews or social media comments. By combining web scraping with natural language processing, machine learning models can better understand and analyze human-generated content.
Advanced image recognition techniques in web scraping for machine learning
Machine learning algorithms can be trained to recognize objects, faces, or perform image classification tasks by scraping images from websites. This opens up various applications, including visual search engines and automated surveillance systems.
Conclusion
In conclusion, web scraping is a fundamental tool for acquiring data in machine learning. It enables us to collect diverse and real-world data from websites, which in turn improves the performance and accuracy of machine learning models.
Data scraping plays a vital role in advancing generative AI , contributing significantly to its remarkable development. Prominent AI models such as ChatGPT and LLaMA heavily depend on effective data extraction from online sources. This scraping procedure enriches the models’ language comprehension and generation capabilities by supplying a wide range of diverse and valuable information.
Crawlbase provides data for generative AI models like ChatGPT, PaLM, or Bard at affordable prices. Crawlbase API uses advanced technology to browse websites, gather accurate and reliable information for training AI chatbots such as ChatGPT, Netomi, and more.
Utilizing advanced technology, our API efficiently navigates websites, retrieves pertinent data, and presents it to you in a structured and usable manner.
As technology advances, we can expect web scraping to continue playing a crucial role in the future of machine learning.
FAQs
Is Web Scraping used in Machine Learning?
Yes, web scraping is extensively used in machine learning. The ability to collect large amounts of data from various sources allows us to enrich our training datasets and improve the performance of our models. Machine learning algorithms thrive on diverse and real-world data, and web scraping is a valuable tool for acquiring such data.
Furthermore, web scraping enables us to access the most up-to-date information available on the internet. This is particularly beneficial in dynamic domains, such as news or finance, where real-time data can significantly impact the accuracy of machine learning models.
Is Web scraping useful for Data science?
Yes, web scraping can be extremely useful for data science. It allows data scientists to gather large amounts of data from various online sources quickly and efficiently. This data can then be analyzed, processed, and used to extract valuable insights, train machine learning models, or support decision-making processes in various domains such as finance, e-commerce, healthcare, and more. Web scraping enables data scientists to access real-time, up-to-date information from the web, which can enhance the quality and accuracy of their analyses and predictions. However, it’s important to note that web scraping should be conducted ethically and in compliance with legal regulations and website terms of service.




